2025-09-26
15 min read

Five years ago, we announced that we were Eliminating Cold Starts with Cloudflare Workers. In that episode, we introduced a technique to pre-warm Workers during the TLS handshake of their first request. That technique takes advantage of the fact that the TLS Server Name Indication (SNI) is sent in the very first message of the TLS handshake. Armed with that SNI, we often have enough information to pre-warm the request’s target Worker.
Eliminating cold starts by pre-warming Workers during TLS handshakes was a huge step forward for us, but “eliminate” is a strong word. Back then, Workers were still relatively small, and had cold starts constrained by limits explained later in this post. We’ve relaxed those limits, and users routinely deploy complex applications on Workers, often replacing origin servers. Simultaneously, TLS handshakes haven’t gotten any slower. In fact, TLS 1.3 only requires a single round trip for a handshake – compared to three round trips for TLS 1.2 – and is more widely used than it was in 2021.
Earlier this month, we finished deploying a new technique intended to keep pushing the boundary on cold start reduction. The new technique (or old, depending on your perspective) uses a consistent hash ring to take advantage of our global network. We call this mechanism “Worker sharding”.

What’s in a cold start?
A Worker is the basic unit of compute in our serverless computing platform. It has a simple lifecycle. We instantiate it from source code (typically JavaScript), make it serve a bunch of requests (often HTTP, but not always), and eventually shut it down some time after it stops receiving traffic, to re-use its resources for other Workers. We call that shutdown process “eviction”.
The most expensive part of the Worker’s lifecycle is the initial instantiation and first request invocation. We call this part a “cold start”. Cold starts have several phases: fetching the script source code, compiling the source code, performing a top-level execution of the resulting JavaScript module, and finally, performing the initial invocation to serve the incoming HTTP request that triggered the whole sequence of events in the first place.

Cold starts have become longer than TLS handshakes
Fundamentally, our TLS handshake technique depends on the handshake lasting longer than the cold start. This is because the duration of the TLS handshake is time that the visitor must spend waiting, regardless, so it’s beneficial to everyone if we do as much work during that time as possible. If we can run the Worker’s cold start in the background while the handshake is still taking place, and if that cold start finishes before the handshake, then the request will ultimately see zero cold start delay. If, on the other hand, the cold start takes longer than the TLS handshake, then the request will see some part of the cold start delay – though the technique still helps reduce that visible delay.

