
本文介绍了一种轻量级反Bot系统的设计与实现方法。通过浏览器指纹技术收集设备属性信号,并结合加密和混淆手段保护数据安全。该方案应用于登录流程中,客户端生成加密指纹并发送至服务器进行分析检测。旨在提高网站防御自动化攻击的能力。 2025-10-8 07:29:5 Author: securityboulevard.com(查看原文) 阅读量:16 收藏

This is the first article in a two-part series where we show how to build your own anti-bot system to protect a login endpoint, without relying on third-party services.
Why write this?
Many bot detection solutions, reCAPTCHA, Turnstile, or vendor-maintained scripts, are designed for easy integration but come with tradeoffs. They often require trusting an external service, offer limited visibility into detection logic, and don’t give you full control over the data or defenses.

Even solutions like Castle’s, which offer powerful detection with clear observability, might not be the right fit for every team. Some developers want to understand how bot detection works under the hood, or build something minimal and self-contained, at least to start with.
This guide is for them.
What we present here is a lightweight, standalone anti-bot system. It’s not meant to replace production-grade platforms, but it does model many of the considerations that matter in practice, such as obfuscation to raise the cost of reverse engineering, encrypted payloads to prevent tampering, and clear handling of fingerprint freshness.
We apply this to login, one of the most sensitive and targeted endpoints on any website, but the design generalizes to other workflows like signup or checkout.
Why publish this if we sell bot protection?
At Castle, we offer a SaaS platform that helps websites and mobile apps detect and stop automated fraud, such as credential stuffing, fake account creation, and more.
So why publish a guide to building your own?
- To raise the bar. We believe in transparency. Explaining how bot detection works makes the ecosystem stronger, for both defenders and researchers.
- To support DIY use cases. Some teams prefer to build their own solutions for flexibility, cost, or control. We want to share techniques that are grounded in reality.
- To share concepts. Even if you don’t use Castle, ideas like fingerprint resilience or detection via inconsistency are transferable and worth understanding.
- To show what you're up against. Once you see what it takes to build even a basic anti-bot system, you may conclude it’s not worth the effort. Modern bots are sophisticated, and attackers adapt quickly. We want to demystify the process, not to encourage everyone to reinvent the wheel, but to make the tradeoffs clearer.
Of course, the implementation described in this series has limitations:
- Minimal obfuscation: fingerprinting logic can be reversed and spoofed by advanced attackers.
- No behavioral signals: this proof of concept doesn’t collect mouse movements, keystrokes, or other interaction data, though such signals are often critical in production-grade detection systems.
- No adaptive risk scoring: the system doesn’t factor in historical context like trusted devices or login location patterns.
- No observability or debugging tools: while visibility is essential in production (to monitor login flows, tune thresholds, and investigate anomalies), this POC doesn’t include tooling for that.
Still, what this approach offers is a transparent, auditable, and controllable foundation. It’s a starting point that you can extend, reason about, and build upon, with no black-box logic or external dependencies.
What this series covers
This tutorial is split into two parts:
- Client-side (this article): We build a browser fingerprinting script, secure it with encryption and obfuscation, and integrate it into a login flow.
- Server-side (next article): We decrypt and analyze the fingerprint to detect bots and enforce fingerprinting-based rate limiting based on resilient signals.
What is fingerprinting
Before we dive into building the anti-bot system, let’s clarify what we mean by fingerprinting, because it’s the foundation of both our rule-based detection and our fingerprint-based rate limiting.
Browser fingerprinting typically refers to the process of collecting a set of attributes from the client’s environment, usually via JavaScript, in order to identify a device. These attributes can include details like screen resolution, number of CPU cores, system fonts, and how the browser renders a canvas element. Most individual signals aren’t unique, but when combined, they often form a fingerprint distinctive and stable enough to recognize a device across sessions. Hence the term “fingerprint”.
Fingerprinting isn't just about tracking
Fingerprinting has a reputation, rightfully so, as a technique for user tracking, especially in advertising contexts. It has been widely used to follow users across websites, even without cookies.
But fingerprinting has broader applications. In this series, we focus on using it for security. The goal isn’t to track individual users. Instead, we use fingerprinting to detect bots and inconsistencies that reveal signs of automation or manipulation. We also use it as a rate limiting key: a fingerprint can act as a coarse signature for grouping traffic from the same bot or actor, even across different IPs.
