引言本文主要讲解Web缓存欺骗漏洞,帮助初学者理解Web缓存欺骗漏洞,从0到1,大家认真学习,共勉~目录1.漏洞决定性条件2.缓存漏洞的基础理解3.缓存漏洞的攻击路径与方式4.缓存漏洞攻击详解5.缓存 2025-11-11 07:57:18 Author: www.freebuf.com(查看原文) 阅读量:1 收藏
引言
本文主要讲解Web缓存欺骗漏洞,帮助初学者理解Web缓存欺骗漏洞,从0到1,大家认真学习,共勉~
目录
1.漏洞决定性条件
2.缓存漏洞的基础理解
3.缓存漏洞的攻击路径与方式
4.缓存漏洞攻击详解
5.缓存漏洞攻击各种姿势扩展
6.实战案例
7.自动化扩展
8.总结
9.免责声明
漏洞决定性条件
1.响应能够被缓存
2.寻找缓存规则
3.利用缓存规则去缓存身份信息
缓存漏洞的基础理解
我们可以将一个网站的服务器分为:源服务器和缓存服务器
源服务器,
也就是我们向网站的一些常见请求:登录框的登录,找回密码,身份令牌下发,个人账号信息等。
而缓存服务器,
是我们向网站的静态请求,这类请求往往是同质化的,不管是用户A还是用户B C D E,所请求东西都是一样的,例如:网站的图片(jepg、jpg、png)、js文件、css文件。这些请求的特点就是一成不变的,不管是谁,请求的响应都是那张图片、那篇文章。所以这类请求,往往会被存放在缓存服务器,也就是提前做好的预制菜,只要用户一请求,就能端上桌。对于网站来说,这能大大的增加网站的运行流畅度,对于用户来说,可以大大的提升浏览网站的网速。
知道什么是缓存服务器和源服务器后,还有一个问题,那就是缓存规则:
缓存规则决定可以缓存什么以及缓存多长时间。缓存规则通常设置为存储静态资源,这些资源通常不会频繁更改,并在多个页面中重复使用。动态内容不会被缓存,因为它更有可能包含敏感信息,确保用户直接从服务器获取最新数据。
那么一些常见的缓存规则有:
静态文件扩展名规则
- 这些规则匹配请求资源的文件扩展名,例如.css用于样式表或.js用于JavaScript文件。
静态目录规则
- 这些规则匹配以特定前缀开头的所有URL路径。这些通常用于针对只包含静态资源的特定目录,例如 /static 或/assets。
文件名规则
- 这些规则匹配特定文件名,以针对对网页操作普遍必需且很少更改的文件,例如 robots.txt 和 favicon.ico。
以上的规则只是常见、常见、常见。因为这种规则是可以自定义的,网站的开发者可以随心所欲的设置缓存规则,所以在挖掘的过程中,我们要首先探测出,网站的缓存规则,否则缓存漏洞就无从说起。
缓存漏洞的攻击路径与方式
那么多东西,我们要怎么学习?很简单,需要关注两样东西即可
1.缓存的规则
2.存储敏感信息的端点(路径)
首先说如果探测出缓存规则。比如关注支持GET HEAD这类请求的响应,排除POST这类请求的响应。因为POST这类会改变服务器状态(增删改查)的响应往往不会被缓存,一是敏感信息安全保护,二是这类信息即时性强,要时刻更新给用户。然后观察源服务器和缓存服务器在解析URL路径、处理分隔符上的差异。最后,构构建一个利用该差异来欺骗缓存存储动态响应的payload(恶意完整URL),发送给受害者,当受害者点击该URL时,他们的响应会被存储在缓存中。使用Burp,你可以向相同的URL发送请求以获取包含受害者数据的缓存响应。
注意:避免直接在浏览器中这样做,因为某些应用程序在没有会话的情况下重定向用户或使本地数据失效,导致你以为攻击失败。
这个攻击路径看不懂没有关系,跟着往下走,就能明白到底是什么意思了。
缓存漏洞攻击详解
一、响应包被缓存的证据
我们前面说需要观察响应包,为什么呢,因为响应包有一些可以表明该响应是缓存的证据!!!
