文章探讨了C2PA(内容凭证联盟)在摄影和图像处理中的应用与挑战。作者通过实例展示了C2PA如何记录图像来源、编辑过程及生成AI的使用情况,并指出当前技术仍需改进以提升用户体验和隐私保护。文章强调了C2PA在社交媒体和专业出版物中验证内容真实性和来源的重要性,并对未来的技术发展持乐观态度。 2025-9-18 19:0:0 Author: www.tbray.org(查看原文) 阅读量:8 收藏
This is the blog version of my talk at the IPTC’s Photo Metadata Conference online conference. Its title is the one the conference organizers slapped on my session without asking; I was initially going to object but then I thought of the big guitar riff in Dire Straits’ Private Investigations and snickered. If you want, instead of reading, to watch me present, that’s on YouTube. Here we go.
Hi all, thanks for having me. Today I represent… nobody, officially. I’m not on any of the committees nor am I an employee of any of the providers. But I’m a photographer and software developer and social-media activist and have written a lot about C2PA. So under all those hats this is a subject I care about.
Also, I posted this on Twitter back in 2017.

I’m not claiming that I was the first with this idea, but I’ve been thinking about the issues for quite a while.
Enough self-introduction. Today I’m going to look at C2PA in practice right now in 2025. Then I’m going to talk about what I think it’s is for. Let’s start with a picture.

This smaller version doesn’t have C2PA,
but if you click on it, the larger version you get does.
Photo credit: Rob Pike
I should start by saying that a few of the things that I’m going to show you are, umm, broken. But I’m still a C2PA fan. Bear in mind that at this point everything is beta or preview or whatever, at best v1.0. I think we’re in glass-half-full mode.
This photo is entirely created and processed by off-the-shelf commercial products and has content credentials, and let me say that I had a freaking hard time finding such a photo. There are very few Content Credentials out there on the Internet. That’s because nearly every online photo is delivered either via social media or by professional publishing software. In both cases, the metadata is routinely stripped, bye-bye C2PA. So one of the big jobs facing us in putting Content Credentials to work is to stop publishers from deleting them.
Of course, that’s complicated. Professional publishers probably want the Content Credentials in place, but on social media privacy is a key issue and stripping the metadata is arguably a good default choice. So there are a lot of policy discussions to be had up front of the software work.
Anyhow, let’s look at the C2PA.

I open up that picture in Chrome and there are little “Cr” glyphs at both the top left and top right corners; that’s because I’ve installed multiple C2PA Chrome plug-ins. Turns out these seem to only be available for Chrome, which is irritating. Anyhow, I’ve clicked on the one in the top left.
That’s a little disappointing. It says the credentials were recorded by Lightroom, and gives my name, but I think it’s hiding way more than it’s revealing. Maybe the one on the top right will be more informative?

More or less the same info. A slightly richer presentation But both displays have an “inspect” button and both do the same thing. Let’s click it!

This is the Adobe Content Credentials inspector and it’s broken. That’s disappointing. Having said that, I was in a Discord chat with a senior Adobe person this morning and they’re aware of the problem.
But anyhow, I can drag and drop the picture like they say.

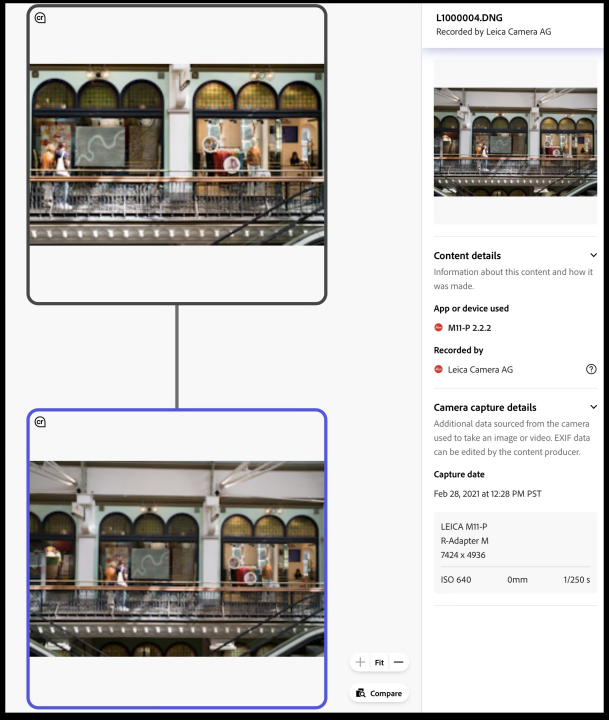
Much much better. It turns out that this picture was originally taken with a Leica M11. The photographer is a famous software guy named Rob Pike, who follows me on Mastodon and wanted to help out.
So, thanks Rob, and thanks also to the Leica store in Sydney, Australia, who loaned him the M11. He hasn’t told me how he arranged that, but I’m curious.
I edited it in Lightroom, and if you look close, you can see that I cropped it down and brightened it up. Let’s zoom in on the content credentials for the Leica image.

