文章探讨了网络安全事件的应对策略,强调基于NIST框架的准备、检测与分析、遏制与恢复及事后活动四个阶段的重要性。通过详细阐述每个阶段的具体措施和最佳实践,文章旨在帮助组织提升应对能力,降低事件带来的财务和声誉损失。 2025-12-8 18:0:22 Author: www.vmray.com(查看原文) 阅读量:12 收藏
In today’s threat landscape, the question facing security leaders isn’t whether your organization will experience a cybersecurity incident—it’s how effectively you’ll respond when one occurs. With average breach costs exceeding $4.45 million according to IBM’s latest Cost of a Data Breach Report, and mean time to identify breaches hovering around 204 days, the financial and reputational stakes of incident response have never been higher.
The NIST incident response framework provides a proven methodology that translates security theory into operational excellence. This guide examines each phase of the framework through the lens of enterprise risk management, demonstrating how mature incident response capabilities reduce both the frequency and business impact of security events. For CISOs and security decision-makers, understanding these steps isn’t just about technical proficiency—it’s about building organizational resilience that protects stakeholder value and enables business continuity under adversarial conditions.

Step 1: Preparation
Preparation represents the foundation upon which all incident response capabilities are built. Organizations that invest strategically in this phase demonstrate measurably better outcomes: faster detection times, reduced containment costs, and lower overall business impact from security events.
Define the goals of the preparation stage
Effective preparation requires comprehensive documentation of incident response policies, communication protocols, and asset inventories. This documentation serves as your organization’s incident response constitution—the authoritative reference that guides decision-making when time pressure and uncertainty create chaos. According to NIST SP 800-61r3, organizations with mature documented procedures reduce mean time to respond (MTTR) by up to 40% compared to those relying on ad-hoc processes.
Your incident response policy must define clear criteria for incident classification. Not every security alert constitutes an incident requiring full response protocols. Establishing objective thresholds—based on data sensitivity, system criticality, and potential business impact—enables your team to allocate resources efficiently. Include explicit role definitions with decision-making authority clearly delineated. Which roles can authorize network isolation? Who determines whether law enforcement notification is required? When does an incident escalate to board-level reporting?
Training and simulation exercises differentiate prepared organizations from reactive ones. Regular tabletop exercises expose procedural gaps and develop muscle memory for high-stress scenarios. Design these exercises around realistic attack scenarios that reflect your actual threat profile. If your organization faces nation-state APT activity, simulate multi-stage intrusions with data exfiltration. If ransomware represents your primary risk, test your backup restoration procedures under time constraints that mirror actual extortion timelines.
Recommend proactive security measures
Prevention remains more cost-effective than remediation. Deploy defense-in-depth strategies that include endpoint detection and response (EDR), network segmentation, vulnerability management programs, and identity-based access controls. However, the strategic differentiator lies in centralizing threat intelligence and alert data to create contextual awareness that enables proactive defense.
When threat intelligence feeds integrate with your SIEM, sandbox analysis, and security orchestration platforms, you transform disparate data points into actionable threat intelligence. This integration provides early warning capabilities that can identify attack preparation activities before actual compromise occurs. Your security investments shift from reactive incident response to predictive threat mitigation.
Step 2: Detection & Analysis
Detection identifies potential security incidents while analysis determines their validity and severity. This phase directly impacts your organization’s exposure window—the critical period between initial compromise and effective containment. Reducing this window translates directly to reduced business impact and lower breach costs.

Clarify the process of identifying and validating suspicious activity
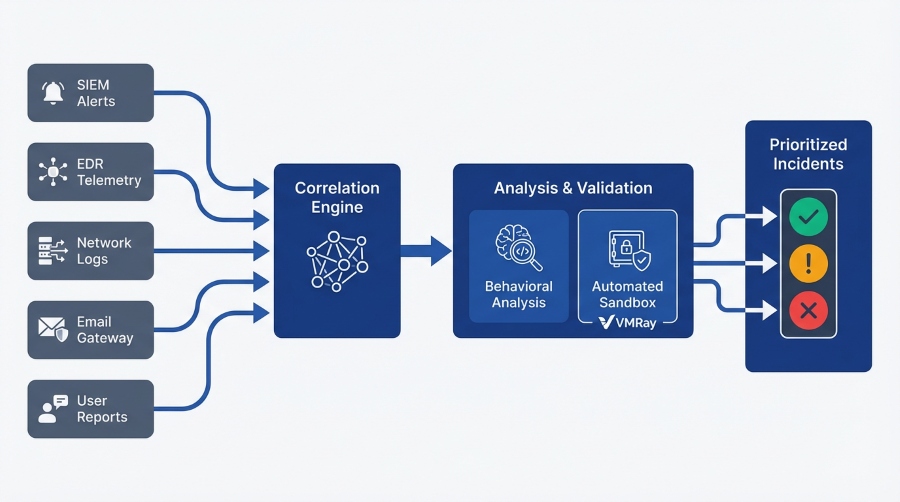
Modern security operations centers process thousands of events daily from diverse sources: network traffic analysis, SIEM correlation rules, EDR behavioral detections, email gateway alerts, and user-reported suspicious activity. The operational challenge isn’t data collection—most organizations suffer from data overabundance rather than scarcity. The real challenge lies in correlation, prioritization, and validation.
