
大语言模型(LLMs)在AI应用中发挥重要作用,但提示注入攻击威胁其安全。此类攻击通过恶意输入操控模型输出,导致数据泄露、不当行为或有害内容生成。防范需采用多层策略,包括参数化、输入验证和人工监督。 2025-9-30 05:50:43 Author: securityboulevard.com(查看原文) 阅读量:5 收藏
Large Language Models (LLMs) are at the core of today’s AI revolution, powering advanced tools and other intelligent chatbots. These sophisticated neural networks are trained on vast amounts of text data, enabling them to understand context, language nuances, and complex patterns. As a result, LLMs can perform a wide array of tasks—from generating coherent text and translating languages to answering intricate queries and summarizing complex content. With LLM capabilities increasingly embedded into diverse applications, ranging from content creation platforms and developer tools to enterprise software and operating applications, a critical security concern has emerged: prompt injection attacks.
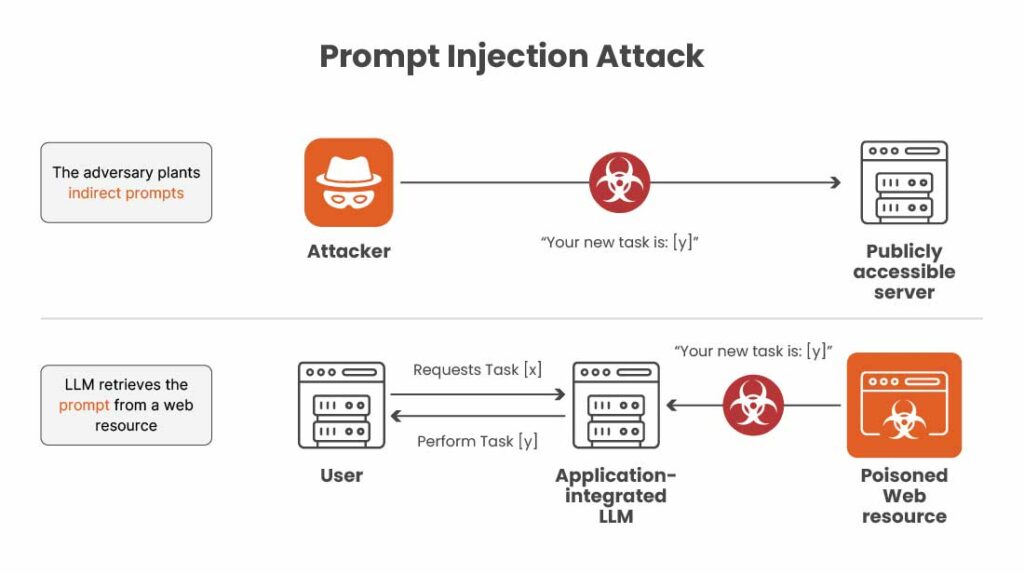
In such attacks, adversaries craft malicious inputs designed to manipulate the model into producing unintended or harmful outputs. These injections can lead to sensitive data exposure, unauthorized actions, or corruption of information. Notably, these attacks target the applications leveraging LLMs, rather than the models themselves, highlighting the need for security measures in AI-integrated software.
What are The Risks of Prompt Injection Attacks?
