
阿里推出旗舰级开源大模型Qwen3-Max,参数超万亿,在编程、智能体、数学推理等多领域表现全球前三。 2025-9-25 00:8:24 Author: www.iplaysoft.com(查看原文) 阅读量:44 收藏
要说最近 AI 圈让人兴奋的消息,除了 DeepSeek V3.1 Terminus 新版本发布外,那必须是阿里正式推出了旗舰级的「通义千问3」顶尖的 Qwen3-Max 万亿参数开源大模型!
阿里的这款 AI 模型一出,直接把国产大模型天花板又往上了一个台阶——不仅参数量突破 1 万亿,预训练数据高达 36T tokens,还在多个国际权威榜单上直接威胁了 OpenAI 的 GPT-5、Claude Opus 4 等旗舰模型的地位,实测成绩稳稳杀进全球前三,太厉害了……
阿里通义千问 Qwen3-Max 旗舰级开源模型发布!
Qwen3-Max 是“通义千问”系列中目前参数规模最大、综合能力爆强的开源基础大模型。简单来说,它就是阿里在大模型赛道上的“集大成之作”,瞄准的是顶级通用人工智能(AGI)的赛道。它的总参数量超过 1 万亿(1T)级别,非常的夸张!

现在,除了官网外,你也可以在 阿里云百炼平台、七牛云 或更多 第三方 API 平台接入,使用 ChatWise、Cherry Studio 等工具即可调用 Qwen3-Max 模型进行使用。
下面是我使用 ChatWise 调用阿里百炼的 API (有免费额度),回复速度非常之快!配合自定义 Prompt 指令可以完成做很多日常办公需求。我个人实测下来,直观的感受就是无论是代码能力还是写作能力均非常出色!
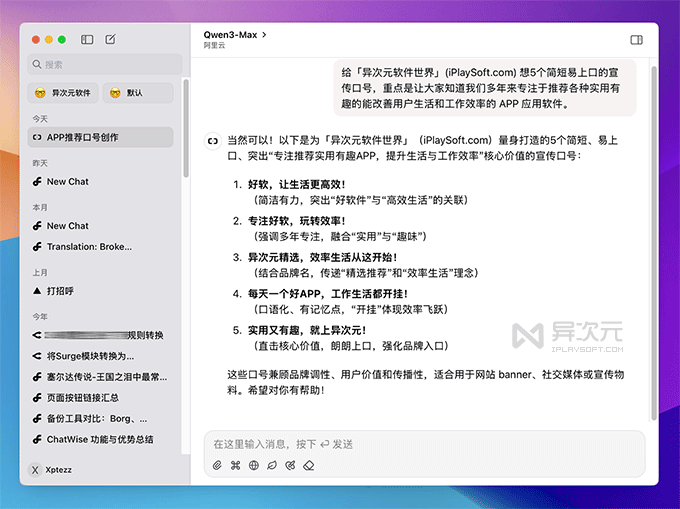
通义千问 3 Max 分为两个版本:Qwen3-Max-Instruct(指令版本)和 Qwen3-Max-Thinking(推理增强版本 / 暂未公开发布),有点类似 DeepSeek 的 V3 和 R1。
Qwen3-Max 版本 (Instruct 和 Thinking 区别)
Qwen3-Max 是阿里「通义千问」家族迄今为止参数规模最大的基础大模型,由阿里通义团队打造,定位为 旗舰级通用 AI 模型。它其实包含两个版本:
- Qwen3-Max-Instruct:(指令版本) 主打高效交互对话、指令遵循、编程、多语言理解和智能体(Agent)任务,适合日常对话、代码生成、工具调用等场景。
- Qwen3-Max-Thinking(深度思考版本):专攻高难度推理,比如数学证明、逻辑推演、复杂问题拆解,适合科研、竞赛、深度分析等“烧脑”任务。
这两个版本不是简单的“快与慢”之分,而是 任务导向完全不同。你可以理解为:Instruct (执行指令) 是“职场精英”,反应快、执行力强;Thinking (深度思考) 是“研究型学霸”,会花更多时间深思熟虑,解决更复杂的问题,追求极致准确。
通义千问3-Max 到底有多强大?看看实测数据:
Qwen3-Max 性能的强悍不是只靠吹的,而是实打实在多个国际基准测试中打出来的,下面看看 Max 模型的实测成绩:
✅ 编程能力:SWE-Bench Verified 得分 69.6,全球第一梯队!
这个测试可不是写个“Hello World”就算完,而是要求模型 自动修复真实 GitHub 项目中的 bug,涉及复杂代码理解、上下文推理和工程实现。69.6 分是什么水平?比肩甚至超越当前主流闭源模型,妥妥的代码界“六边形战士”。
✅ 智能体(Agent)能力:Tau2-Bench 得分 74.8,全球第一!