Effective detection requires multi-source correlation that reveals attack patterns invisible to individual security tools. Network monitoring might detect unusual DNS queries. Endpoint telemetry could flag suspicious PowerShell execution. Email logs might show successful phishing delivery. When analyzed in isolation, each signal appears innocuous. When correlated temporally and contextually, they reveal a coordinated intrusion.
Analysis validation separates true security incidents from false positives and benign anomalies. Security analysts evaluate indicators of compromise (IOCs), assess behavioral patterns, and determine threat actor intent. This triage process consumes significant analyst capacity—capacity that directly impacts your organization’s ability to respond to genuine threats. Organizations averaging 60+ hours per week on false positive investigation demonstrate 35% longer breach detection times than those with optimized triage workflows.
Improve detection accuracy using advanced analytics
Advanced behavioral analytics and automated threat detection capabilities separate high-fidelity signals from background noise. VMRay FinalVerdict accelerates alert triage by providing automated validation of suspicious files and URLs with clear verdicts backed by comprehensive behavioral analysis. This automation reduces analyst time spent on manual investigation from hours to minutes, enabling your team to focus cognitive resources on complex threat hunting and strategic security initiatives.
When suspicious artifacts require deeper forensic analysis, VMRay DeepResponse provides rapid sandbox detonation that reveals complete attack chains with unprecedented detail. The platform’s hypervisor-based architecture remains invisible to even advanced evasion techniques, capturing network communications, file system modifications, registry changes, and process behaviors that traditional sandboxes miss. This complete visibility provides the evidence required for confident containment decisions and supports accurate impact assessment for stakeholder communication.
Step 3: Containment, Eradication & Recovery
Once incident validation confirms active compromise, operational priorities shift to damage limitation and service restoration. This phase demands both technical precision and business judgment—balancing security imperatives against operational continuity requirements. Decisions made during containment directly impact both immediate incident costs and long-term organizational resilience.
Detail containment strategies for short-term and long-term defense
Containment strategies bifurcate into short-term tactical actions and long-term strategic remediation. Short-term containment focuses on immediate threat suppression: endpoint isolation, account credential revocation, network-level blocking of command-and-control infrastructure, and emergency patching of actively exploited vulnerabilities. These rapid-response actions prevent lateral movement, data exfiltration, and attack expansion while preserving forensic evidence for investigation.
Long-term containment addresses the systemic vulnerabilities that enabled initial compromise. This includes architectural improvements like enhanced network segmentation, implementation of least-privilege access models, deployment of additional monitoring capabilities in previously blind spots, and hardening of compromised systems beyond baseline configurations. The strategic objective extends beyond stopping the current incident—it’s reducing the attack surface to prevent similar compromises in the future.
Throughout containment activities, balance security requirements against business continuity obligations. Complete isolation of critical production systems might achieve perfect containment while simultaneously causing unacceptable business disruption. Work closely with business stakeholders and asset owners to understand operational dependencies and risk tolerances. Sometimes monitored containment—where you isolate the threat while maintaining controlled system functionality—provides optimal risk-reward tradeoff.
Guide teams through eradication and recovery
Eradication removes all adversary presence from compromised environments. This requires thoroughness that borders on paranoia—overlooking a single persistence mechanism means threat actors regain access after you declare the incident resolved. Delete malicious files, remove unauthorized accounts, close backdoors, revoke compromised credentials, and rebuild affected systems from verified clean sources. For critical infrastructure, consider complete system reimaging rather than selective remediation to achieve cryptographic certainty of threat removal.
