



官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

前言
GraphQL是一种由Facebook开发的API查询语言,通过声明式数据获取机制实现精准高效的数据交互,现已成为现代前端开发的重要技术方案。
本篇文章来看看GraphQL的实现以及可能存在的安全问题。
GraphQL的优点
GraphQL在前端开发中的应用优势
灵活字段选取
允许前端开发者精准指定所需数据字段,避免REST接口的过度获取或数据不足问题。
GraphQL 的灵活性体现在客户端可以完全自主地决定需要获取的数据结构和字段。这意味着,无论前端应用是一个简单的展示页面,还是一个复杂的单页应用(SPA),都可以根据自身的需求,精确地从服务器获取数据,而无需受到固定数据结构的限制。
减少网络请求
通过单次查询即可获取多层级关联数据,有效解决传统REST接口的多次请求问题。
在传统的 RESTful API 中,为了获取多个相关资源的数据,客户端往往需要多次发起 HTTP 请求。这不仅增加了网络开销,还可能导致页面加载缓慢,影响用户体验。而 GraphQL 通过允许在一次请求中获取多个资源的数据,有效地减少了网络请求次数,提高了数据获取的效率。
强类型校验
内置类型系统支持自动生成文档,提升前后端协作效率。
GraphQL提供了强类型的schema机制,从而天然确保了参数类型的合法性。
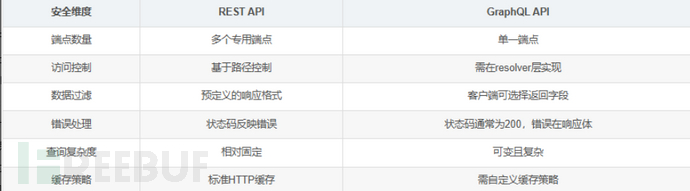
GraphQL与REST安全对比
与传统的 RESTful API 不同,GraphQL 允许客户端精确地请求所需的数据,避免了数据的冗余传输和多次请求的问题。它就像是一个灵活的数据点菜系统,客户端可以根据自己的需求,从服务器这个 “菜单” 中选择特定的数据 “菜品”,而不是像 RESTful API 那样,只能接受固定的 “套餐”。
在传统的 RESTful API 架构中,客户端获取数据时,可能需要向多个不同的端点发送请求。例如,在一个社交媒体应用中,客户端想要获取用户的基本信息(如用户名、头像)以及该用户最近发布的 5 条动态,可能就需要分别向/users/{id}端点获取用户基本信息,再向/posts/user/{id}端点获取用户动态,并且由于 RESTful API 返回的数据结构通常是固定的,客户端可能会获取到一些不需要的数据,造成带宽浪费,或者获取不到某些需要的数据,还得再次请求。
语法详解
查询
在 GraphQL 中,查询是获取数据的主要方式 。查询语句的结构非常直观,它以一个根字段开始,后面跟着需要获取的子字段,就像在 JSON 对象中访问嵌套属性一样。例如,获取文章和评论的信息
{
article(aid:1) {
title
content
author {
uid
name
}
},
comment {
content,
author {
uid
name
}
}
}变更
变更操作主要用于修改服务器上的数据,比如添加、更新和删除数据。它的语法结构与查询类似,但通常会使用mutation关键字来标识这是一个变更操作。
添加数据时,以添加用户为例,假设我们有一个User类型,包含name和email字段:
addUser是自定义的变更操作名称,后面的参数name和email是要添加用户的属性值。返回值部分指定了我们希望在添加用户成功后返回的字段,这里包括新用户的id、name和email。
mutation {
addUser(name: "John Doe", email: "[email protected]") {
id
name
email
}
}更新
这里updateUser是更新操作,id参数指定要更新的用户,email是新的邮箱值。
mutation {
updateUser(id: "1", email: "[email protected]") {
id
name
email
}
}删除
deleteUser操作根据id删除用户,返回值success用于表示删除操作是否成功。
mutation {
deleteUser(id: "1") {
s免责声明
1.一般免责声明:本文所提供的技术信息仅供参考,不构成任何专业建议。读者应根据自身情况谨慎使用且应遵守《中华人民共和国网络安全法》,作者及发布平台不对因使用本文信息而导致的任何直接或间接责任或损失负责。
2. 适用性声明:文中技术内容可能不适用于所有情况或系统,在实际应用前请充分测试和评估。若因使用不当造成的任何问题,相关方不承担责任。
3. 更新声明:技术发展迅速,文章内容可能存在滞后性。读者需自行判断信息的时效性,因依据过时内容产生的后果,作者及发布平台不承担责任。
 已在FreeBuf发表 0 篇文章
已在FreeBuf发表 0 篇文章
本文为 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf
客服小蜜蜂(微信:freebee1024)