在测试过程中,能够识别缓存响应至关重要。为此,请查看响应头和响应时间。
例如:
X-Cache 头部提供了关于响应是否从缓存中提供的信息。
典型值包括:
X-Cache: hit
- 响应是从缓存中提供的。
X-Cache: miss
- 缓存中没有请求键的响应,因此从源服务器获取。在大多数情况下,然后缓存该响应。要确认这一点,请再次发送请求,看看值是否更新为 hit。
X-Cache: dynamic
- 源服务器动态生成了内容。通常这意味着响应不适合缓存。
X-Cache: refresh
- 缓存的内容已过时,需要刷新或重新验证。
如何判断响应被缓存,发送到Repeater(重放器里),连点两次发送即可,如果X-Cache: miss 更新为hit 则代表该响应被缓存: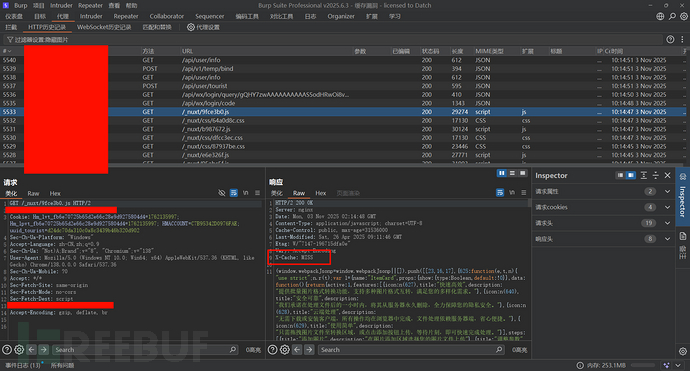
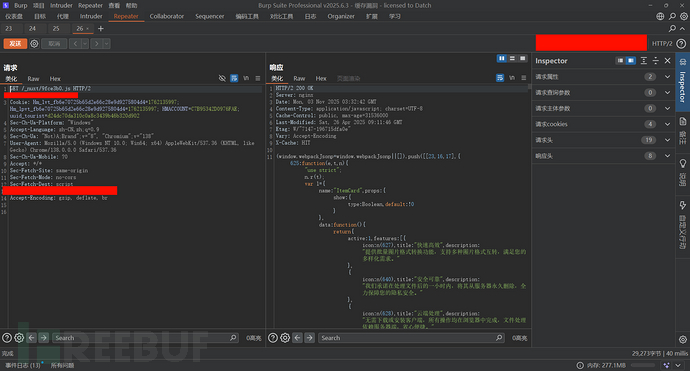
又比如:
Cache-Control 头部可能包含指示缓存的指令
典型值包括:
带有大于 0 的 max-age 的 public。请注意,这仅表明资源是可缓存的。它并不总是表明缓存,因为缓存有时会覆盖此头部。如
值得注意的是,表明响应被缓存的标头不只是以上的两个,这里只是介绍了这两个。所以如果想深入了解的话,需要自己去进行学习。更有意思的是,这类标头并不是http必要的标头,所以你需要跟网站的开发者进行博弈,网站开发者隐藏了这类标头,你就要寻找这个响应被缓存的其他证据~~~
二、关于URL路径的资源映射
URL路径映射是指将URL路径与服务器上的资源(例如文件、脚本或命令执行)展示的过程。不同的框架和技术使用多种不同的映射样式。两种常见的样式是传统URL映射和RESTful URL映射。
传统URL映射表示直接指向文件系统上资源的路径。这里是一个典型的例子:
http://example.com/path/in/filesystem/resource.html
http://example.com指向服务器。
/path/in/filesystem/ 表示服务器文件系统中的目录路径。
resource.html 是正在访问的特定文件。
相比之下,REST风格的URL不直接匹配物理文件结构。它们将文件路径抽象为API的逻辑部分:
http://example.com/path/resource/param1/param2
http://example.com指向服务器。
/path/resource/ 是代表资源的端点。
param1 和 param2 是服务器用于处理请求的路径参数。
值得注意的是:这两种模式并不是冲突的,他们可能可以出现在同一个网站上~~~~
例如:
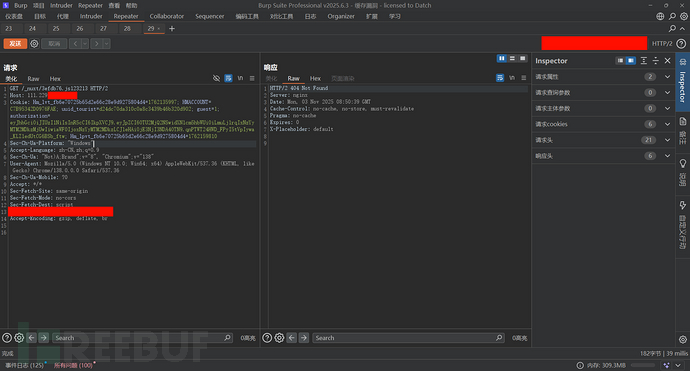
这里就是:
RESTful API为前端应用(如Vue、React)提供清晰、结构化的数据接口,便于处理复杂的业务逻辑和交互
传统静态资源映射则高效地提供前端代码本身(如JS、CSS、图片、字体),这些文件通常由Web服务器直接发送,效率高,并且可以利用浏览器缓存和CDN加速。
还有几条比较明显的区别:
1. 观察URL结构(最直观的线索)
这是你的第一道检查。
特征 | 传统URL映射 | REST风格URL |
是否包含文件扩展名 | 几乎总是包含,如 .php, .html, .jsp, .asp | 通常不包含,路径看起来是“干净”的分段 |
路径是否像文件夹 | 是,例如 /products/software/index.html | 否,更像标识符,例如 /products/42/reviews |