Recovery restores normal operations while maintaining vigilant monitoring for reinfection indicators. Implement enhanced logging on restored systems. Deploy additional behavioral monitoring. Conduct iterative validation testing to confirm both security posture and functional integrity. According to research from leading incident response firms, comprehensive recovery protocols that include extended monitoring periods reduce reinfection rates by more than 60% compared to organizations that declare recovery immediately after eradication.
During recovery, operationalize intelligence gathered during analysis. Feed IOCs extracted from sandbox detonation into your threat intelligence platform and detection systems. Update SIEM correlation rules based on attack TTPs. Distribute threat intelligence to industry peers through information sharing communities. Transform incident-specific knowledge into durable defensive improvements that benefit your entire security program.
Step 4: Post-Incident Activity
Post-incident activity transforms painful security events into organizational learning and measurable capability improvements. This phase separates mature security programs from those trapped in reactive cycles, responding to incidents without building lasting resilience.
Review lessons-learned processes
Comprehensive documentation captures the complete incident timeline: initial detection methodology, analysis findings, containment decisions and their rationale, eradication steps, recovery actions, and final business impact assessment. This documentation serves multiple critical functions—regulatory compliance evidence, legal proceedings support, insurance claims substantiation, and most importantly, organizational knowledge transfer.
Conduct formal after-action reviews involving all stakeholders who participated in response activities. Include security analysts, system administrators, network engineers, application owners, legal counsel, communications teams, and executive leadership. Cross-functional participation reveals insights that single-team debriefs miss. Network teams might identify monitoring gaps that security didn’t recognize. Business stakeholders could highlight communication breakdowns that delayed critical decisions. Executive leadership may surface strategic concerns about third-party risk or insurance coverage adequacy.
Integrate improvements into future workflows
Convert lessons learned into concrete operational changes. Revise incident response runbooks based on procedural friction points identified during actual response. Update detection rules to identify similar attacks earlier in the kill chain. Modify escalation procedures if communication delays impeded response velocity. Adjust resource allocation if staffing constraints created response bottlenecks.
Feed newly identified indicators and behavioral signatures into your threat intelligence ecosystem. Organizations using VMRay’s platform benefit from automated indicator enrichment that creates continuous improvement cycles—each incident strengthens detection accuracy and response speed for subsequent events. This compounding improvement effect differentiates high-performing security programs from those that repeatedly suffer similar compromises.
NIST Recommendations for Organizing A Computer Security Incident Response Team
CSIRT organizational structure significantly influences response effectiveness, communication efficiency, and overall program maturity. NIST’s Computer Security Incident Handling Guide delineates several proven team models, each optimized for different organizational contexts.
Describe centralized, distributed, and coordinated team models
Centralized CSIRT models consolidate all incident response capabilities within a single unified team serving the entire enterprise. This structure excels at developing deep specialized expertise, maintaining consistent processes across all incidents, and achieving economies of scale for tool investments and training programs. Centralized teams work particularly well for organizations with limited geographic distribution and relatively homogeneous technology environments.
Distributed CSIRT models deploy multiple semi-autonomous teams, typically aligned with business units, geographic regions, or technology domains. Large multinational enterprises with diverse operating environments commonly adopt distributed structures. Each team develops specialized knowledge of their domain while maintaining coordination mechanisms for cross-functional incidents. This model provides local responsiveness and domain expertise at the cost of potentially inconsistent processes and knowledge silos.
Coordinated models synthesize elements of both approaches. A central team establishes enterprise-wide standards, provides specialized capabilities (advanced malware analysis, threat intelligence, forensics), and coordinates response to major incidents. Distributed teams handle routine incidents within their domains while escalating complex cases to central resources. This hybrid structure scales effectively for large organizations requiring both enterprise consistency and local responsiveness.
Clarify when each structure fits
CSIRT structure selection depends on organizational size, geographic distribution, technology complexity, regulatory environment, and security maturity level. Organizations with fewer than 500 employees and single primary locations typically benefit from centralized teams. Large enterprises with 10,000+ employees across multiple continents require distributed or coordinated models to provide adequate coverage without creating unsustainable communication overhead.
Establish explicit role definitions, responsibility matrices, and decision authority frameworks regardless of structural model. Document who possesses authority to isolate critical systems, who approves external communications, who interfaces with law enforcement, and who makes recovery priority decisions. Align these responsibilities with NIST’s incident response lifecycle. For comprehensive guidance on building effective incident response teams, consider both technical capabilities and organizational culture fit—team effectiveness depends as much on collaboration dynamics as technical skill.