There’s the camera model, the capture date (which is wrong because Rob didn’t get around to setting the camera’s date before he took the picture.) The additional hardware (R Adapter-M), the dimensions, ISO, focal length, and shutter speed.
Speaking as a photographer, this is kind of cool. There’s a problem in that it’s partly wrong. The focal length isn’t zero, and Rob is pretty sure he didn’t have an adapter on. But Leica is trying to do the right thing and they’ll get there.
Now let’s look at the assertions that were added by Lightroom.

There’s a lot of interesting stuff in here, particularly the provenance. Lightroom lets you manage your identities, using what we call “OAuth flows”, so it can ask Instagram (with my permission) what my Instagram ID is. It goes even further with LinkedIn; it turns out that LinkedIn has an integration with the Clear ID people, the ones who fast-track you at the airport. So I set up a Clear ID, which required photos of my passport, and went through the dance with LinkedIn to link it up, and then with Lightroom so it knew my LinkedIn Id. So to expand, what it’s really saying is: “Adobe says that LinkedIn says that Clear says that the government ID of the person who posted this says that he’s named Timothy Bray”.
I don’t know about you, but this feels like pretty strong provenance medicine to me. I understand that the C2PA committee and the CAWG people are re-working the provenance assertions. To them: Please don’t screw this particular style of provenance up.
Now let’s look at what Lightroom says it did. It may be helpful to know what I in fact did.
Cropped the picture down.
Used Lightroom’s “Dehaze” tool because it looked a little cloudy.
Adjusted the exposure and contrast, and boosted the blacks a bit.
Sharpened it up.
Lightroom knows what I did, and you might wonder how it got from those facts to that relatively content-free description that reads like it was written by lawyers. Anyhow, I’d like to know. Since I’m a computer geek, I used the open-source “c2patool” to dump what the assertions actually are. I apologize if this hurts your eyes.
It turns out that there is way more data in those files than the inspector shows. For example, the Leica claims included 29 EXIF values, here are three I selected more or less at random:
"exif:ApertureValue": "2.79917", "exif:BitsPerSample": "16", "exif:BodySerialNumber": "6006238",
Some of these are interesting: In the Leica claims, the serial number. I could see that as a useful provenance claim. Or as a potentially lethal privacy risk. Hmmm.
{ "action": "c2pa.color_adjustments", "parameters": { "action": "c2pa.color_adjustments", "parameters": { "com.adobe.acr.value": "60", "com.adobe.acr": "Exposure2012" } }, { "action": "c2pa.color_adjustments", "parameters": { "com.adobe.acr": "Sharpness", "com.adobe.acr.value": "52" } }, { "action": "c2pa.cropped", "parameters": { "com.adobe.acr.value": "Rotated Crop", "com.adobe.acr": "Crop" } }
And in the Lightroom, it actually shows exactly what I did, see the sharpness and exposure values.
My feeling is that the inspector is doing either too much or too little. At the minimal end you could just say “hand processed? Yes/No” and “genAI? Yes/No”. For a photo professional, they might like to drill down and see what I actually did. I don’t see who would find the existing presentation useful. There’s clearly work to do in this space.
Oh wait, did I just say “AI”? Yes, yes I did. Let’s look at another picture, in this case a lousy picture.

I was out for a walk and thought the building behind the tree was interesting. I was disappointed when I pulled it up on the screen, but I still liked the shape and decided to try and save it.

So I used Lightroom’s “Select Sky” recover its color, and “Select Subject” to pull the building details out of the shadows. Both of these Lightroom features, which are pretty magic and I use all the time, are billed as being AI-based. I believe it.
Let’s look at what the C2PA discloses.

Having said all that, if you look at the C2PA (or at the data behind it) Lightroom discloses only “Color or Exposure”, “Cropping”, and “Drawing” edits. Nothing about AI.
Hmm. Is that OK? I personally think it is, and highlights the distinction between what I’d call “automation” AI and Generative AI. I mean, selecting the sky and subject is something that a skilled Photoshop user could accomplish with a lot of tinkering, the software is just speeding things up. But I don’t know, others might disagree.
Well, how about that generative AI?