动词 vs 名词 | 路径中可能包含动词,如 getUser.php, deleteProduct.asp | 路径中主要使用名词(复数资源名),如 users, products |
传统URL示例:
http://example.com/blog/post.php?id=123(还有查询参数)
http://example.com/includes/header.html
REST风格URL示例:
http://api.example.com/v1/users/101/posts(资源集合和单个资源)
http://example.com/articles/2025/10/url-mapping(即使有数字,也是作为标识符)
如果还不理解就继续看
2. 修改或“破坏”URL进行测试(非常有效) 这是最关键的一步,直接验证URL是否对应物理文件。 操作:在浏览器中,将一个看似REST风格的URL路径的一部分替换成一个绝对不存在的、随机的字符串。 示例:如果你看到URL是 http://example.com/products/123,尝试访问 http://example.com/products/this_is_fake或 http://example.com/fakepath/resource。 结果分析: 情况A:返回自定义的“404 Not Found”错误页面。 强烈暗示是REST风格。服务器尝试将 this_is_fake当作一个资源ID去数据库查找,但没找到,于是返回了一个友好的错误信息。这证明URL路径是由后端程序逻辑解析的,而非直接映射到文件系统。 情况B:返回标准的“404 File Not Found”错误(如Nginx或Apache的默认错误页)。 强烈暗示是传统映射。服务器试图在 /products/目录下寻找一个名为 this_is_fake的文件,但没找到。这说明路径很可能直接对应文件系统。 3. 分析HTTP方法与响应内容 REST架构的一个核心原则是使用HTTP方法(动词)来指定对资源的操作。 操作:使用工具(如浏览器开发者工具的Network面板,或Postman)观察请求。 判断依据: 传统URL:几乎所有操作都通过 GET和 POST方法完成。例如,删除一篇文章可能通过访问 GET /delete_article.php?id=123来完成。 REST风格URL: GET /articles/123-> 获取文章123(安全操作) POST /articles-> 创建一篇新文章 PUT /articles/123-> 更新/替换文章123 DELETE /articles/123-> 删除文章123 注意:同一个URL(/articles/123),通过不同的HTTP方法,触发了不同的操作。这是REST的典型特征。 4. 检查响应数据的格式 观察服务器返回的数据类型。 传统URL:通常返回完整的 HTML 页面,目的是为了在浏览器中渲染显示。 REST风格URL:通常返回 结构化数据,如 JSON或 XML。这些数据由前端应用(如JavaScript)消费,用于动态更新页面。如果你的请求返回了清晰的JSON数据,这几乎可以肯定是一个API端点,属于REST风格。 5. 直接探测技术栈 如果以上方法仍不确定,可以尝试获取技术栈信息。 操作:使用浏览器开发者工具或 curl -I命令查看响应头。 寻找线索: 头部包含 X-Powered-By: Express(Node.js), X-Powered-By: ASP.NET等,这表明确实有后端应用服务器在处理请求,支持REST风格。 如果URL是 .php,但返回JSON,这可能是混合模式:用传统文件映射的URL来提供REST风格的API(例如,api.php文件根据路径参数和HTTP方法路由请求)。
那么我们知道这个后,要怎么利用呢?
