DeepSeek发布V3.2及特化版模型,性能接近GPT-5与Gemini-3.0-Pro水平,支持开源免费使用。标准版适合日常任务,特化版专攻高难度推理,在多项国际赛事中夺冠。 2025-12-3 14:16:8 Author: www.iplaysoft.com(查看原文) 阅读量:29 收藏
朋友们,最近国产开源 AI 模型 DeepSeek 又一次扔出了重磅升级了!这次直接发布了两个新的正式版模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。

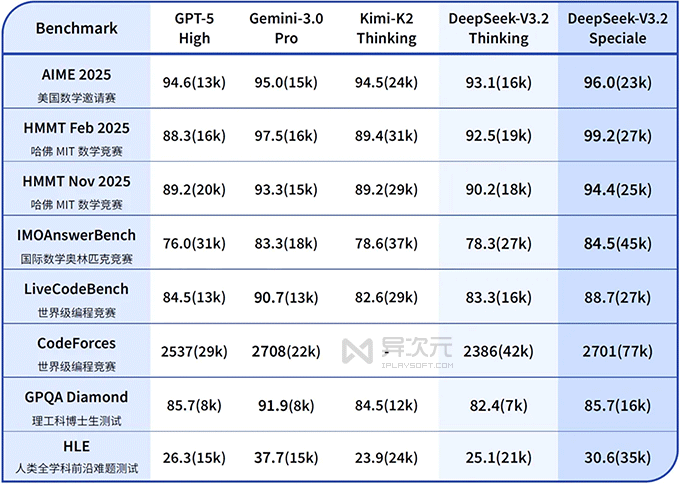
这次发布直接宣告了一件事:开源模型和闭源巨头之间的那道“天堑”,几乎被彻底填平了。 官方直接放话,在公开的推理基准测试中,DS V3.2 的性能已经达到了 GPT-5 的水平,仅仅略低于目前风头正劲的谷歌 Gemini-3.0-Pro。这简直是给整个 AI 行业来了一次“暴击”!
更关键的是,这次 DeepSeek 把最顶尖的技术成果,又一次全部开源了。模型已经同步上传到了 HuggingFace 和 ModelScope 平台,所有个人或公司都可以免费下载、研究和部署。也就是说,之前咱们推荐的「DeepSeek 第三方 API 服务」也都全部可以升级使用最新版本。
DeepSeek v3.2 区分标准版和特别版,满足不同需求!
这次 DeepSeek 发布的两个模型,定位非常清晰,可以说是“一文一武”,覆盖了从日常办公使用到极限探索的所有场景。
DeepSeek-V3.2(标准版):你的日常 AI 全能助手
- 定位:这就是平时在 DeepSeek 官网、App 里直接用的模型,主打一个全能+平衡。
- 能力:官方说它的推理能力对标 GPT-5,而且输出长度比之前的思考模型(比如 Kimi-K2-Thinking)要短得多,这意味着计算成本更低,响应速度更快。它非常适合日常的问答、写作、中低复杂度的编程、分析等通用任务。
- 最大亮点:这是 DeepSeek 家族中第一个将深度思考过程与工具调用彻底打通的模型。
- 适用人群与场景:所有人! 无论是学生、程序员、文案工作者,还是普通的好奇宝宝,用它来处理日常学习和工作中的问题,完全够用,而且免费!
- 解决了什么问题:以前用 AI,要么让它“深度思考”(但慢且不能调用工具),要么让它“调用工具”(但可能缺乏深度规划)。现在,V3.2 可以像人类一样,先规划、再动手、边做边想。比如,你让它“规划一个北京三日游,并查询天气和机票”,它能自己决定先搜索攻略、再查天气、最后比价,整个过程逻辑连贯,有模有样。
DeepSeek-V3.2-Speciale(特化版):探索推理的极限
- 定位:这是一个“研究专用”的超级专家,目标就是把模型的推理能力推到天花板。
- 能力:它在主流推理测试上的表现可以媲美 Gemini-3.0-Pro。但最炸裂的是它的战绩:在 IMO 2025(国际数学奥林匹克)、CMO 2025(中国数学奥林匹克)、ICPC 世界总决赛 和 IOI 2025(国际信息学奥林匹克)这四项顶级赛事中,全部斩获金牌!其中在 ICPC 和 IOI 的测试中,分别达到了人类选手第二名和第十名的水平!这简直是开源模型的“封神”之作。
- 需要注意:这个版本消耗的 Token 量巨大,成本很高,所以目前仅以临时API形式开放,供社区评测和研究,不支持工具调用,而且服务只持续到北京时间 2025年12月15日23:59。它不是为了聊天设计的,而是专攻高难度数学证明和逻辑推理。想体验“最强形态”的朋友,得抓紧时间了。
性能跃升!技术“黑科技”:凭什么能这么强?
