本文探讨了Transformer和CNN在恶意URL识别中的应用。通过字符嵌入处理URL序列数据,并构建1D CNN和Transformer模型进行分类。实验结果表明两种方法均有效,并提出预处理、规则检测等改进方案提升准确率。 2025-9-20 04:47:53 Author: www.freebuf.com(查看原文) 阅读量:1 收藏
本文仅简单探究Transformer和CNN模型如何在恶意URL路径片段识别上的应用。考虑到防护设备上海量的恶意访问流量,如何简单高效的对其进行识别成为难题,目前例如护网中蓝方对于海量告警还需要依赖人工进行识别,这种方式效率低下且成本高昂,因此想到借助一些神经网络模型进行辅助,当然原先也考虑到使用LLM进行识别,但是大模型部署往往对硬件要求比较高,因此暂时只考虑利用其做识别辅助决策,来判断训练模型的识别准确率。
首先我们来看一下常规的URL访问路径,如:
正常流量:
/shop?item=book&category=science攻击流量:
/page?id=1; DROP TABLE
这种请求信息,我们人为可以直接很好的识别和区分,但是如何让模型(也就是机器)能处理它呢?这就需要去将这类由字符组成的数据(本质上是序列数据)转换成模型可以识别的数值向量序列,即“特征”。
那么一种简单高效的处理方式就是利用字符级嵌入(Character-level Embedding),将URL访问路径中的字符作为单元进行处理,从而转成向量序列。
大致的处理步骤可以概括为如下三步:Tokenization:将 URL 分割成单独的字符(或词)作为输入。
例如对于字符(
a-z,/,?,&,=,%...)将其映射为一个数值,然后再把字符串变成一个整数序列,由神经网络的Embedding层映射到向量空间/shop?item=book → [3, 12, 5, 9, 17, …] → Embedding → [[0.2,0.5], [0.1,0.3], …]
Padding:由于输入长度不固定,使用 padding 确保所有输入的长度一致。
字符嵌入:使用预训练的字符嵌入(如 fastText)或者直接使用 One-hot encoding。
CNN(卷积神经网络)
在数据处理中我们提及到这类由字符组成的URL访问路径本质上可以说就是一种序列数据,而对于序列数据处理经典的处理模型就是一维卷积神经网络(1D CNN),它是卷积神经网络的一种变体,专门用于处理序列数据,如时间序列、文本等,因此可以应用到我们的任务中。
简单介绍一下它的工作原理:
1D CNN的核心是卷积核,它会在整个字符序列上滑动,捕捉局部模式。
比如我们用kernel size = 3:
在序列上,它会同时看 3 个字符的组合。
如果序列里出现
"; D", "../", "UNION"等恶意模式,卷积核就能学到这种局部模式。
这就好比 CNN 在图像里学“边缘”“角点”,
在 URL 流量里学的就是 SQL 注入特征、路径遍历特征、命令注入特征。
Transformer 神经网络
将数据转换为序列
与CNN不同的是,Transformer 不直接看字符串,而是:
先用 tokenizer/embedding 把 URL 分成 token(如
/page, id=1, DROP, TABLE)。每个 token 被映射成一个向量,向量包含语义信息。
输入序列会被加上位置编码(positional encoding),让模型知道顺序关系。
例子:
/page?id=1; DROP TABLE
↓
["/page", "id=1", ";", "DROP", "TABLE"]
↓
[向量1, 向量2, 向量3, 向量4, 向量5]
特征学习