首先我们看一个示例:
一个网站的端点(路径)http://example.com/user/1,会返回用户1的信息。
我们可以试图在后面添加一种随机的字符串(也就是网站百分百不可能存在的路径)http://example.com/user/1/123456.css
这个时候:
如果还是成功响应,返回了用户1的信息,就代表使用REST风格的URL,它忽略了非重要字符:123456.css
如果响应失败了,返回了404,那么就代表使用了传统风格的URL,因为它将123456.css识别成了一个文件,网站要寻找1/目录下的123456.css文件,如果没找到,就会返回404。
到这里都能理解吧:
那么什么时候会出现缓存漏洞呢?那么就是源服务器使用了REST风格的URL,而缓存服务器使用了传统风格的URL的时候。
为什么呢?假如缓存的规则是:http://example.com/css/1.css,这样以css、png、js结尾的缓存规则,那么ttp://example.com/css/1.css就会进行缓存(这是缓存规则),而用户有一个会回显身份的端口,http://example.com/user/a。现在如果我构造一个:http://example.com/user/a/1.css 这样的URL,会回显用户a的内容吗?
答案:会的
因为REST风格的URL会忽略非重要字符串:也就是1.css,而缓存规则是以css、png、js结尾的。
那么http://example.com/user/a/1.css,就会进行缓存,缓存的内容是什么?缓存的内容当然是:
http://example.com/user/a的内容啦,这就是缓存漏洞。
概括一下,上面看懂的这里就不用看了