根据评测的数据来看,DeepSeek-V3.2 的推理能力已经比得上 OpenAI 的旗舰模型 GPT-5 了!仅仅微小差距略逊于 Google 最新的 Gemini 3.0 Pro。作为一个小版本升级版,这样的成绩称为“傲人”也不为过。
这次性能的飞跃,可不是靠堆参数“大力出奇迹”,而是实打实的架构和训练方法创新。这里挑两个最核心的讲,保证你能听懂。
1. DSA 稀疏注意力:给 AI 装上“闪电索引器”
传统的大模型在处理长文本(比如一整本书)时有个致命弱点:每生成一个新词,它都要回头把前面所有的词再“看”一遍,计算量呈平方级暴增,又慢又贵。
DeepSeek 的 DSA 机制,思路非常巧妙:不是所有历史信息都同等重要,AI 要学会“抓重点”。
- 它是怎么工作的?
- 闪电扫描:模型先用一个极其轻量的“闪电索引器”快速浏览全文,就像我们看书先扫一眼目录和粗体字一样,快速找出哪些内容是关键。
- 精准抓取:基于这个快速判断,只选出最相关的少数几个“关键信息点”。
- 深度计算:最后,只对这些精挑细选出来的重点进行详细的注意力计算。
- 效果有多夸张?
在 128K 的超长上下文场景下:- 推理成本暴降 60%-70%!官方数据,在 H800 集群上,预填充成本从每百万 Token 0.7美元降到0.2美元。
- 推理速度提升约 3.5倍。
- 内存占用减少 70%。
- 最关键的是,性能几乎没有损失!这简直是“花小钱办大事”的典范,直接戳中了商业化的命门。
2. Agent 能力革命:从“嘴炮”到“实干家”
这是本次更新最实用、最让人兴奋的一点!以前的 DeepSeek,深度思考模式和工具调用是“鱼和熊掌不可兼得”。
现在,DeepSeek V3.2 实现了 “思考+工具调用”的深度融合。这意味着模型可以像人类专家一样,在执行多步骤复杂任务时,一边规划,一边动手,还能根据结果调整策略。为了训练出这个能力,DeepSeek 团队搞了个“杀手锏”:大规模智能体任务合成。
但因为高质量、复杂的 Agent 交互数据太稀缺了。DeepSeek 的解决方案非常聪明:让 AI 自己创造训练数据。他们构建了一个自动化流水线,让模型自己:
- 创建虚拟环境(比如一个模拟的旅行预订系统)。
- 生成复杂任务(比如“规划一个兼顾预算、景点和美食的欧洲深度游”)。
- 最关键的一步:再让同一个模型写一段 Python 验证代码。
- 只有当任务能被成功解决并且通过代码验证时,这组数据才会被加入训练集。
最终,他们合成了 1800 多个不同环境 和 85000 多条复杂指令。这就解决了数据荒的问题,让模型能在海量、多样的“模拟实战”中练就一身本领。
所以,你现在可以让 V3.2 去完成这样的任务:“搜索北京今天的气温,把它转换成华氏度,然后调用工具验证你的换算是否正确,最后用一句话告诉我今天适不适合户外活动”。它会自己决定先搜气温,再用计算工具转换,最后用验证工具核对,一气呵成。
实测对比:和 Gemini 3 Pro 打得有来有回
光说不练假把式。根据一些博主的实测,在多项任务中,DeepSeek V3.2 已经能和 Gemini 3 Pro 正面硬刚了。
- 理解与创意:在生成图像提示词的任务中,V3.2 生成的描述更精准、细节更丰富,出来的图科技感和冲击力都更强。
- 代码生成:在生成一个包含可拖拽播放列表、动态波形图、主题切换的网页音乐播放器时,Gemini 3 Pro 在UI美观度和动态效果还原上略胜一筹。但在生成一个销售数据看板时,V3.2 在功能的丰富度和交互便捷性上反而表现更好。