A fingerprint doesn’t need to be unique
One common misconception is that a fingerprint must uniquely identify a user or device to be useful. That’s not always true, especially in security contexts.
Consider Picasso, Google’s lightweight fingerprinting approach. It avoids uniqueness on purpose. Instead, it clusters similar devices, like iPhones with the same OS and browser version, into shared “device classes.” The goal is to detect lies in attributes like the user agent, not to persistently track individuals.
In fraud detection, this is often enough. We don’t always need a stable, long-lived identifier. What’s often more useful is detecting when a device behaves inconsistently, or when its claimed identity doesn’t match its technical fingerprint.
Stateless vs stateful fingerprinting
There’s no strict definition of what counts as a fingerprint. Some practitioners limit it to JavaScript-collected browser attributes. Others include IP address, ASN, country, or even persistent storage like cookies.
In this series, we focus on stateless browser fingerprinting. That is, we only use signals collected at runtime via JavaScript—no IP correlation, no cookies, no stored history.
This stateless design keeps the implementation simple and avoids privacy and persistence concerns. But it also increases difficulty: without server-side context or state, we have fewer fallback signals when attributes are spoofed or removed.
What counts as a fingerprinting signal?
There’s no canonical list. Fingerprinting signals fall into different categories based on what they reveal and how attackers might forge them:
- Hardware traits like
navigator.hardwareConcurrencyordeviceMemorydescribe device specs. - Rendering quirks like canvas or WebGL output expose subtle behaviors of the browser, GPU, and OS stack, making them harder to fake.
- Automation indicators like
navigator.webdriveror CDP (Chrome devtools protocol) presence aren’t useful for uniqueness, but they’re helpful for detecting scripted or headless environments.
Each signal offers a different tradeoff between entropy, consistency, and resistance to spoofing.
Uniqueness, stability, and resilience
Every fingerprinting system balances three properties:
- Uniqueness: How well does this fingerprint distinguish one device from others?
- Stability: How consistent is it across sessions, updates, or small environmental changes for a given user?
- Resilience: How difficult is it to spoof or manipulate?
In bot detection, resilience often matters most. We’re not trying to precisely track users across months, we’re trying to detect automation and evasion. A fragile fingerprint that breaks when an attacker toggles a header or fakes a single attribute isn’t helpful.
For example, the user agent string provides some entropy but is trivial to override. In fact, changing it is often the first thing bot developers do, whether through Puppeteer, Playwright, or any HTTP client library.
There’s no perfect fingerprint
No signal, or combination of signals, is foolproof. The key is to match your fingerprinting approach to your threat model.
In this series, we optimize for resilience over stability or uniqueness. That’s intentional. We’re not trying to track a user forever. Instead, we want a fingerprint that holds up during the course of an attack, ideally long enough to identify or rate limit a bot campaign, even if it spans multiple IPs.
This isn’t just a technical decision, it’s a methodological one: know what each signal tells you, anticipate how attackers will try to evade it, and build your fingerprinting system accordingly.
Let’s implement a fingerprinting script
Our bot detection system has two main components:
- A browser-based JavaScript script that collects signals (fingerprint)
- A server-side component that evaluates the fingerprint and applies detection logic
In this article, we focus on the client-side. Specifically, we’ll build a script named authfp.js that collects a set of device and environment attributes. These attributes are later evaluated server-side to help us detect bots or enforce rate limiting.
The structure is straightforward. The script defines a class, FingerprintCollector, with a single public method: collect(). This method gathers fingerprinting signals safely, obfuscates them, and returns an encrypted payload that can be attached to login requests.
class FingerprintCollector {
// The constructor just initialized the fingerprint object
constructor() {
this.fingerprint = {};
}
async collect() {
// will be responsible for collecting the fingerprint
}
async #safeCollectSignal(key, fn) {
// responsible for calling the signal collection functions
// in a safe way (try/catch + other encryption logic)
}
// Methods related to the signal collection themselves, e.g.