“源服务器“如何将URL路径映射到资源,向目标端点的URL中添加一个任意路径段。如果响应仍然包含与基本响应相同的敏感数据,则表明源服务器抽象URL路径并忽略添加的段。例如,如果将/user/a/修改为/user/a/sadsada123456仍然返回订单信息,就是这种情况。 为了测试“缓存服务器”如何将URL路径映射到资源,需要通过添加静态扩展来修改路径,以尝试匹配缓存规则。例如,将/api/orders/123/foo更新为/api/orders/123/foo.js。如果响应被缓存,这表明: - 缓存使用静态扩展解释完整的URL路径。 - 存在缓存规则来存储以.js结尾的请求的响应。 缓存可能有基于特定静态扩展的规则。尝试一系列扩展,包括.css、.ico和.exe。 然后,可以构建一个返回动态响应并将其存储在缓存的URL。请注意,这种攻击仅限于您测试的特定端点,因为源服务器通常对不同端点有不同的抽象URL规则。
还不明白?没关系,直接上靶场实战:
靶场地址:https://portswigger.net/web-security/learning-paths/web-cache-deception/wcd-using-path-mapping-discrepancies/web-cache-deception/lab-wcd-exploiting-path-mapping
第一步,先测试该网站的URL路径是REST风格还是传统风格,还是两种都使用的混合风格。
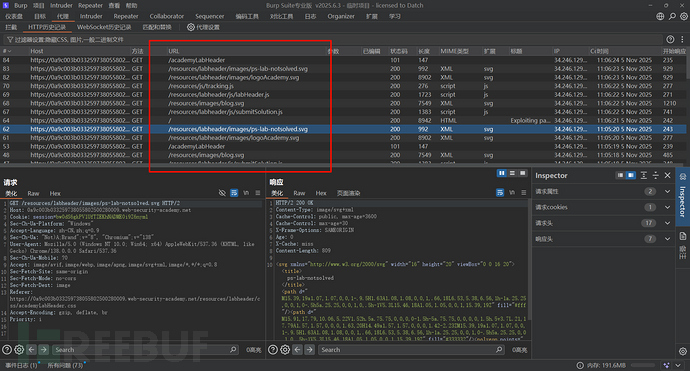
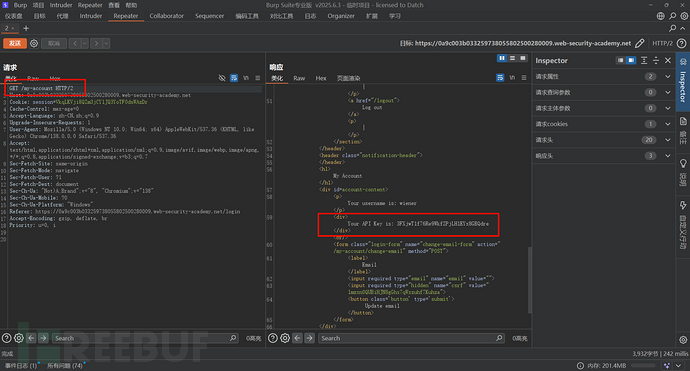
一眼望去,没有https://xxxx/web-security/a这种形式的数据包状态码返回是200的,没事我们进行登录:
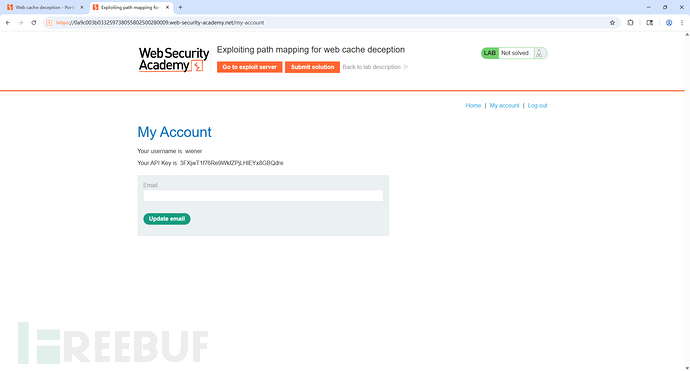
