IntroductionThis blog serves as a detailed methodology guide for analyzing, reversing, and researchi 2025-11-26 21:39:44 Author: projectdiscovery.io(查看原文) 阅读量:33 收藏
Introduction
This blog serves as a detailed methodology guide for analyzing, reversing, and researching web vulnerabilities, particularly those with CVEs assigned. The content outlines repeatable processes used to evaluate vague advisories, analyze vulnerable software, and ultimately recreate or validate security flaws. The objective is to establish a structured, replicable approach to web vulnerability research.
Environment & Tools
When approaching a new target for CVE research or reverse-engineering, the first priority is to understand the underlying technology stack and deployment environment. Identifying whether the application is built on Java, .NET, Node.js, Python, PHP, or other platforms informs not only the toolchain but also the debugging and analysis techniques used throughout the process.
In most cases, research begins by attempting to obtain a local or testable copy of the vulnerable software. Open-source targets are relatively straightforward to work with, as older releases are typically archived and can be easily instrumented. However, enterprise-grade or closed-source software often presents greater challenges, especially when older, vulnerable versions are no longer publicly distributed. In such cases, secondary sources like vendor documentation, user forums, changelogs, CVE writeups, and third-party blogs can be invaluable. These often contain installation steps, version numbers, or configuration details that aid in replicating the target environment accurately.
Language-Specific Debugging Environments
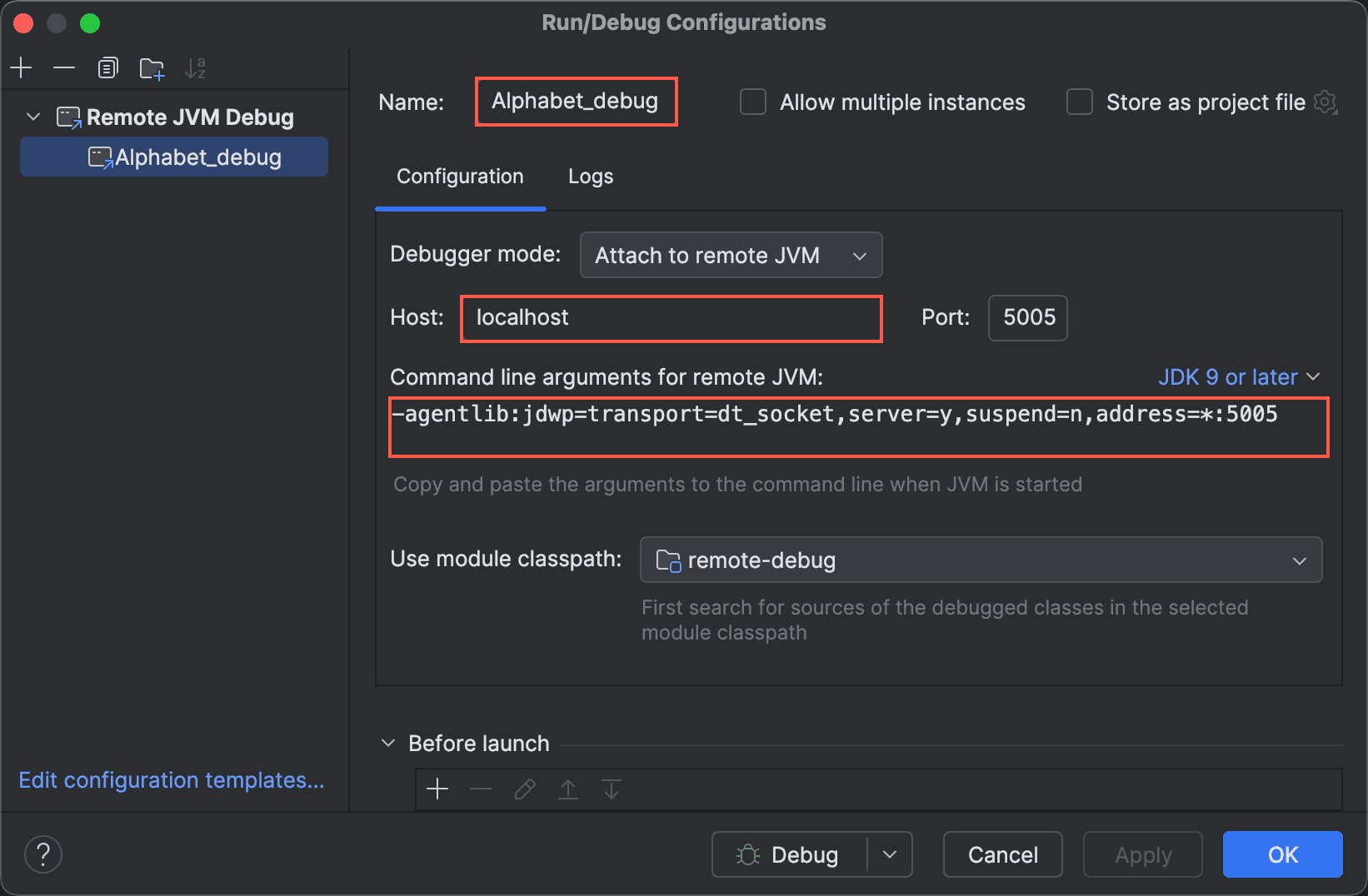
For applications written in Java, remote debugging via the JVM is frequently leveraged. By enabling the -agentlib:jdwp flag during application startup, Java processes can be attached to a debugger such as IntelliJ IDEA Ultimate using the appropriate remote debugging configuration. This allows for inspection of runtime variables, stepping through controller logic, and understanding data flow, particularly helpful when analyzing N-days.
- Identify where the Java application is started from, many times it would be using tomcat server and
catalina.shwould be used, u can add flag such as-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005toJAVA_OPTSenvironment variables and run the server again, this starts the debug server along with the application server. - Similarly, sometimes it would be straight forward java CLI that runs the application server, in that case as well you can run the command on your own add the same flag to start debug server.
Configuring Remote JVM Debug in IntelliJ IDEA
- Add all relevant JAR files