async #collectCanvasInfo() {
// Collect the canvas fingerprinting information
}
#collectScreenInfo() {
// Collect signals related to the screen width/height etc
}
}
The collect() method is where everything comes together. Here’s a simplified version:
async collect() {
await this.#safeCollectSignal('userAgent', () => navigator.userAgent);
await this.#safeCollectSignal('screen', () => this.#collectScreenInfo());
await this.#safeCollectSignal('cpuCores', () => navigator.hardwareConcurrency);
await this.#safeCollectSignal('deviceMemory', () => navigator.deviceMemory);
await this.#safeCollectSignal('maxTouchPoints', () => navigator.maxTouchPoints);
await this.#safeCollectSignal('language', () => navigator.language);
await this.#safeCollectSignal('languages', () => JSON.stringify(navigator.languages));
await this.#safeCollectSignal('timezone', () => Intl?.DateTimeFormat()?.resolvedOptions()?.timeZone);
await this.#safeCollectSignal('platform', () => navigator.platform);
await this.#safeCollectSignal('webdriver', () => navigator.webdriver);
await this.#safeCollectSignal('playwright', () => '__pwInitScripts' in window || '__playwright__binding__' in window);
await this.#safeCollectSignal('webgl', () => this.#collectWebGLInfo());
await this.#safeCollectSignal('canvas', () => this.#collectCanvasInfo());
await this.#safeCollectSignal('cdp', () => this.#collectCDPInfo());
await this.#safeCollectSignal('worker', () => this.#collectWorkerInfo());
return btoa(JSON.stringify(this.fingerprint));
}
We intentionally keep the set of signals limited but representative enough to be useful in practice while still readable for educational purposes.
What each attribute captures
Here’s a brief explanation of what each signal means and why we collect it:
| Attribute | Description |
|---|---|
userAgent |
Full user agent string identifying the browser and OS. |
screen |
Dimensions and properties like width, height, and color depth. Useful for spotting abnormal setups. |
cpuCores |
Number of logical CPU cores (navigator.hardwareConcurrency). |
deviceMemory |
Approximate device RAM in GB (navigator.deviceMemory). |
maxTouchPoints |
Number of supported simultaneous touch points. Can expose desktop browsers faking mobile user agents. |
language / languages |
Reported user interface language(s). Helps detect inconsistencies across locale, timezone, and IP. |
timezone |
The client’s reported time zone. Can be cross-checked with IP geolocation or session patterns. |
platform |
Reported OS platform (e.g. MacIntel, Win32). Often spoofed in combination with userAgent. |
webdriver |
Indicates whether automation control is enabled. True in many bot frameworks unless patched. |
playwright |
Detects signs of Playwright automation (__pwInitScripts, __playwright__binding__). Catches setups that bypass webdriver. |
webgl |
Unmasked WebGL vendor and renderer. Adds entropy and can expose spoofing if inconsistent across contexts. |
canvas |
A hash of rendered canvas content, plus tampering indicators. Highly distinctive in genuine environments. |
cdp |
Detects Chrome DevTools Protocol hooks used by automation. Not unique, but strongly tied to bot tooling. |
worker |
Repeats select signals (e.g. WebGL, user agent) inside a Worker context. Helps catch partial spoofing or context inconsistencies. |
We won’t go into the internals of each signal here, those details are covered in the implementation. The goal is to show the kind of structured fingerprint your server will receive after decrypting the payload from the client.
Below is a real example of a decrypted fingerprint, collected when a user loads the login form:
{
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36',
screen: {
width: 2560,
height: 1440,
colorDepth: 24,
availWidth: 2560,
availHeight: 1415
},
cpuCores: 14,
deviceMemory: 8,
maxTouchPoints: 0,
language: 'en',
languages: '["en","fr-FR","fr","en-US"]',
timezone: 'Europe/Paris',
platform: 'MacIntel',
webdriver: false,
playwright: false,
webgl: {
unmaskedRenderer: 'ANGLE (Apple, ANGLE Metal Renderer: Apple M4 Pro, Unspecified Version)',
unmaskedVendor: 'Google Inc. (Apple)'
},
canvas: {
hash: '257200cd',
hasAntiCanvasExtension: false,
hasCanvasBlocker: false
},
cdp: false,
worker: {
webGLVendor: 'Google Inc. (Apple)',
webGLRenderer: 'ANGLE (Apple, ANGLE Metal Renderer: Apple M4 Pro, Unspecified Version)',
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36',
languages: '["en","fr-FR","fr","en-US"]',
platform: 'MacIntel',
hardwareConcurrency: 14,
cdp: false
}
}
Fingerprint tampering: focus on the canvas fingerprint
In this section, we focus on the canvas fingerprint, not because it’s uniquely important, but because it demonstrates a broader principle: fingerprinting isn’t just about collecting high-entropy attributes. It’s also about verifying whether those attributes are trustworthy or have been manipulated.
Canvas fingerprinting is a particularly relevant example. It's widely used because it yields high entropy, and just as widely targeted by anti-detection tools aiming to evade it.