Fails c2patool validation, “DigitalSourceType” is trainedAlgorithmicMedia

“DigitalSourceType” is compositeWithTrainedAlgorithmicMedia
The turtle is 100% synthetic, from ChatGPT, and on the right is a Pixel 10 shot on which I did a few edits including “Magic Eraser”. Both of these came with Content Credentials; chatGPT’s is actually invalid, but on the glass-half-full front, the Pixel 10’s were also invalid up until a few days ago, then they fixed it. So this stuff does get fixed.
I’m happy about the consistent use of C2PA terminology, they are clearly marking the images as genAI-involved.
I’m about done talking about the state of the Content Credentials art generally but I should probably talk about this device.
![]()
Because it marks the arrival of Content Credentials on the mass consumer market. Nobody knows how many Pixels Google actually sells but I guarantee it’s a lot more than Leica sells M11’s. And since Samsung tends to follow Google pretty closely, we’re heading for tens then hundreds of millions of C2PA-generating mobile devices. I wonder when Apple will climb on board?
Let’s have a look at that C2PA.

This view of the C2PA is from the Google Photos app. It’s very limited. In particular, there is nothing in there to support provenance. In fact, it’s the opposite, Google is bending over backward to do anything that could be interpreted as breaking the privacy contract by sharing information about the user.
Let’s pull back the covers and dig a little deeper. Here are a few notes
The device is identified just as “Pixel camera”. There are lots of different kinds of those!
The C2PA inclusion is Not optional!
DigitalSourceType:
computationalCapture(if no genAI)Timestamp is “untrusted”
The C2PA not being optional removes a lot of UI issues but still, well, I’m not smart enough to have fully thought through the implications. That Digital Source Type looks good and appropriate, and the untrusted-ness of the timestamp is interesting.
You notice that my full-workflow examples featured a Leica rather than the Pixel, and that’s because the toolchain is currently broken for me, neither Lightroom nor Photoshop can handle the P10 C2PA. I’ll skip the details, except to say that Adobe is aware of the bug, a version mismatch, and they say they’re working on it.
Before we leave the Pixel 10, I should say that there are plenty of alternate camera apps in Android and iOS, some quite good, and it’d be perfectly possible for them to ship much richer C2PA, notably including provenance, location, and so on.
I guess that concludes my look at the current state of the Content Credentials art. Now I’d like to talk about what Content Credentials are for. To start with, I think it’d be helpful to sort the assertions into three baskets.

Capture, that’s like that Leica EXIF stuff we showed earlier. What kind of camera and lens, what the shooting parameters were. Processing, that’s like the Lightroom report: How was the image manipulated, and by what software. Provenance: Which person or organization produced this?
But I think this picture has an important oversimplification, let me fix that.

Processing is logically where you’d disclose the presence of GenAI. And in terms of what people practically care about, that’s super important and deserves special consideration.
Now I’m going to leave the realm of facts and give you opinions. As for the Capture data there on the left… who cares? Really, I’m trying to imagine a scenario in which anyone cares about the camera or lens or F stop. I guess there’s an exception if you want to prove that the photo was taken by one of Annie Liebowitz’s cameras, but that’s really provenance.
Let’s think about a professional publication scenario. They get photos from photographers, employees or agencies or whatever. They might want to be really sure that the photo was from the photographer and not an imposter. So having C2PA provenance would be nice. Then when the publisher gets photos, they do a routine check of the provenance and if it doesn’t check out, they don’t run the picture without a close look first.
They also probably want to check for the “is there genAI?” indicator in the C2PA, and, well, I don’t know what they might do, but I’m pretty sure they’d want to know.
That same publisher might want to equip the photos they publish with C2PA, to demonstrate that they are really the ones who chose and provided the media. That assertion should be applied routinely by their content management system. Which should be easy, on the technology side anyhow.
So from the point of view of a professional publisher, provenance matters, and being careful about GenAI matters, and in the C2PA domain, I think that’s all that really matters.
Now let’s turn to Social Media, which is the source of most of the images that most people see most days. Today, all the networks strip all the photo metadata, and that decision involves a lot of complicated privacy and intellectual-property thinking. But there is one important FACT that they know: For any new piece of media, they know which account uploaded the damn thing, because that account owner had to log in to do it. So I think it’s a no-brainer that IF THE USER WISHES, they can have a Content Credentials assertion in the photo saying “Initially uploaded by Tim Bray at LinkedIn” or whoever at wherever.
What we’d like to achieve is that if you see some shocking or controversial media, you’d really want to know who originally posted it before you decided whether you believed it, and if Content Credentials are absent, that’s a big red flag. And if the picture is of the current situation in Gaza, your reaction might be different depending on whether it was originally from an Israeli military social-media account, or the Popular Front for the Liberation of Palestine, or by the BBC, or by [email protected].
Anyhow, here’s how I see it:

So for me, it’s the P and A in C2PA that matter – provenance and authenticity. I think the technology has the potential to change the global Internet conversation for the better, by making it harder for liars to lie and easier for truth-tellers to be believed. I think the first steps that have been taken so far are broadly correct and the path forward is reasonably clear. All the little things that are broken, we can fix ‘em.
And there aren’t that many things that matter more than promoting truth and discouraging lies.
And that’s all, folks.
如有侵权请联系:admin#unsafe.sh