- To be able to debug Java application and their associated JAR files, in the IntelliJ IDEA, go to File > Project Structure > Libraries > click "+" and all the JAR files. Notice, these JAR files are now visible under "External libraries" in the left panel.
- Configuring Debug Configuration
- Click "Debug icon" -> add new configuration -> "Remote JVM debug" -> "Debug"

- Set breakpoints on controllers, filters, deserializers, and template renderers.
- Use Evaluate Expression on request objects to view parsed parameters, cookies, and headers.
.NET applications can be debugged effectively using tools like JetBrains dotPeek (for decompilation and dynamic analysis). With the proper symbol paths and local testbed, it’s possible to attach to running processes and debug both .NET Core and Framework-based services. For reverse-engineering scenarios where source is unavailable, dotPeek or ILSpy can reconstruct high-level code from binaries, enabling code-level reasoning about potential flaws.
For JavaScript/Node.js applications, VS Code with the official Node.js debugging extension is generally sufficient. Breakpoints can be attached to API logic, middleware, or templating logic to observe request processing in real time.
PHP applications can be instrumented using Xdebug with VS Code or PHPStorm. This is especially useful for inspecting execution flows through vulnerable routing logic or unvalidated user inputs, which is common in legacy PHP applications.
Tooling Considerations
- Decompilers
- For Java applications, use IntelliJ IDEA for debuging and CFR, FernFlower, or Procyon for jar decompilation. IDEA will also automatically decompile jars for you.
- For .NET decompiling and debugging, use ILSpy, dotPeek, or actively maintained dnSpyEx for interactive browse, search, and patch diff view.
- Patch diffing
- Git can be used for patch diffing if the source code is available
- You can use VS code extensions as such as compare folders etc.
- Even IntelliJ IDEA offers compare folder which also supports JAR decompiling on the fly.
CVE Reversing Methodology
Prioritizing CVEs: Promising CVEs are those that describe preauth remote attack, low complexity, no user interaction, default configuration, and edge facing components, with extra weight for vendor hotfixes or mentions of header trust, serialization, templating, or path normalization. Priority goes to preauth RCE and clear auth bypass, while info disclosure rises only when leaks yield tokens secrets or configuration that enable lateral movement or privilege escalation. Impact is judged by reachability in common deployments, exploitability of defaults, few required steps, feasibility of a safe deterministic proof, and signals like clean patch diffs, simple stable triggers, weak proxy or webhook trust boundaries, and recurring bug shapes in the product family.
When reversing a CVE you have two main workflows depending on what’s available:
- Hotfix/patch bundle available.