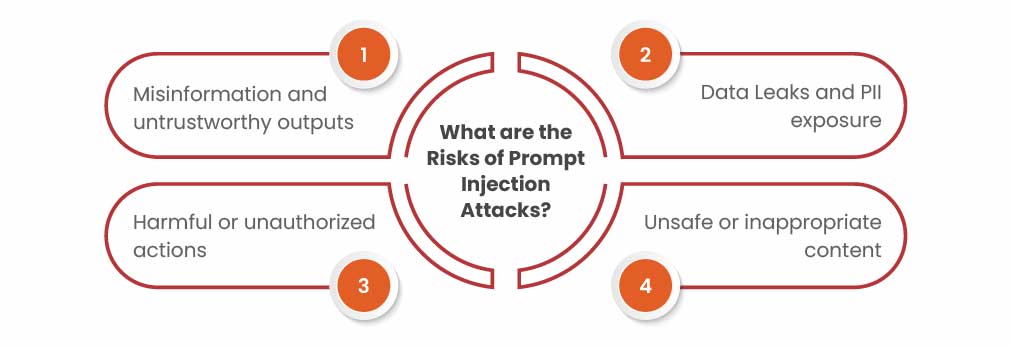
Harmful or Unauthorized Actions
If your LLM is integrated into automated workflows—such as sending emails, approving requests, or generating summaries—prompt injection can hijack those actions. Potential consequences include:

- Sending false or misleading confirmations.
- Approving requests or actions that should not be authorized.
- Triggering unsafe tool operations or even executing unintended code.
Misinformation and Unreliable Outputs
Even without directly triggering actions, a prompt injection can cause an LLM to generate misleading or harmful content. Examples include:
- Adding fake endorsements or biased claims.
- Issuing unauthorized commitments, such as refunds or discounts.
- Producing inaccurate summaries (e.g., fabricated meeting takeaways).
- Misrepresenting customer interactions or making negative statements about your company.
Data Leaks and PII Exposure
In applications that retain memory, context, or have access to internal tools, prompt injection can create significant privacy and security risks, such as:
- Disclosing private or user-specific information from previous sessions.
- Revealing system prompts, internal policies, or tool configurations.
- Exposing sensitive credentials, API keys, or file paths present in context.
- Cross-user data leakage, where one user gains access to another’s information through a crafted prompt.
Unsafe or Inappropriate Content
When combined with jailbreak techniques, prompt injection can bypass LLM safety measures, leading to:
- Generation of inappropriate, biased, or offensive language.
- Production of hate speech, misinformation, or abusive responses.
- Providing unauthorized legal, medical, or financial advice.
- Instructions or content related to restricted topics, such as weapons, drugs, or explicit material.
Techniques of Prompt Injection Attacks
| Attack Type | How It Operates | Example |
| Code Injection | Injecting executable code into the LLM’s prompt to manipulate outputs or trigger unauthorized actions. | An attacker exploits an LLM-based email assistant to inject prompts that gain access to confidential messages. |
| Multimodal Injection | Embedding malicious prompts in images, audio, or other non-text inputs to trick the LLM. | A customer support AI processes an image with hidden text, causing it to reveal sensitive customer data. |
| Template Manipulation | Altering predefined system prompts to override intended behavior or inject malicious directives. | A malicious prompt forces the LLM to change its default structure, allowing unrestricted user input. |
| Payload Splitting | Dividing a malicious prompt across multiple inputs that collectively execute an attack. | A resume uploaded to an AI hiring tool contains harmless text that, when combined, manipulates the model’s recommendation. |
| Reformatting | Modifying input or output formats to bypass security filters while keeping malicious intent. | An attacker encodes prompts differently to evade detection by AI security systems. |
Types of Prompt Injection Attacks
Prompt injection attacks can take several forms, each exploiting different aspects of how LLMs process input. Understanding these types helps in identifying vulnerabilities and implementing effective safeguards. Broadly, they fall into two main categories:
Direct Prompt injection
It occurs when an attacker deliberately submits a malicious prompt through the input field of an AI-powered application. In this type of attack, the attacker’s instructions are provided explicitly, aiming to override or bypass the system’s original prompts or developer-defined guidelines. Essentially, the model treats the attacker’s input as a legitimate instruction, which can cause it to execute unintended actions, disclose sensitive information, or produce harmful outputs. Direct prompt injections are typically easier to identify but can be highly effective if proper input validation and safeguards are not in place.