In the early days, TLS handshakes lasting longer than Worker cold starts was a safe bet, and cold starts typically won the race. One of our early blog posts explaining how our platform works mentions 5 millisecond cold start times – and that was correct, at the time!
For every limit we have, our users have challenged us to relax them. Cold start times are no different.
There are two crucial limits which affect cold start time: Worker script size and the startup CPU time limit. While we didn’t make big announcements at the time, we have quietly raised both of those limits since our last Eliminating Cold Starts blog post:
Worker script size (compressed) increased from 1 MB to 5 MB, then again from 5 MB to 10 MB, for paying users.
Worker script size (compressed) increased from 1 MB to 3 MB for free users.
Startup CPU time increased from 200ms to 400ms.
We relaxed these limits because our users wanted to deploy increasingly complex applications to our platform. And deploy they did! But the increases have a cost:
Increasing script size increases the amount of data we must transfer from script storage to the Workers runtime.
Increasing script size also increases the time complexity of the script compilation phase.
Increasing the startup CPU time limit increases the maximum top-level execution time.
Taken together, cold starts for complex applications began to lose the TLS handshake race.
Routing requests to an existing Worker
With relaxed script size and startup time limits, optimizing cold start time directly was a losing battle. Instead, we needed to figure out how to reduce the absolute number of cold starts, so that requests are simply less likely to incur one.
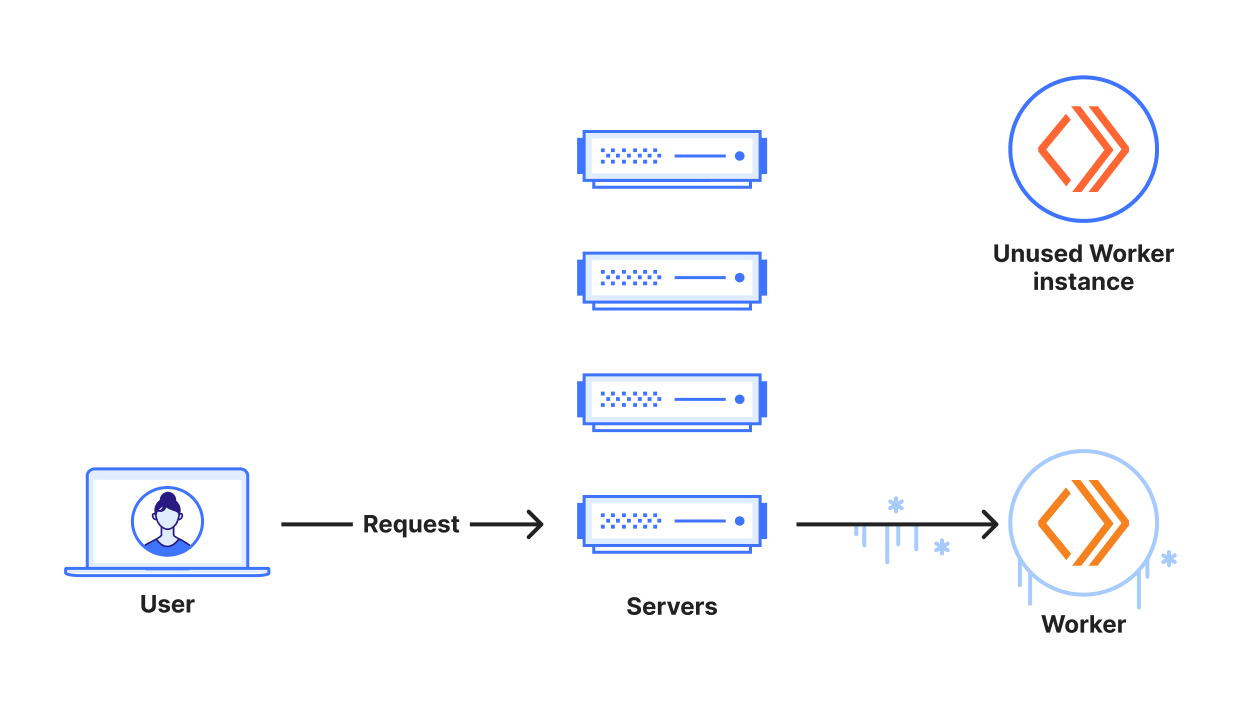
One option is to route requests to existing Worker instances, where before we might have chosen to start a new instance.
Previously, we weren’t particularly good at routing requests to existing Worker instances. We could trivially coalesce requests to a single Worker instance if they happened to land on a machine which already hosted a Worker, because in that case it’s not a distributed systems problem. But what if a Worker already existed in our data center on a different server, and some other server received a request for the Worker? We would always choose to cold start a new Worker on the machine which received the request, rather than forward the request to the machine with the already-existing Worker, even though forwarding the request would avoid the cold start.