- 复杂交互:在创建太阳系行星环绕动画的 React 项目中,V3.2 提前为用户想到了交互细节(比如点击行星显示信息卡片),组件化结构更完整。
当然,测试也暴露出一些不足,比如在空间想象力、编程的极限能力上,与顶级闭源模型还有细微差距,长文本幻觉问题也尚未完全根治。但别忘了,这只是 V3.2,一个“小版本”迭代。而且,它是开源的。
开源意义与影响:这不仅仅是技术胜利
DeepSeek-V3.2 的发布,又是一个里程碑事件。
- 终结争论:它彻底打破了“开源模型永远落后闭源模型 8 个月”的魔咒。斯坦福2025年的AI报告显示,开源与闭源模型的性能差距已从2024年的8%急剧缩小到1.7%。现在,一个开源模型在核心基准测试上能直接叫板 GPT-5 和 Gemini 3 Pro。性能接近,但成本可能只有对方的三分之一甚至更低。这种“性价比”优势,对任何想要部署 AI 的企业来说,都是无法抗拒的诱惑。
- 路线宣言:这清晰地展示了中美 AI 发展的不同路径。美国巨头倾向于构建封闭的“超级平台”和“硬件铁幕”;而以 DeepSeek 为代表的中国力量,则选择了通过开源构建生态和技术标准。在大家都在谈论“OpenAI 都不 Open 了”的今天,DeepSeek 的坚持更像是一股“清流”。它证明了,通往顶尖AI的道路,不一定只有“闭源”这一条。开放、协作、敏捷的工程化创新,同样能抵达巅峰。
这不仅仅是技术的胜利,更是开源理念和独特创新方法论的一次高光展示。它让全球的开发者、研究者都能站在巨人的肩膀上,这无疑会极大地加速整个 AI 技术的普及和创新。
如何马上体验?
心动不如行动!想试试这个“国货之光”到底有多强?方法超级简单:
- 网页版:直接访问 DeepSeek 官网 ,现在用的就已经是 V3.2 了。
- 官方手机 App:下载 iOS 版、Android 版。
- API 调用:你可以看看这些推荐的 DeepSeek 第三方 API 服务
- 本地部署:模型已在 HuggingFace 和 ModelScope 上开源,采用宽松的 MIT 协议,可以随意下载和使用。
(再次提醒):想体验“四枚金牌”的究极体 V3.2-Speciale 的朋友,需要通过API设置特定的 base_url 来访问,而且体验窗口只开到12月15日哦!
写在最后
从最初一鸣惊人的 DeepSeek-R1,到如今对标顶流的 DeepSeek V3.2,团队一直给人一种“低调实干”的印象。不搞夸张营销,就是埋头攻克一个又一个技术难题。这种“技术宅”的浪漫,反而赢得了无数人的尊重和期待。
这次 V3.2 的发布,无疑让 DeepSeek 再次站到了舞台的中央。它用实力告诉我们:足够强大的 AI,也可以是开放开源的 AI。“平民化的 AI 创作”时代真的到来了。工具已经足够聪明,剩下的,就看你如何用自然的话语,去描述和创造你心中的世界了。这波升级,你准备好了吗?
/ 关注 “异次元软件世界” 微信公众号,获取最新软件推送 /
如本文“对您有用”,欢迎随意打赏异次元,让我们坚持创作!
赞赏一杯咖啡
异次元软件世界、iPcFun.com 网站创始人。
本来名字很酷,但很无辜地被叫成小X,瞬间被萌化了。据说爱软件,爱网络,爱游戏,爱数码,爱科技,各种控,各种宅,不纠结会死星人,不折腾会死星人。此人属虚构,如有雷同,纯属被抄袭……
本文作者
如有侵权请联系:admin#unsafe.sh