- Only releases available - recreate pre-patch and post-patch trees and diff them.
High-level strategy
If a vendor hotfix or patch diff is provided, start there, it points directly to the changed code and often explains the vulnerability and mitigation.
If no hotfix is available, get the closest vulnerable version and the closest patched version (prefer adjacent releases so diffs are small). Decompile or unpack both, create a git repo containing the vulnerable tree, apply the patched files on top, and use git diff to see exactly what changed. The diff is your roadmap to the vulnerable code paths, inputs, and the intended fix.
For example - download the vulnerable release and the patched release (choose nearest versions).
- Prepare decompiled/source trees
- Create a git repo for diffing
- Focus On:
- Input validation changes (sanitizers removed or added).
- New checks (null checks, whitelist/blacklist logic, signature verification).
- Callsite changes (where the insecure function is used).
- New or removed helper functions.
Examples:
- Zimbra CVE-2024-45519: Our analysis shows patch-to-exploit reasoning, understand the guard that changed, then recreate the pre-patch condition to reach command execution.
- Ivanti EPMM CVE-2025-4427/4428: published detection alongside analysis; patch details anchor the exact conditions the template keys on.
- Versa CVE-2025-34027: Path decoding inconsistencies turn "denied" into "allowed" if normalization happens after authorization. The API path-based bypass demonstrates this shape.
Proof of Concept Writing
After a CVE is reversed and reproduced, the next task is to pin down the smallest trigger that flips the vulnerable branch and wrap it in a safe, repeatable proof. The PoC should be version-pinned, side-effect free, and tied to a single observable marker. Breakpoints or logpoints confirm the exact code path. A fixed build acts as the negative control.
From trigger to template
- Choose a safe proof: Prefer read-only signals over state changes: a distinctive response key from an internal endpoint, a harmless file marker for traversal, or a deterministic delay for blind classes.
- Encode in Nuclei: Use minimal raw requests. Pair at least one unique body marker with a status code, response body matcher or use a dsl duration check for timing classes. Set stop-at-first-match: true, and avoid write actions by default.
- Validate: Test against multiple vulnerable versions and at least one fixed build. Note required headers, redirect behavior, and any proxy/CDN effects.
- Harden: Fail fast on redirects, constrain timeouts, and document assumptions inline. Provide a second safe variant for platform differences (e.g., Linux vs. Windows paths) instead of broad, fuzzy payloads.
Choose undeniable yet reversible proofs: write a file into a sandboxed directory, hit a privileged read-only endpoint, or trigger an inert command. Re-run the same request on the fixed build to show the effect disappears for the right reason.
Knowledge Organization
Good research lives or dies on organization. Keep everything that explains what you tried, why you tried it, and what changed in one place. A predictable folder structure, small disciplined notes, and a few tooling rules make findings reproducible months later and shareable across the team.
Create a case folder per CVE or per vendor bug class. Inside, keep a short lab-notes.md that evolves with the investigation, a lab/ directory with container files and debugger configs, a requests/ directory with Burp exports or raw HTTP, a diffs/ directory with decompiled old vs new builds, and a detections/ directory with the Nuclei template and validation logs. Commit small artifacts to Git normally and use Git LFS for large binaries or decompiler trees so history remains fast to clone.
Always record the small quirks you notice during research - odd error messages, unusual timing, unexpected config defaults, or any primitive that feels out of place. These tiny observations often don’t make sense in the moment but can become critical later: when you revisit a target with fresh context (weeks or months later) those stray notes frequently unlock new angles or chains. For example, the Lucee research described in the ProjectDiscovery blog began from seemingly small issues and behaviors noted two months earlier; once the team re-examined those notes with new insight, they were able to convert those quirks into a pre-auth RCE.
Practice Makes Pattern
Vulnerability research is pattern recognition built through repetition. Pick a disclosed CVE, rebuild the environment, trace from patch to primitive, then search for similar patterns in adjacent code. Document what doesn't work - those notes become critical when you revisit targets with fresh context months later.
The field needs researchers willing to harden detection templates, validate across platform differences, and share detailed reproduction cases. Your next finding is waiting in an error message you glossed over or a feature interaction no one thought to test.
Keep your tools sharp, your notes organized, and your curiosity intact. Now go break something safely and share what you learn.
如有侵权请联系:admin#unsafe.sh