To drive the point home: Imagine a visitor sends one request per minute to a data center with 300 servers, and that the traffic is load balanced evenly across all servers. On average, each server will receive one request every five hours. In particularly busy data centers, this span of time could be long enough that we need to evict the Worker to re-use its resources, resulting in a 100% cold start rate. That’s a terrible experience for the visitor.
Consequently, we found ourselves explaining to users, who saw high latency while prototyping their applications, that their latency would counterintuitively decrease once they put sufficient traffic on our network. This highlighted the inefficiency in our original, simple design.
If, instead, those requests were all coalesced onto one single server, we would notice multiple benefits. The Worker would receive one request per minute, which is short enough to virtually guarantee that it won’t be evicted. This would mean the visitor may experience a single cold start, and then have a 100% “warm request rate.” We would also use 99.7% (299 / 300) less memory serving this traffic. This makes room for other Workers, decreasing their eviction rate, and increasing their warm request rates, too – a virtuous cycle!
There’s a cost to coalescing requests to a single instance, though, right? After all, we’re adding latency to requests if we have to proxy them around the data center to a different server.
In practice, the added time-to-first-byte is less than one millisecond, and is the subject of continual optimization by our IPC and performance teams. One millisecond is far less than a typical cold start, meaning it’s always better, in every measurable way, to proxy a request to a warm Worker than it is to cold start a new one.
The consistent hash ring
A solution to this very problem lies at the heart of many of our products, including one of our oldest: the HTTP cache in our Content Delivery Network.
When a visitor requests a cacheable web asset through Cloudflare, the request gets routed through a pipeline of proxies. One of those proxies is a caching proxy, which stores the asset for later, so we can serve it to future requests without having to request it from the origin again.
A Worker cold start is analogous to an HTTP cache miss, in that a request to a warm Worker is like an HTTP cache hit.
When our standard HTTP proxy pipeline routes requests to the caching layer, it chooses a cache server based on the request's cache key to optimize the HTTP cache hit rate. The cache key is the request’s URL, plus some other details. This technique is often called “sharding”. The servers are considered to be individual shards of a larger, logical system – in this case a data center’s HTTP cache. So, we can say things like, “Each data center contains one logical HTTP cache, and that cache is sharded across every server in the data center.”
Until recently, we could not make the same claim about the set of Workers in a data center. Instead, each server contained its own standalone set of Workers, and they could easily duplicate effort.
We borrow the cache’s trick to solve that. In fact, we even use the same type of data structure used by our HTTP cache to choose servers: a consistent hash ring. A naive sharding implementation might use a classic hash table mapping Worker script IDs to server addresses. That would work fine for a set of servers which never changes. But servers are actually ephemeral and have their own lifecycle. They can crash, get rebooted, taken out for maintenance, or decommissioned. New ones can come online. When these events occur, the size of the hash table would change, necessitating a re-hashing of the whole table. Every Worker’s home server would change, and all sharded Workers would be cold started again!
A consistent hash ring improves this scenario significantly. Instead of establishing a direct correspondence between script IDs and server addresses, we map them both to a number line whose end wraps around to its beginning, also known as a ring. To look up the home server of a Worker, first we hash its script, and then we find where it lies on the ring. Next, we take the server address which comes directly on or after that position on the ring, and consider that the Worker’s home.

If a new server appears for some reason, all the Workers that lie before it on the ring get re-homed, but none of the other Workers are disturbed. Similarly, if a server disappears, all the Workers which lay before it on the ring get re-homed.

We refer to the Worker’s home server as the “shard server”. In request flows involving sharding, there is also a “shard client”. It’s also a server! The shard client initially receives a request, and, using its consistent hash ring, looks up which shard server it should send the request to. I’ll be using these two terms – shard client and shard server – in the rest of this post.
Handling overload
The nature of HTTP assets lend themselves well to sharding. If they are cacheable, they are static, at least for their cache Time to Live (TTL) duration. So, serving them requires time and space complexity which scales linearly with their size.
But Workers aren’t JPEGs. They are live units of compute which can use up to five minutes of CPU time per request. Their time and space complexity do not necessarily scale with their input size, and can vastly outstrip the amount of computing power we must dedicate to serving even a huge file from cache.
This means that individual Workers can easily get overloaded when given sufficient traffic. So, no matter what we do, we need to keep in mind that we must be able to scale back up to infinity. We will never be able to guarantee that a data center has only one instance of a Worker, and we must always be able to horizontally scale at the drop of a hat to support burst traffic. Ideally this is all done without producing any errors.
This means that a shard server must have the ability to refuse requests to invoke Workers on it, and shard clients must always gracefully handle this scenario.
Two load shedding options
I am aware of two general solutions to shedding load gracefully, without serving errors.
In the first solution, the client asks politely if it may issue the request. It then sends the request if it receives a positive response. If it instead receives a “go away” response, it handles the request differently, like serving it locally. In HTTP, this pattern can be found in Expect: 100-continue semantics. The main downside is that this introduces one round-trip of latency to set the expectation of success before the request can be sent. (Note that a common naive solution is to just retry requests. This works for some kinds of requests, but is not a general solution, as requests may carry arbitrarily large bodies.)