The basic idea is straightforward: draw a combination of text and shapes onto a <canvas> element and convert it into a base64 image using toDataURL(). The exact rendering depends on fonts, anti-aliasing, GPU drivers, and other subtle factors. These small differences produce unique results that can be hashed to create a fingerprint.
However, in fraud detection, the canvas fingerprint's real value isn’t just its uniqueness, it’s how easily it can be tampered with. That tampering surface becomes an opportunity for detection.
Tools like CanvasBlocker (a privacy extension) and anti-detect browsers like Undetectable commonly interfere with canvas APIs. They either block access to rendering outputs or inject random noise into the result. Rather than trusting the canvas hash blindly, we should also ask: was this signal manipulated?
Below is the canvas collection function used in this proof of concept:
async #collectCanvasInfo() {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
// Draw some shapes and text
ctx.textBaseline = "top";
ctx.font = "14px 'Arial'";
ctx.textBaseline = "alphabetic";
ctx.fillStyle = "#f60";
ctx.fillRect(125, 1, 62, 20);
ctx.fillStyle = "#069";
ctx.fillText("Hello, world!", 2, 15);
ctx.fillStyle = "rgba(102, 204, 0, 0.7)";
ctx.fillText("Hello, world!", 4, 17);
// Get base64 representation
const dataURL = canvas.toDataURL();
let hasAntiCanvasExtension = false;
let hasCanvasBlocker = false;
try {
ctx.getImageData(canvas);
} catch (e) {
try {
hasAntiCanvasExtension = e.stack.indexOf('chrome-extension') > -1;
hasCanvasBlocker = e.stack.indexOf('nomnklagbgmgghhjidfhnoelnjfndfpd') > -1;
} catch (_) { }
}
return {
hash: await crypto.subtle.digest('SHA-256', new TextEncoder().encode(dataURL)).then(buffer => {
return Array.from(new Uint8Array(buffer))
.map(byte => byte.toString(16).padStart(2, '0'))
.join('')
.slice(0, 8);
}),
hasAntiCanvasExtension,
hasCanvasBlocker,
}
}
This method does two things:
- Generates a hash from the canvas output that reflects how the browser renders content.
- Checks for tampering, by inspecting error stack traces. If rendering fails (a common tactic to block fingerprinting), we check for clues that known extensions or content scripts interfered.
This approach is adapted from our deep dive on detecting canvas noise, which explores further techniques like rendering diffs and timing analysis.
In this POC, we intentionally keep things simple, but a production-grade system might also include:
- Detection test of known noise patterns
- Detection of patched or proxy-wrapped native methods
- Pixel-by-pixel diffs to catch injected randomness
- Cross-context validation (e.g. comparing canvas results from the main thread and Web Workers or iframes)
Consistency checks apply beyond canvas
This principle of tamper detection extends to many other fingerprinting signals.
A classic example: attackers spoof the userAgent string to look like Chrome on Windows, but forget to update navigator.platform, which might still say MacIntel. That inconsistency is a red flag.
Our detection logic looks for exactly this kind of mismatch. As discussed in our blog post, relying on the user agent alone is risky. It’s trivially spoofed, and attackers often do so without updating other related attributes, revealing inconsistencies.
While this POC checks only a few such mismatches, a production system should aim to cover as many as possible. The more relationships you can validate between fingerprint attributes, the harder it becomes for attackers to spoof everything correctly.
Making fingerprint collection harder to reverse engineer
Any client-side security logic operates in a hostile environment. The attacker controls the browser, the JavaScript runtime, devtools, and often the network. If your fingerprinting script is shipped in cleartext, it will be read, debugged, and potentially bypassed.
In practice, this leads to two main attack strategies:
- Faking signals using anti-detect tools or by manually overriding JavaScript APIs.
- Forging fingerprints by reconstructing expected payloads without ever executing your actual code.
To raise the bar, we use two defenses in combination:
- Payload encryption to make signal values unreadable and harder to spoof.
- Code obfuscation to make the collection logic more difficult to analyze or tamper with.
Encrypting the fingerprint payload
First, encryption. This isn’t about transport-level protection (e.g., HTTPS), but about securing the data inside the browser, before it ever leaves the device.
If you collect and send values like this:
this.fingerprint = {
userAgent: navigator.userAgent,
deviceMemory: navigator.deviceMemory,
// ...
