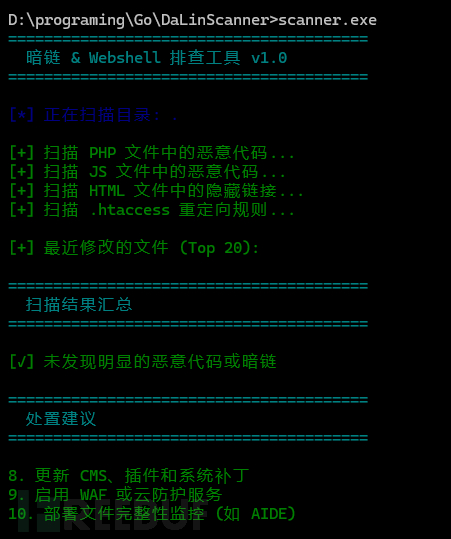
最近在做应急响应的时候,自己撸了个 Go 版本的暗链扫描器,顺便把核心逻辑分享出来,大家可以根据自己的需求改改。这个工具主要解决三个问题:快速扫描文件系统中的恶意代码检测网站是否存在 Cloaking 2025-11-27 07:20:58 Author: www.freebuf.com(查看原文) 阅读量:2 收藏
最近在做应急响应的时候,自己撸了个 Go 版本的暗链扫描器,顺便把核心逻辑分享出来,大家可以根据自己的需求改改。
这个工具主要解决三个问题:
快速扫描文件系统中的恶意代码
检测网站是否存在 Cloaking(选择性跳转)
分析访问日志中的异常重定向
话不多说,开始分析。
一、定义扫描结果结构
首先定义几个基础的数据结构,用来存储扫描结果:
type ScanResult struct {
FilePath string
LineNumber int
MatchedText string
RiskLevel string
Description string
}
type FileInfo struct {
Path string
ModTime time.Time
Size int64
MD5 string
}
ScanResult用来记录每个发现的可疑项,包括文件路径、行号、匹配的内容、风险等级和描述。FileInfo则用来追踪文件的元数据,方便后续做时间线分析。
二、定义检测规则
这是整个工具的核心——检测规则。我整理了几类常见的恶意代码特征:
var (
dangerousFuncs = []string{
`eval\s*\(`,
`base64_decode\s*\(`,
`gzinflate\s*\(`,
`str_rot13\s*\(`,
`create_function\s*\(`,
`assert\s*\(`,
`system\s*\(`,
`shell_exec\s*\(`,
`call_user_func`,
`array_map`,
}
jsPatterns = []string{
`document\.location`,
`window\.location`,
`location\.href`,
`atob\s*\(`,
`fromCharCode`,
}
hiddenLinkPatterns = []string{
`<iframe[^>]*style\s*=\s*["'][^"']*display\s*:\s*none`,
`<iframe[^>]*width\s*=\s*["']0["']`,
`<a[^>]*style\s*=\s*["'][^"']*display\s*:\s*none`,
}
suspiciousDomains = []string{
"casino", "viagra", "porn", "pharma", "lottery",
}
)
这些规则是根据实战经验总结的。PHP 的eval、base64_decode是 webshell 的标配;JS 的location相关函数是跳转的关键;隐藏的 iframe 是暗链的常见形式。
关键点:
使用正则表达式匹配,能覆盖大部分变种
call_user_func和array_map这种回调函数也要盯紧,很多高级 webshell 用这个绕过检测可疑域名列表可以根据实际情况扩展
三、文件扫描核心逻辑
3.1 目录遍历
func scanDirectory(dir string, extensions []string, cutoffTime time.Time) []ScanResult {
var results []ScanResult
err := filepath.Walk(dir, func(path string, info os.FileInfo, err error) error {
if err != nil {
return nil
}
if info.IsDir() {
if strings.Contains(path, "node_modules") ||
strings.Contains(path, ".git") ||
strings.Contains(path, "vendor") {
return filepath.SkipDir
}
return nil
}
ext := strings.ToLower(filepath.Ext(path))
validExt := false
for _, e := range extensions {
if ext == e {
validExt = true
break
}
}
if !validExt {
return nil
}
if !cutoffTime.IsZero() && info.ModTime().Before(cutoffTime) {
return nil
}
fileResults := scanFile(path)
results = append(results, fileResults...)