Best Practices for Building Your NIST Incident Response Plan
An effective incident response plan operationalizes the NIST framework into executable procedures your team can follow under extreme time pressure and uncertainty. Plans that remain theoretical documents provide minimal value during actual crises.
Outline essential components of a NIST-aligned IR plan
Your incident response plan must include detailed communication protocols specifying information flow pathways during security events. Define who notifies affected customers and under what timelines. Establish law enforcement coordination procedures. Specify external legal counsel engagement criteria. Document regulatory reporting obligations and deadlines. Create stakeholder communication templates that balance transparency with operational security. Pre-established communication frameworks prevent the chaos and misstatements that often compound incident impact.
Develop clear escalation criteria with objective thresholds that trigger different response levels. An isolated endpoint infection requires different handling than a breach affecting customer personally identifiable information. Your escalation procedures should reflect these distinctions with specific criteria: data types involved, number of affected systems, potential business disruption, regulatory implications, and estimated remediation costs. Objective escalation criteria enable consistent decision-making and appropriate resource allocation.
Include comprehensive documentation and evidence collection procedures throughout the incident lifecycle. Maintain detailed activity logs recording who took which actions when, the evidence informing each decision, and the outcomes of response activities. This documentation supports legal proceedings, regulatory investigations, insurance claims, and post-incident analysis. Implement evidence handling procedures that maintain chain of custody for potential forensic use.
Recommend testing and improvement workflows
Validate your incident response plan through regular testing using graduated exercise complexity. Begin with tabletop discussions that walk through response procedures in low-stress environments. Progress to functional exercises that test specific capabilities like backup restoration or emergency communication systems. Conduct full-scale simulations that stress-test your entire response capability under realistic time constraints and decision pressure.
After each exercise and actual incident, systematically update your runbooks incorporating lessons learned. Did analysts struggle with specific tool functions? Add targeted training. Did communication delays slow containment decisions? Revise notification procedures. Did resource constraints create response bottlenecks? Adjust staffing models or tool automation. Your incident response plan should evolve continuously as a living document that improves with each iteration.
Measuring Incident Response Effectiveness: Key Metrics for Security Leaders

Executive leadership and board oversight require objective metrics that quantify incident response performance and demonstrate continuous improvement. Focus on metrics that reflect both operational efficiency and business impact reduction.
Mean Time to Detect (MTTD) measures the interval between initial compromise and detection. Industry benchmarks average 204 days, but high-performing organizations achieve detection within hours or days. Reducing MTTD directly limits adversary dwell time and reduces potential damage. Track MTTD trends over time and by incident category to identify detection capability gaps.
Mean Time to Respond (MTTR) quantifies the period from detection to effective containment. MTTR reflects your team’s operational efficiency and the quality of your response procedures. Organizations with mature automated incident response capabilities demonstrate MTTR reductions of 60-80% compared to manual processes.
Incident recurrence rate tracks how often similar incidents occur, indicating whether your organization learns from security events. High recurrence rates suggest inadequate root cause analysis or poor implementation of corrective actions. Target recurrence rates below 5% for comparable incident types.
False positive ratio measures detection accuracy. While aggressive detection rules identify more threats, they also generate investigation burden that dilutes analyst effectiveness. Optimize for true positive rates above 20% to balance comprehensive detection with sustainable operations.
Conclusion
The NIST incident response framework provides the structural foundation that transforms reactive security operations into proactive risk management capabilities. Organizations that implement these steps systematically demonstrate measurably superior outcomes: faster threat detection, reduced incident impact, lower breach costs, and improved regulatory compliance posture.
Framework effectiveness ultimately depends on the capabilities supporting each phase. Modern threats demand modern solutions—advanced behavioral analysis, automated validation, comprehensive threat intelligence, and seamless tool integration. VMRay’s FinalVerdict and DeepResponse deliver these capabilities at enterprise scale, providing the speed and accuracy that confident decision-making requires. By automating routine analysis while preserving human expertise for complex judgments, these platforms enable security teams to operate at the velocity modern threats demand.
For security leaders evaluating incident response investments, the question isn’t whether to implement NIST’s framework—it’s how effectively you’ll operationalize it. The difference between theoretical frameworks and operational excellence lies in tools, training, and continuous improvement discipline.
Ready to transform your incident response capabilities? Explore VMRay’s platform to discover how automated behavioral analysis and comprehensive threat intelligence can reduce your mean time to respond while improving detection accuracy across every phase of the NIST framework. Or contact our team to discuss how organizations like yours are achieving measurable improvements in incident response performance.
如有侵权请联系:admin#unsafe.sh