};
Then any attacker with devtools or a breakpoint can inspect or modify them in plain text. Worse, they can replicate the payload structure and simulate a “clean” fingerprint without triggering any detection.
Instead, we encrypt every key-value pair at collection time. This is done using the #safeCollectSignal helper:
async #safeCollectSignal(key, fn) {
try {
const value = await fn();
const encryptedKey = await this.#encryptString(key, 'sd2c56cx1&d753(sdf692ds1');
const encryptedValue = await this.#encryptString(JSON.stringify(value), 'sd2c56cx1&d753(sdf692ds1');
this.fingerprint[encryptedKey] = encryptedValue;
return value;
} catch (_) {
const encryptedKey = await this.#encryptString(key, 'sd2c56cx1&d753(sdf692ds1');
const encryptedValue = await this.#encryptString('ERROR', 'sd2c56cx1&d753(sdf692ds1');
this.fingerprint[encryptedKey] = encryptedValue;
return 'ERROR';
}
}
As a result, even if an attacker inspects this.fingerprint, they’ll see something like:
{
xhdsLOnxhHG: 'XhbkshsfhnsdffdhHDUndjskcjhLDJl'
}
This won’t stop a determined reverse engineer from hooking methods and dumping plaintext values, but it significantly slows down opportunistic tampering.
We don’t mandate a specific encryption algorithm. Use any fast, symmetric method that can be reliably decrypted on the server.
Obfuscating the collection logic
The second layer of protection is obfuscation.
Obfuscation ≠ minification. Minifiers reduce size; obfuscators transform code structure to make it harder to read, reason about, or debug.
Obfuscation helps defend against:
- Static inspection, e.g. reading the script to identify what’s being collected.
- Dynamic analysis, e.g. stepping through with breakpoints or console logs.
The goal is not to make your code unbreakable, but to make reverse engineering expensive. If you only encrypt the payload, an attacker could read the script, extract the encryption routine, and reimplement it offline. With obfuscation, that extraction becomes much harder.
We use obfuscator.io via the webpack-obfuscator plugin. It’s not as strong as VM-based protection, but it’s simple and effective enough to deter casual analysis. Our Webpack config also includes minification via Terser:
const TerserPlugin = require('terser-webpack-plugin');
const WebpackObfuscator = require('webpack-obfuscator');
module.exports = {
entry: './static/js/authfp.js',
output: {
filename: 'authfp.min.js',
path: __dirname + '/static/js/',
library: {
type: 'module'
},
globalObject: 'this'
},
experiments: {
outputModule: true
},
mode: 'production',
optimization: {
minimize: true,
minimizer: [
new TerserPlugin({
terserOptions: {
compress: {
drop_console: false,
},
mangle: true,
},
}),
],
},
plugins: [
new WebpackObfuscator({
// Medium obfuscation, optimal performance
compact: true,
controlFlowFlattening: false,
controlFlowFlatteningThreshold: 0,
deadCodeInjection: true,
deadCodeInjectionThreshold: 0.4,
debugProtection: false,
debugProtectionInterval: 0,
disableConsoleOutput: true,
identifierNamesGenerator: 'hexadecimal',
log: false,
numbersToExpressions: true,
renameGlobals: false,
selfDefending: false,
simplify: true,
splitStrings: true,
splitStringsChunkLength: 10,
stringArray: true,
stringArrayCallsTransform: true,
stringArrayCallsTransformThreshold: 0.75,
stringArrayEncoding: ['base64'],
stringArrayIndexShift: true,
stringArrayRotate: true,
stringArrayShuffle: true,
stringArrayWrappersCount: 2,
stringArrayWrappersChainedCalls: true,
stringArrayWrappersParametersMaxCount: 4,
stringArrayWrappersType: 'function',
stringArrayThreshold: 0.75,
transformObjectKeys: false,
unicodeEscapeSequence: false,
// Preserve the exported class name and its methods
reservedNames: ['FingerprintCollector', 'collect', 'constructor', 'default'],
reservedStrings: ['default']
}, [])
],
};
You can adjust the configuration depending on performance and payload size. Higher obfuscation makes code heavier and slower, so there’s always a tradeoff.