The second general solution is to send the request without confirming that it can be handled by the server, then count on the server to forward the request elsewhere if it needs to. This could even be back to the client. This avoids the round-trip of latency that the first solution incurs, but there is a tradeoff: It puts the shard server in the request path, pumping bytes back to the client. Fortunately, we have a trick to minimize the amount of bytes we actually have to send back in this fashion, which I’ll describe in the next section.

Optimistically sending sharded requests
There are a couple of reasons why we chose to optimistically send sharded requests without waiting for permission.
The first reason of note is that we expect to see very few of these refused requests in practice. The reason is simple: If a shard client receives a refusal for a Worker, then it must cold start the Worker locally. As a consequence, it can serve all future requests locally without incurring another cold start. So, after a single refusal, the shard client won’t shard that Worker any more (until traffic for the Worker tapers off enough for an eviction, at least).
Generally, this means we expect that if a request gets sharded to a different server, the shard server will most likely accept the request for invocation. Since we expect success, it makes a lot more sense to optimistically send the entire request to the shard server than it does to incur a round-trip penalty to establish permission first.
The second reason is that we have a trick to avoid paying too high a cost for proxying the request back to the client, as I mentioned above.
We implement our cross-instance communication in the Workers runtime using Cap’n Proto RPC, whose distributed object model enables some incredible features, like JavaScript-native RPC. It is also the elder, spiritual sibling to the just-released Cap’n Web.
In the case of sharding, Cap’n Proto makes it very easy to implement an optimal request refusal mechanism. When the shard client assembles the sharded request, it includes a handle (called a capability in Cap’n Proto) to a lazily-loaded local instance of the Worker. This lazily-loaded instance has the same exact interface as any other Worker exposed over RPC. The difference is just that it’s lazy – it doesn’t get cold started until invoked. In the event the shard server decides it must refuse the request, it does not return a “go away” response, but instead returns the shard client’s own lazy capability!
The shard client’s application code only sees that it received a capability from the shard server. It doesn’t know where that capability is actually implemented. But the shard client’s RPC system does know where the capability lives! Specifically, it recognizes that the returned capability is actually a local capability – the same one that it passed to the shard server. Once it realizes this, it also realizes that any request bytes it continues to send to the shard server will just come looping back. So, it stops sending more request bytes, waits to receive back from the shard server all the bytes it already sent, and shortens the request path as soon as possible. This takes the shard server entirely out of the loop, preventing a “trombone effect.”
Workers invoking Workers
With load shedding behavior figured out, we thought the hard part was over.
But, of course, Workers may invoke other Workers. There are many ways this could occur, most obviously via Service Bindings. Less obviously, many of our favorite features, such as Workers KV, are actually cross-Worker invocations. But there is one product, in particular, that stands out for its powerful ability to invoke other Workers: Workers for Platforms.
Workers for Platforms allows you to run your own functions-as-a-service on Cloudflare infrastructure. To use the product, you deploy three special types of Workers:
a dynamic dispatch Worker
any number of user Workers
an optional, parameterized outbound Worker
A typical request flow for Workers for Platforms goes like so: First, we invoke the dynamic dispatch Worker. The dynamic dispatch Worker chooses and invokes a user Worker. Then, the user Worker invokes the outbound Worker to intercept its subrequests. The dynamic dispatch Worker chose the outbound Worker's arguments prior to invoking the user Worker.
To really amp up the fun, the dynamic dispatch Worker could have a tail Worker attached to it. This tail Worker would need to be invoked with traces related to all the preceding invocations. Importantly, it should be invoked one single time with all events related to the request flow, not invoked multiple times for different fragments of the request flow.
You might further ask, can you nest Workers for Platforms? I don’t know the official answer, but I can tell you that the code paths do exist, and they do get exercised.
To support this nesting doll of Workers, we keep a context stack during invocations. This context includes things like ownership overrides, resource limit overrides, trust levels, tail Worker configurations, outbound Worker configurations, feature flags, and so on. This context stack was manageable-ish when everything was executed on a single thread. For sharding to be truly useful, though, we needed to be able to move this context stack around to other machines.
Our choice of Cap’n Proto RPC as our primary communications medium helped us make sense of it all. To shard Workers deep within a stack of invocations, we serialize the context stack into a Cap’n Proto data structure and send it to the shard server. The shard server deserializes it into native objects, and continues the execution where things left off.
As with load shedding, Cap’n Proto’s distributed object model provides us simple answers to otherwise difficult questions. Take the tail Worker question – how do we coalesce tracing data from invocations which got fanned out across any number of other servers back to one single place? Easy: create a capability (a live Cap’n Proto object) for a reportTraces() callback on the dynamic dispatch Worker’s home server, and put that in the serialized context stack. Now, that context stack can be passed around at will. That context stack will end up in multiple places: At a minimum, it will end up on the user Worker’s shard server and the outbound Worker’s shard server. It may also find its way to other shard servers if any of those Workers invoked service bindings! Each of those shard servers can call the reportTraces() callback, and be confident that the data will make its way back to the right place: the dynamic dispatch Worker’s home server. None of those shard servers need to actually know where that home server is. Phew!
Eviction rates down, warm request rates up
Features like this are always satisfying to roll out, because they produce graphs showing huge efficiency gains.
Once fully rolled out, only about 4% of total requests from enterprise traffic ended up being sharded. To put that another way, 96% of all enterprise requests are to Workers which are sufficiently loaded that we must run multiple instances of them in a data center.