登录后我们就获得了自己的key,
我们去BP找到这个数据包,注意这个数据包的形式,是不是就是REST风格的,所以该网站使用的是混合风格,在加载js文件的时候是传统风格,而加载数据类的时候是REST风格。
那么就可以测试这个网站的URL是否会对随机字符串进行抽象化处理了。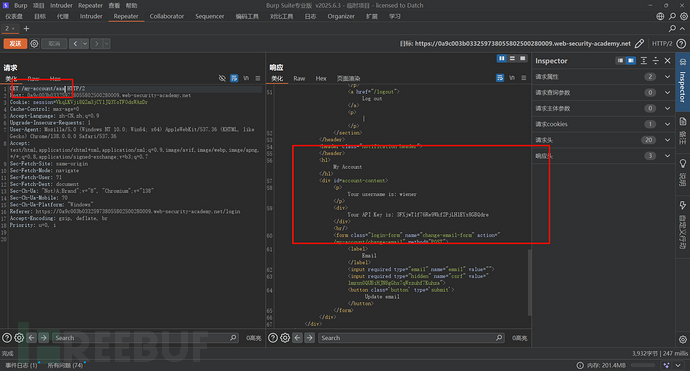
哦豁,它会进行抽象。而且我们观察标头,发现它这里并不会缓存: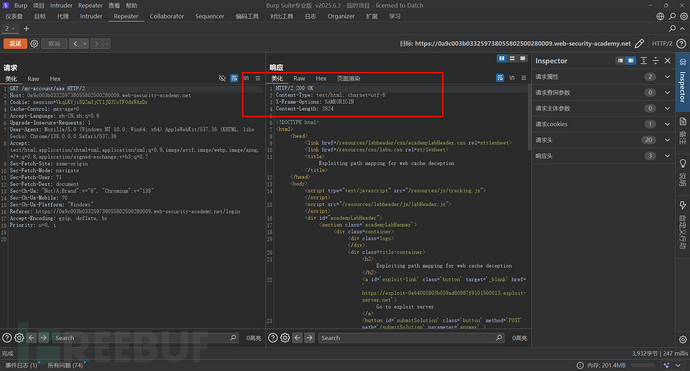
这没关系,因为一般网站会缓存的资源是什么?静态资源:js、css等等,我们去历史数据包中查看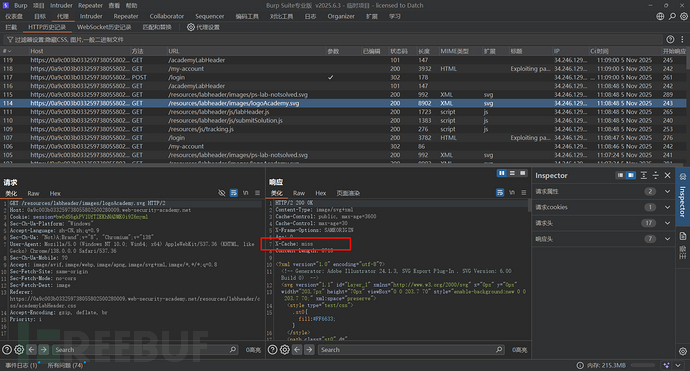
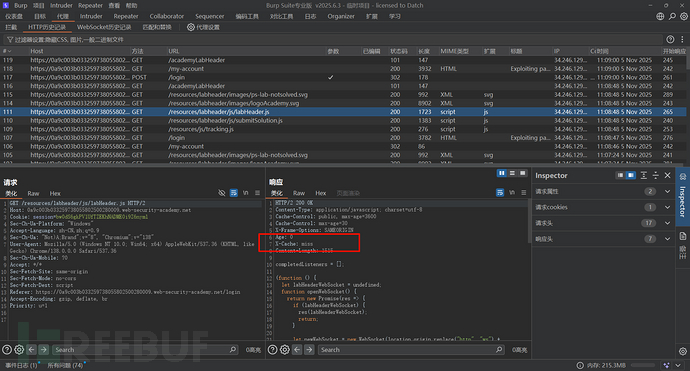
你看,svg、js数据包就会进行缓存吗?当然不是,我们要放到重放器里,连续发送两次观察标头: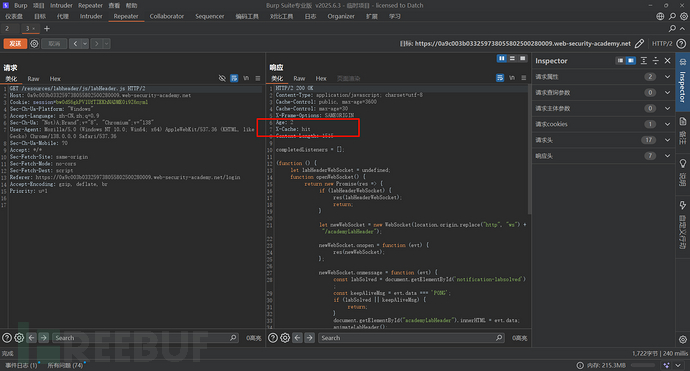
这样就代表资源缓存了,那我们是不是就可以猜测这个网站的缓存规则是:svg、js后缀结尾的?
那么我们试试看?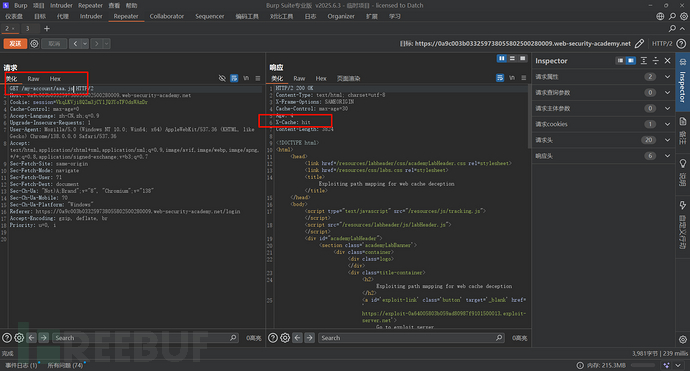
ohhh,现在是不是就成功缓存了用户a的身份信息。好的,现在我们模拟一下攻击者
你有用户a的身份信息,通过用户a的身份信息登录到网站,成功的寻找到了两个关键的东西:缓存信息的规则、敏感信息的端口。你要怎么获取到用户b的规则呢?
很简单,实战的时候: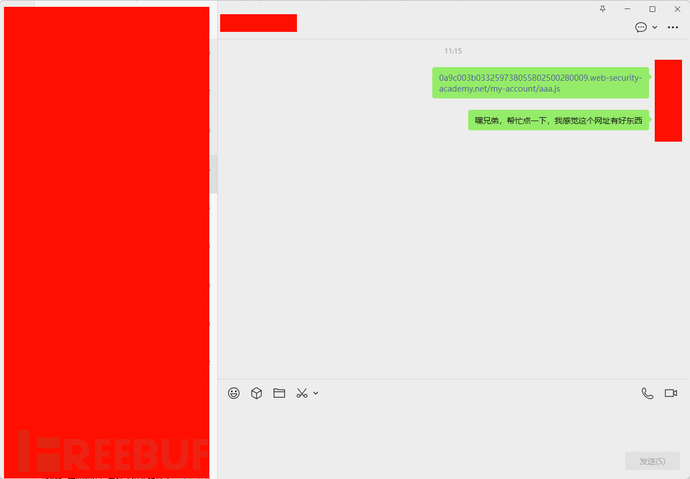
然后,对方点击以后,就在你的BP再次发包就可以看到了对方的key了~,这其实就是XSS
如有侵权请联系:admin#unsafe.sh