A quick look at the obfuscated output gives a sense of what reverse engineers are up against:
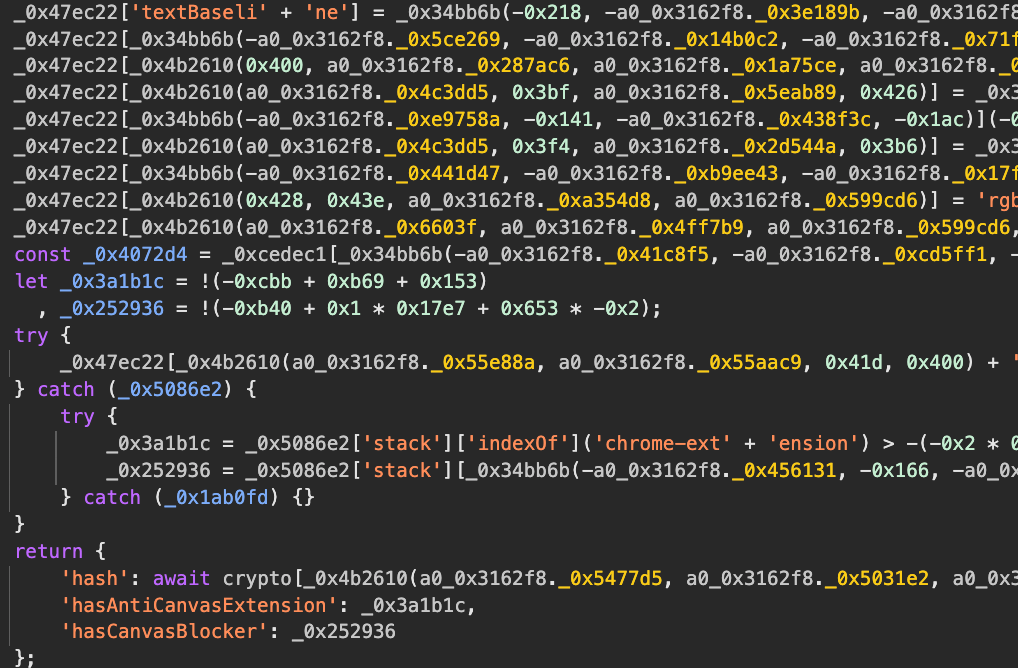
Why this matters
This setup is far from foolproof. Skilled attackers can eventually bypass it. But:
- It blocks easy wins like payload replay or static payload forging.
- It forces attackers to either run your script (giving you real signals), or spend time reversing it.
This asymmetry is the entire point. The more effort required to tamper, the fewer attackers will bother.
In the next section, we’ll walk through integrating this fingerprint into the login flow and prepping it for server-side evaluation.
Integrating the fingerprinting script
Now that we have a fingerprinting script that collects browser signals, encrypts them, and hides its internal logic, let’s see how to actually use it.
We’ll start with a toy login form. The goal here isn’t to build a production-ready frontend, but to show how the fingerprint gets tied into a typical authentication flow.
The relevant integration happens in just a few lines. We import the obfuscated fingerprinting script (authfp.min.js), collect the fingerprint on form submission, and send it along with the login credentials.
Here’s a simplified example:
<script type="module">
import FingerprintCollector from './js/authfp.min.js';
document.getElementById('loginForm').addEventListener('submit', async function(e) {
e.preventDefault();
const fingerprint = await new FingerprintCollector().collect();
// ...
const email = document.getElementById('email').value;
const password = document.getElementById('password').value;
// ...
try {
// Send POST request to /login
const response = await fetch('/login', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
email: email,
password: password,
fingerprint: fingerprint
})
});
const data = await response.json();
// ...
} catch (error) {
// ...
} finally {
// ...
}
});
</script>
A few things to note:
FingerprintCollector().collect()returns an encrypted, base64-encoded string containing the fingerprint data.- This happens entirely client-side, no external calls or dependencies.
- The fingerprint is sent alongside the credentials as part of the same login request.
Why attach the fingerprint here? Because it’s our primary input for both bot detection and rate limiting on the server. If this step is skipped or tampered with, the server can reject the request outright.
With that, we’ve completed the client-side portion of our anti-bot stack. We now have:
- A fingerprinting script that collects useful signals
- Obfuscation and encryption to slow down reverse engineering
- A login form that integrates the fingerprint into the authentication flow
In the next article, we’ll move to the server and show how to actually use this fingerprint to detect bots and apply rate limits, even when attackers rotate IPs or spoof headers.
*** This is a Security Bloggers Network syndicated blog from The Castle blog authored by Antoine Vastel. Read the original post at: https://blog.castle.io/roll-your-own-bot-detection-fingerprinting-javascript-part-1/
如有侵权请联系:admin#unsafe.sh