return nil
})
return results
}
这里用filepath.Walk递归遍历整个目录树。几个优化点:
跳过无关目录:
node_modules、.git这种目录文件巨多,扫描毫无意义,直接 skip扩展名过滤:只扫描指定类型的文件,比如
.php、.js时间过滤:通过
cutoffTime参数可以只扫描最近修改的文件,应急的时候很有用
3.2 单文件扫描
func scanFile(filePath string) []ScanResult {
var results []ScanResult
file, err := os.Open(filePath)
if err != nil {
return results
}
defer file.Close()
scanner := bufio.NewScanner(file)
lineNum := 0
for scanner.Scan() {
lineNum++
line := scanner.Text()
for _, pattern := range dangerousFuncs {
re := regexp.MustCompile(pattern)
if re.MatchString(line) {
results = append(results, ScanResult{
FilePath: filePath,
LineNumber: lineNum,
MatchedText: line,
RiskLevel: "高危",
Description: fmt.Sprintf("检测到危险函数: %s", pattern),
})
}
}
for _, domain := range suspiciousDomains {
if strings.Contains(strings.ToLower(line), domain) {
results = append(results, ScanResult{
FilePath: filePath,
LineNumber: lineNum,
MatchedText: line,
RiskLevel: "中危",
Description: fmt.Sprintf("检测到可疑域名: %s", domain),
})
}
}
hexPattern := regexp.MustCompile(`\\x[0-9a-fA-F]{2}`)
if matches := hexPattern.FindAllString(line, -1); len(matches) > 5 {
results = append(results, ScanResult{
FilePath: filePath,
LineNumber: lineNum,
MatchedText: line,
RiskLevel: "中危",
Description: "检测到大量十六进制编码",
})
}
}
return results
}
逐行扫描文件内容,用正则匹配我们定义的规则。这里有个小技巧:
十六进制编码检测:如果一行代码里出现超过 5 个
\x格式的十六进制字符,基本可以判定是混淆代码。正常代码不会这么写。
四、.htaccess 重定向检测
这是很多人容易忽略的地方。攻击者喜欢在.htaccess里植入重定向规则,因为这样不需要修改 PHP 代码:
func scanHtaccess(dir string) []ScanResult {
var results []ScanResult
err := filepath.Walk(dir, func(path string, info os.FileInfo, err error) error {
if err != nil {
return nil
}
if info.IsDir() {
return nil
}
if filepath.Base(path) != ".htaccess" {
return nil
}
file, err := os.Open(path)
if err != nil {
return nil
}
defer file.Close()
scanner := bufio.NewScanner(file)
lineNum := 0
for scanner.Scan() {
lineNum++
line := scanner.Text()
if strings.Contains(line, "RewriteRule") ||
strings.Contains(line, "Redirect") {
results = append(results, ScanResult{
FilePath: path,
LineNumber: lineNum,
MatchedText: line,
RiskLevel: "中危",
Description: "检测到重定向规则",
})
}
if strings.Contains(line, "HTTP_USER_AGENT") ||
strings.Contains(line, "HTTP_REFERER") {
results = append(results, ScanResult{
FilePath: path,
LineNumber: lineNum,
MatchedText: line,
RiskLevel: "高危",
Description: "检测到 UA/Referer 条件判断",
})
}
}
return nil
})
return results
}
重点关注两类规则:
普通的 RewriteRule/Redirect:可能是正常的,但需要人工核查
基于 UA 或 Referer 的条件判断:这就是 Cloaking 的典型特征,直接标记为高危
五、Cloaking 检测
Cloaking 是指网站根据访客的 User-Agent 返回不同内容。攻击者用这个技术对搜索引擎爬虫显示正常页面,对真实用户显示恶意跳转。
func checkCloaking(url string) {
userAgents := []string{
"Mozilla/5.0 (Windows NT 10.0; Win64; x64)",
"Googlebot/2.1 (+http://www.google.com/bot.html)",
"Baiduspider/2.0",
"Mozilla/5.0 (compatible; Bingbot/2.0)",
}
for _, ua := range userAgents {
client := &http.Client{
CheckRedirect: func(req *http.Request, via []*http.Request) error {
return http.ErrUseLastResponse
},
Timeout: 10 * time.Second,
}
req, err := http.NewRequest("GET", url, nil)
if err != nil {
