Cloudflare is investigating an outage affecting its global network services, with users enc 2025-11-18 13:0:24 Author: www.bleepingcomputer.com(查看原文) 阅读量:2 收藏

Cloudflare is investigating an outage affecting its global network services, with users encountering "internal server error" messages when attempting to access affected websites and online platforms.
Cloudflare's Global Network is a distributed infrastructure of servers and data centers located in over 330 cities across more than 120 countries, delivering content delivery, security, and performance optimization services.
It has 449 Tbps global network edge capacity and connects Cloudflare to over 13,000 networks, including every major ISP, cloud provider, and enterprise worldwide.

The Internet infrastructure firm first acknowledged these ongoing issues just over 40 minutes ago, reporting that its support portal was experiencing availability issues.
Less than half an hour later, at 11:48 UTC, it added a new incident report warning customers that the Cloudflare Global Network was also experiencing problems.
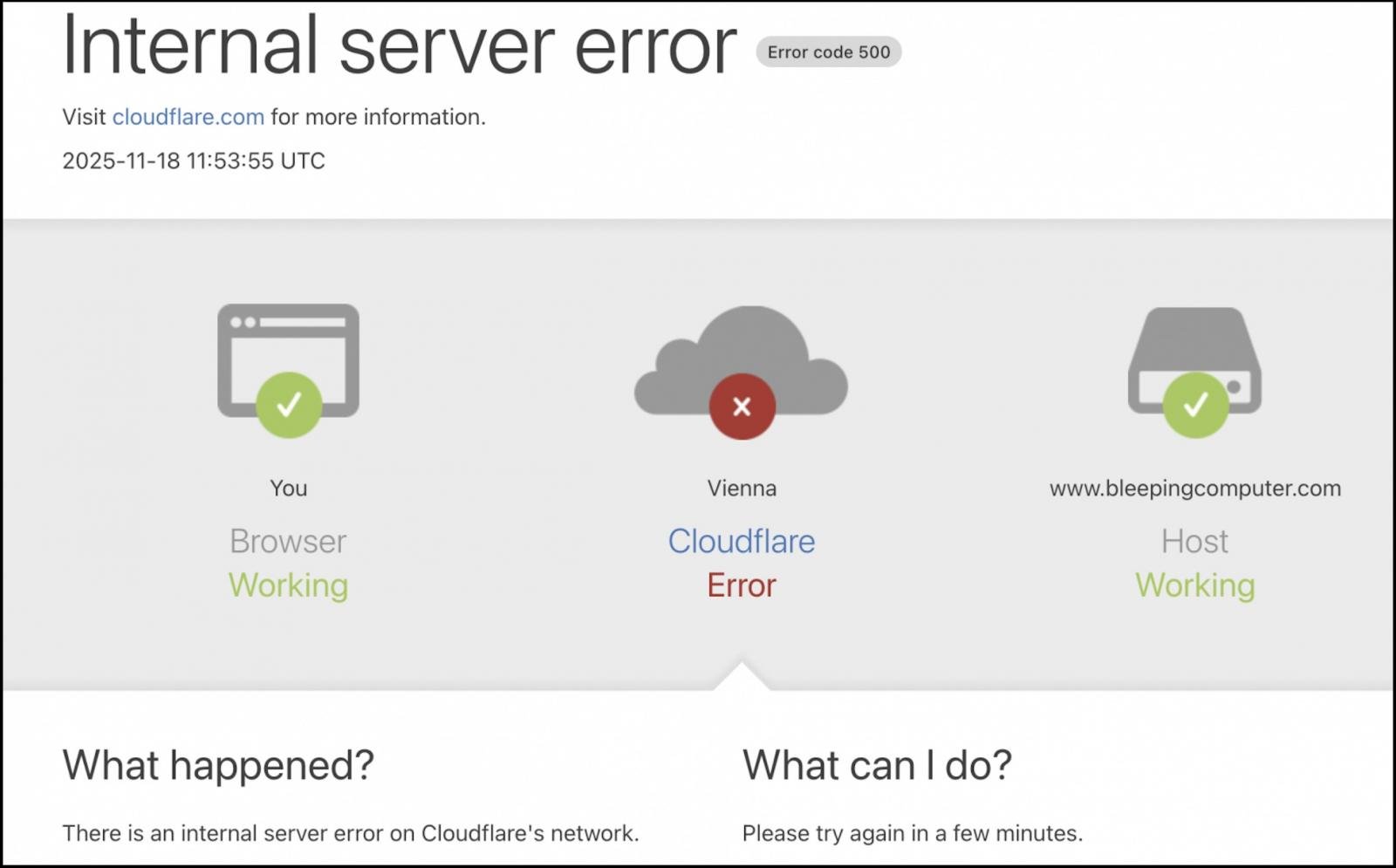
"Cloudflare is aware of, and investigating an issue which impacts multiple customers: Widespread 500 errors, Cloudflare Dashboard and API also failing," the company said. "We are working to understand the full impact and mitigate this problem. More updates to follow shortly."
While Cloudflare has yet to share more information on the extent of this incident, in BleepingComputer's tests, Cloudflare nodes across Europe are currently down, including those in Bucharest, Zurich, Warsaw, Oslo, Amsterdam, Berlin, Frankfurt, Vienna, Stockholm, and Hamburg.
Outage monitoring service Downdetector has also received tens of thousands of reports since the outage began, with impacted users experiencing issues with server connections, websites, and hosting.
While not necessarily related to this ongoing outage, hundreds of thousands of other Downdetector users have also reported issues when attempting to use and connect to various online services, including Spotify, Twitter, OpenAI, League of Legends, Valorant, AWS, and Google.
The company mitigated another massive outage in June that caused Zero Trust WARP connectivity issues and Access authentication failures across multiple regions, and also took down Google Cloud infrastructure.
In October, Cloudflare also addressed an outage caused by a major DNS failure that disrupted connectivity to millions of websites and online platforms on its Amazon Web Services (AWS) cloud computing platform.
Update November 18, 12:21 UTC: Cloudflare is now seeing some signs of recovery.
"We are seeing services recover, but customers may continue to observe higher-than-normal error rates as we continue remediation efforts," it said.
Update November 18, 13:13 UTC: In a new update, Cloudflare states that some services have been restored, while it continues to work on the remaining ones.
"We have made changes that have allowed Cloudflare Access and WARP to recover. Error levels for Access and WARP users have returned to pre-incident rates. We have re-enabled WARP access in London," it said.
"We are continuing working on restoring service for application services customers."
Update November 18, 17:44 UTC: Six hours into the outage, Cloudflare says all issues have been resolved.
"Cloudflare services are currently operating normally. We are no longer observing elevated errors or latency across the network," it noted.
"Our engineering teams continue to closely monitor the platform and perform a deeper investigation into the earlier disruption, but no configuration changes are being made at this time."

The 2026 CISO Budget Benchmark
It's budget season! Over 300 CISOs and security leaders have shared how they're planning, spending, and prioritizing for the year ahead. This report compiles their insights, allowing readers to benchmark strategies, identify emerging trends, and compare their priorities as they head into 2026.
Learn how top leaders are turning investment into measurable impact.
如有侵权请联系:admin#unsafe.sh