Despite that low total rate of sharding, we reduced our global Worker eviction rate by 10x.

Our eviction rate is a measure of memory pressure within our system. You can think of it like garbage collection at a macro level, and it has the same implications. Fewer evictions means our system uses memory more efficiently. This has the happy consequence of using less CPU to clean up our memory. More relevant to Workers users, the increased efficiency means we can keep Workers in memory for an order of magnitude longer, improving their warm request rate and reducing their latency.
The high leverage shown – sharding just 4% of our traffic to improve memory efficiency by 10x – is a consequence of the power-law distribution of Internet traffic.
A power law distribution is a phenomenon which occurs across many fields of science, including linguistics, sociology, physics, and, of course, computer science. Events which follow power law distributions typically see a huge amount clustered in some small number of “buckets”, and the rest spread out across a large number of those “buckets”. Word frequency is a classic example: A small handful of words like “the”, “and”, and “it” occur in texts with extremely high frequency, while other words like “eviction” or “trombone” might occur only once or twice in a text.
In our case, the majority of Workers requests goes to a small handful of high-traffic Workers, while a very long tail goes to a huge number of low-traffic Workers. The 4% of requests which were sharded are all to low-traffic Workers, which are the ones that benefit the most from sharding.
So did we eliminate cold starts? Or will there be an Eliminating Cold Starts 3 in our future?

For enterprise traffic, our warm request rate increased from 99.9% to 99.99% – that’s three 9’s to four 9’s. Conversely, this means that the cold start rate went from 0.1% to 0.01% of requests, a 10x decrease. A moment’s thought, and you’ll realize that this is coherent with the eviction rate graph I shared above: A 10x decrease in the number of Workers we destroy over time must imply we’re creating 10x fewer to begin with.
Simultaneously, our warm request rate became less volatile throughout the course of the day.
Hmm.
I hate to admit this to you, but I still notice a little bit of space at the top of the graph. 😟
Cloudflare's connectivity cloud protects entire corporate networks, helps customers build Internet-scale applications efficiently, accelerates any website or Internet application, wards off DDoS attacks, keeps hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.