continue
}
req.Header.Set("User-Agent", ua)
resp, err := client.Do(req)
if err != nil {
fmt.Printf("%-50s ERROR: %s\n", ua, err.Error())
continue
}
defer resp.Body.Close()
location := resp.Header.Get("Location")
fmt.Printf("%-50s %d %s\n", ua, resp.StatusCode, location)
}
}
核心思路:用不同的 User-Agent 请求同一个 URL,对比返回的状态码和跳转地址。
关键点:
CheckRedirect设置为返回http.ErrUseLastResponse,这样不会自动跟随重定向,能看到第一跳的目标如果普通浏览器返回 302 跳转,但 Googlebot 返回 200 正常页面,基本可以确认存在 Cloaking
六、日志分析
访问日志能告诉我们很多信息,特别是异常的重定向:
func analyzeAccessLog(logFile string) {
file, err := os.Open(logFile)
if err != nil {
fmt.Printf("无法打开日志: %v\n", err)
return
}
defer file.Close()
redirects := make(map[string]int)
scanner := bufio.NewScanner(file)
for scanner.Scan() {
line := scanner.Text()
if strings.Contains(line, " 302 ") ||
strings.Contains(line, " 301 ") ||
strings.Contains(line, " 307 ") {
parts := strings.Fields(line)
if len(parts) > 0 {
redirects[parts[0]]++
}
}
}
type kv struct {
Key string
Value int
}
var sorted []kv
for k, v := range redirects {
sorted = append(sorted, kv{k, v})
}
sort.Slice(sorted, func(i, j int) bool {
return sorted[i].Value > sorted[j].Value
})
for i, kv := range sorted {
if i >= 10 {
break
}
fmt.Printf("%s: %d 次重定向\n", kv.Key, kv.Value)
}
}
这个函数很简单:找出日志中所有 302/301/307 状态码的请求,统计每个 IP 产生了多少次重定向,然后排序输出 Top 10。
如果某个 IP 短时间内产生大量重定向,很可能就是被植入了恶意跳转。
七、文件时间线追踪
应急响应的时候,最关心的是"最近谁动了我的文件":
func listRecentFiles(dir string, limit int) {
var files []FileInfo
filepath.Walk(dir, func(path string, info os.FileInfo, err error) error {
if err != nil || info.IsDir() {
return nil
}
ext := strings.ToLower(filepath.Ext(path))
if ext == ".php" || ext == ".js" || ext == ".html" {
md5sum := calculateMD5(path)
files = append(files, FileInfo{
Path: path,
ModTime: info.ModTime(),
Size: info.Size(),
MD5: md5sum,
})
}
return nil
})
sort.Slice(files, func(i, j int) bool {
return files[i].ModTime.After(files[j].ModTime)
})
for i, f := range files {
if i >= limit {
break
}
fmt.Printf("%s | %s | %d bytes | MD5: %s\n",
f.ModTime.Format("2006-01-02 15:04:05"),
f.Path,
f.Size,
f.MD5[:16])
}
}
func calculateMD5(filePath string) string {
file, err := os.Open(filePath)
if err != nil {
return "error"
}
defer file.Close()
hash := md5.New()
io.Copy(hash, file)
return hex.EncodeToString(hash.Sum(nil))
}
收集所有 PHP/JS/HTML 文件,按修改时间倒序排列,同时计算 MD5 值。MD5 可以用来和干净的备份对比,快速发现被篡改的文件。
八、主函数串联
func main() {
targetDir := flag.String("dir", ".", "扫描目录")
urlCheck := flag.String("url", "", "检测 URL")
logFile := flag.String("log", "", "日志文件")
outputFile := flag.String("output", "", "输出文件")
scanRecent := flag.Int("recent", 0, "只扫描最近 N 天")
flag.Parse()
var results []ScanResult
if *urlCheck != "" {
fmt.Println("[*] URL Cloaking 检测")
checkCloaking(*urlCheck)
}
if *logFile != "" {
fmt.Println("[*] 日志分析")
analyzeAccessLog(*logFile)
}
fmt.Println("[*] 文件扫描")
cutoffTime := time.Time{}
if *scanRecent > 0 {
cutoffTime = time.Now().AddDate(0, 0, -*scanRecent)
}
phpResults := scanDirectory(*targetDir, []string{".php"}, cutoffTime)
results = append(results, phpResults...)