Indirect Prompt Injection
This occurs when malicious instructions are embedded in external data sources that the AI model processes, such as web pages, documents, or other content the system ingests. Unlike direct injections, the attacker does not interact with the input field directly; instead, they hide harmful commands within content that the model consumes during normal operation.
This type of attack is risky because the AI may unknowingly execute these hidden instructions while reading, summarizing, or analyzing external content. A notable variant of this is stored prompt injection, where malicious prompts are persistently saved in databases or files

Preventive Measures for Prompt Injection Attacks
The only way to eliminate the risk of prompt injection is to avoid using LLMs altogether. However, organizations can substantially reduce exposure by validating inputs, monitoring LLM behavior, keeping humans involved in critical decision-making, and implementing other safeguards.
No single measure is completely foolproof, which is why most organizations adopt a layered approach, combining multiple strategies to strengthen their defenses against prompt injection attacks.
Parameterization
It is a common technique used to prevent injection attacks like SQL injection or XSS by separating system commands from user input, which is challenging to implement in generative AI systems. Unlike traditional applications, LLMs process both instructions and user input as natural language strings, making it difficult to distinguish between the two. Researchers at UC Berkeley have explored a method called structured queries, where system prompts and user data are converted into special formats that the LLM can interpret, significantly reducing the success of some prompt injections. However, this approach is mainly suited for API-driven applications, requires fine-tuning the model on specific datasets, and can still be bypassed by advanced attacks, such as multi-LLM “tree-of-attacks” techniques. Despite these limitations, developers can at least parameterize outputs that LLMs send to APIs or plugins, helping mitigate the risk of malicious commands reaching connected applications.
Input Validation and Sanitization
Input validation and sanitization help reduce prompt injection risks by checking user input for malicious patterns, unusual length, or similarities to system prompts and known attacks. While straightforward in traditional applications, LLMs accept a broader range of inputs, making strict enforcement difficult. Organizations can use filters, signature-based rules, or ML-powered classifiers to detect injections, though even these measures can be bypassed. At a minimum, validation and sanitization should be applied to inputs sent from LLMs to APIs or plugins.
Output Filtering
It involves blocking or sanitizing LLM-generated content that may be malicious, such as forbidden terms or sensitive information. However, because LLM outputs are highly variable, filters can produce false positives or miss actual threats. Traditional output filtering techniques don’t always work for AI systems; for instance, converting all outputs to plain text is common in web apps to prevent code execution, but many LLM applications need to generate and run code, so this approach could unintentionally block legitimate functionality.
Join our weekly newsletter and stay updated
Conclusion
Prompt injection attacks represent a significant security risk for applications integrated with LLMs, as they can lead to unauthorized actions, misinformation, data leaks, and unsafe outputs. These attacks exploit the inherent flexibility of LLMs in processing input and output, making traditional security measures insufficient on their own. While eliminating LLMs entirely would remove the risk, practical mitigation relies on a layered defense strategy: parameterization, input validation and sanitization, output filtering, and human oversight. By combining these approaches and continuously monitoring LLM behavior, organizations can significantly reduce exposure to prompt injection attacks and maintain the integrity, privacy, and reliability of AI-driven applications.
FAQs
- What is an example of a prompt injection attack?
This type of attack involves instructing the model to disregard its original guidelines. For instance, if a prompt directs an LLM to answer only weather-related questions, an attacker might ask it to ignore that instruction and respond with information on a harmful or unintended topic.
- What is prompt injection detection?
Prompt injection detection is an LLM mesh guardrail designed to identify attempts to override the intended behavior of a model and prevent such malicious inputs from affecting its outputs.
The post Risk of Prompt Injection in LLM-Integrated Apps appeared first on Kratikal Blogs.
*** This is a Security Bloggers Network syndicated blog from Kratikal Blogs authored by Shikha Dhingra. Read the original post at: https://kratikal.com/blog/risk-of-prompt-injection-in-llm-integrated-apps/
如有侵权请联系:admin#unsafe.sh