


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序


OpenAI近日推出专为智能编程和网络安全任务优化的GPT-5.2-Codex模型,该版本在处理复杂软件工程和漏洞检测方面取得重大突破。
性能表现全面超越前代
在SWE-Bench Pro基准测试中,GPT-5.2-Codex以56.4%的准确率领先于GPT-5.2(55.6%)和GPT-5.1(50.8%)。在Terminal-Bench 2.0测试中,其64.0%的得分同样优于GPT-5.2的62.2%。这些提升源于改进的长上下文处理能力、工具使用效率以及针对长时间编程会话的原生压缩技术。
| 基准测试 | GPT-5.2-Codex | GPT-5.2 | GPT-5.1-Codex-Max |
|---|---|---|---|
| SWE-Bench Pro | 56.4% | 55.6% | 50.8% |
| Terminal-Bench 2.0 | 64.0% | 62.2% | 58.1% |
网络安全能力显著增强
该模型在专业夺旗赛(CTF)挑战中展现出远超前代的能力,支持模糊测试、测试环境搭建和攻击面分析,可显著加速防御工作流程。OpenAI强调,尽管存在技术双用途风险,但根据其准备框架评估,该模型仍保持在"高"网络安全能力阈值之下。
漏洞发现实战案例
研究人员使用前代GPT-5.1-Codex-Max模型在调查React服务器组件漏洞(CVE-2025-55182,CVSS 10.0)时,发现了多个关联漏洞。该高危远程代码执行漏洞已于12月3日修复。
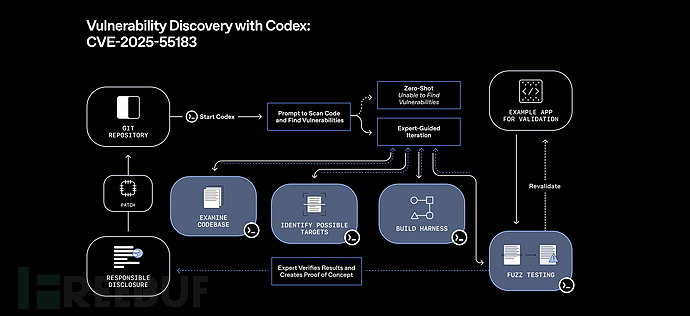
后续发现的漏洞包括:CVE-2025-55183(源代码暴露,CVSS 5.3)、CVE-2025-55184以及CVE-2025-67779(拒绝服务攻击,CVSS 7.5),这些漏洞已于12月11日披露。发现过程涉及迭代提示、本地环境搭建和模糊测试等技术。
产品发布与安全措施
GPT-5.2-Codex现已面向付费ChatGPT Codex用户开放,API访问即将推出。OpenAI还启动了仅限受邀专业人士参与的试点计划,专注于红队演练等防御性任务。公司通过模型安全防护和社区协作机制来遏制潜在滥用行为。
这一技术演进将帮助开发者和安全人员应对代码库和基础设施中日益增长的威胁。React官方已发布补丁,建议用户升级至19.0.3及以上版本。
参考来源:
OpenAI GPT-5.2-Codex Supercharges Agentic Coding and Vulnerability Detection
本文为 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf
客服小蜜蜂(微信:freebee1024)