jsResults := scanJSFiles(*targetDir, cutoffTime)
results = append(results, jsResults...)
htmlResults := scanHTMLFiles(*targetDir, cutoffTime)
results = append(results, htmlResults...)
htaccessResults := scanHtaccess(*targetDir)
results = append(results, htaccessResults...)
if len(results) == 0 {
fmt.Println("未发现可疑项")
} else {
sort.Slice(results, func(i, j int) bool {
priority := map[string]int{"高危": 3, "中危": 2, "低危": 1}
return priority[results[i].RiskLevel] > priority[results[j].RiskLevel]
})
for _, result := range results {
fmt.Printf("[%s] %s:%d\n %s\n %s\n\n",
result.RiskLevel,
result.FilePath,
result.LineNumber,
truncate(result.MatchedText, 80),
result.Description)
}
}
listRecentFiles(*targetDir, 20)
}
用flag包处理命令行参数,支持多种扫描模式的组合。最后按风险等级排序输出结果,高危的优先展示。
九、GUI 界面(可选)
如果你需要一个图形界面,可以用 Fyne 框架快速搞定。核心就是把命令行参数转换成表单输入:
// 主界面布局
tabs := container.NewAppTabs(
container.NewTabItem("文件扫描", makeFileScanTab()),
container.NewTabItem("URL 检测", makeURLCheckTab()),
container.NewTabItem("日志分析", makeLogAnalysisTab()),
container.NewTabItem("快速扫描", makeQuickScanTab()),
)
// 扫描按钮点击事件
scanBtn.OnTapped = func() {
go func() {
cmd := exec.Command("scanner", "-dir", dirEntry.Text)
output, _ := cmd.CombinedOutput()
resultText.SetText(string(output))
}()
}
GUI 的好处是对新手友好,不用记命令行参数。但实际应急响应的时候,命令行版本更高效。
编译 GUI 版本:
go get fyne.io/fyne/v2
go build -ldflags -H=windowsgui -o scanner-gui.exe gui.go
使用示例
基础扫描:
./scanner -dir /var/www/html
只扫描最近 7 天修改的文件:
./scanner -dir /var/www/html -recent 7
检测 URL Cloaking:
./scanner -url https://example.com
全面扫描并保存结果:
./scanner -dir /var/www/html -url https://example.com -log /var/log/nginx/access.log -output report.txt
总结
这个工具的核心思路就是:
规则驱动:把常见的恶意特征总结成正则规则
多维度检测:文件、URL、日志三管齐下
时间线分析:关注最近的变化
风险分级:高中低三档,方便优先级处理
实际使用中,可以根据自己的业务场景调整规则库。比如你们公司用了某个特殊的 CMS,可以加一些针对性的检测规则。
最后提醒一句:这个工具只能帮你快速定位可疑点,真正的应急响应还是要靠人工分析。别看到一堆"高危"就慌,冷静看看具体内容,很多可能是误报。
好了,去扫你的站吧!
如有侵权请联系:admin#unsafe.sh