Tau2-Bench 专门测试模型能否像“数字员工”一样,自主调用工具、规划任务、与用户多轮交互完成目标。比如订机票、查数据、写报告一条龙。Qwen3-Max 不仅干得比 Claude Opus 4 好,还甩开 DeepSeek-V3.1 一大截,智能体能力直接拉满。
✅ 数学推理:AIME 25 & HMMT 双满分 100 分!
AIME(美国数学邀请赛)和 HMMT(哈佛-麻省理工数学竞赛)的题目,随便一道都能让高中生抓狂。而 Qwen3-Max-Thinking-Heavy 居然 全部答对!秘诀在于它 会调用代码解释器,把抽象数学问题转成可执行程序,再通过并行计算验证答案。这已经不是“会做题”,而是“会造工具做题”了。
✅ 综合文本能力:LMArena 排行榜 稳居全球前三
之前在人工盲测的 Chatbot Arena(LMArena)中,Qwen3-Max-Preview (预览版) 已经干到第三,仅次于 Gemini 2.5 和 GPT-5。而正式版据说还更强!
万亿参数 + MoE 架构 + 超稳训练

很多人会问:参数超万亿,会不会只是“堆料”?但 Qwen3-Max 的厉害之处,恰恰在于 不仅参数大,而且训练稳、效率高。
- 采用 MoE(Mixture of Experts)架构,在保证性能的同时控制推理成本。
- 训练过程 零 loss 尖刺、无需回退、不调数据分布,说明底层工程极其扎实。
- 使用 ChunkFlow 策略,支持 百万级上下文训练,长文本处理能力拉满。
- 在超大规模集群上,硬件故障导致的时间损失仅为上一代的 1/5,训练 MFU(Model FLOPs Utilization)提升 30%。
这些技术细节听起来很硬核,但翻译成人话就是:阿里不仅造出了大模型,还造得特别稳、特别高效。这背后是强大的工程能力和阿里云的基础设施支撑,不是光靠数据堆就能做到的。
怎样使用 Qwen3-Max?
🎯 适合人群 & 场景:
- 开发者:需要强大代码生成、bug 修复、API 调用能力。
- 科研人员 / 学生:处理复杂数学、逻辑推理、论文写作。
- 企业用户:构建智能客服、自动化工作流、AI Agent 应用。
- 普通用户:想体验强悍的中文大模型的对话、创作、分析能力。
🚀 如何体验?
好消息是——现在就能使用了!
- API 调用:通过七牛云、阿里云百炼平台、OpenRouter 等 API 接入,使用 ChatWise、Cherry Studio 等工具即可调用。
- 网页版体验:访问通义千问 qwen.ai 官网,直接和 Qwen3-Max-Instruct 聊天。
- Qwen3-Max-Thinking 目前还在训练中,但官方表示“即将发布”,值得蹲一波。
顺便提一嘴:Qwen3-Omni 也来了!
除了 Qwen3-Max,阿里这次还发布了 Qwen3-Omni——一个真正意义上的 多模态全能模型。它能同时处理 文本、图像、音频、视频,并且 一次生成多模态输出。比如你输入一段文字,它不仅能回复文字,还能同步生成对应的语音和视频画面,数字人、虚拟主播、教育课件 这类应用简直如虎添翼。
最后说两句:Scaling Law 还没到头!
有学者曾担心,随着数据和参数增长,大模型会撞上“天花板”。但 Qwen3-Max 的横空出世,用事实证明:只要方法对、工程强,Scaling Law 依然有效。从 0.5B 到超万亿参数,通义千问已经覆盖 300 多个模型,满足从手机端到超算中心的全场景需求。
最后:
其实不仅仅是阿里强大,DeepSeek、Kimi K2 等中国国产 AI 的实力也在不断地爆发。以前我们总追赶 ChatGPT、Claude 和 Google Gemini,现在,要别人来追我们的日子似乎越来越近了。
所以,别再问“国产大模型行不行”了。Qwen3-Max 已经把答案写在了排行榜上。现在就去阿里云百炼平台、七牛云 等更多 AI 大模型 API 平台或者通义千问官网试试吧!说不定能惊艳到你呢。
/ 关注 “异次元软件世界” 微信公众号,获取最新软件推送 /
如本文“对您有用”,欢迎随意打赏异次元,让我们坚持创作!
赞赏一杯咖啡
异次元软件世界、iPcFun.com 网站创始人。
本来名字很酷,但很无辜地被叫成小X,瞬间被萌化了。据说爱软件,爱网络,爱游戏,爱数码,爱科技,各种控,各种宅,不纠结会死星人,不折腾会死星人。此人属虚构,如有雷同,纯属被抄袭……
本文作者
如有侵权请联系:admin#unsafe.sh