Transformer的特征学习核心是基于一种叫做自注意力机制(self-attention)的技术,其核心思想是在处理每个token的时候,不仅仅关注自身信息,还会根据“注意力权重”去关注序列中其他token的信息。
例如:针对恶意流量id=1; DROP TABLE,自注意力会让模型学会,DROP这个 token 需要强烈关注前面的 ; 或 id=1,因为它们通常一起出现才有攻击含义。而类似的在../../../../etc/passwd中,多个../的堆叠模式将被捕捉出来 → 说明是目录遍历攻击。
数据集准备
本次实战选用的数据集均收集于WAF平台以及常规业务URL,首先将攻击流量保存到black_log.txt,正常流量保存到white_log.txt,最后的验证流量文件b_w_f.txt中包含攻击流量和正常业务流量的随机组合。
数据集部分展示
black_log.txt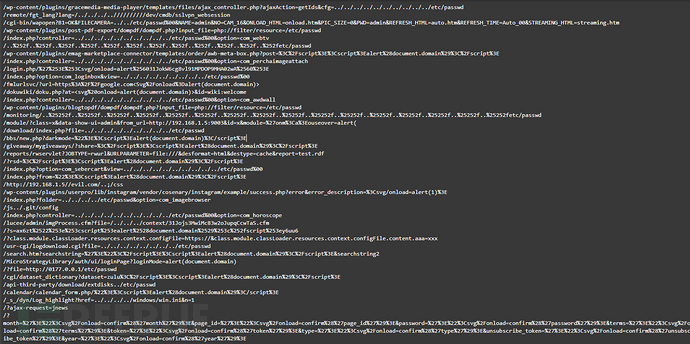
white_log.txt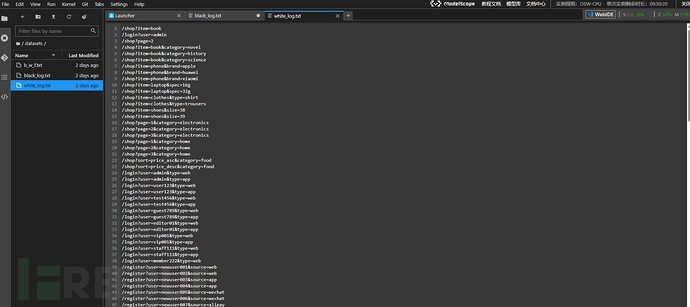
b_w_f.txt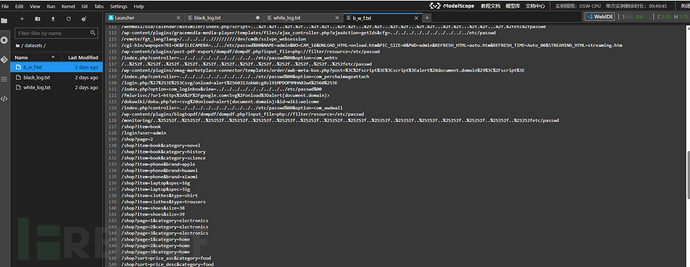
数据预处理
正如之前所说要把这些字符序列的数据处理为向量序列数据,因此要对数据进行预处理,大致思路就是先通过建立字符词表,即把所有 URL 拼接起来,提取其中出现过的字符,给每个字符分配一个索引(从 1 开始,0 作为 padding 用)。
def build_vocab(urls):
chars = set("".join(urls))
char2idx = {c: i+1 for i, c in enumerate(chars)} # 0: padding
return char2idx
然后再进行字符级编码,因为URL访问路径中的一些特殊字符是我们判断是否是恶意流量的关键(如://,../,?id=等),此外,一般的神经网络对于数据的输入往往会要求设置定长输入,因此对于长度不足的数据要设置填充。
def encode_url(url, char2idx, max_len=100):
seq = [char2idx.get(c, 0) for c in url[:max_len]]
if len(seq) < max_len:
seq += [0] * (max_len - len(seq))
return seq
对于我们设置的自定义数据集,则通过继承 torch.utils.data.Dataset 来自定义数据集的读取方式,并在使用 DataLoader 时设置 shuffle=True,从而在训练过程中实现数据的随机打乱。
class URLDataset(Dataset):
def __init__(self, urls, labels, char2idx, max_len=100):
self.urls = urls
self.labels = labels
self.char2idx = char2idx
self.max_len = max_len
def __len__(self):
return len(self.urls)
def __getitem__(self, idx):
x = torch.tensor(
encode_url(self.urls[idx], self.char2idx, self.max_len),
dtype=torch.long
)
y = torch.tensor(self.labels[idx], dtype=torch.float)
return x, y
模型结构
1D CNN模型
首先,假设对于B批长度为L的URL路径序列,首先通过Embedding层将序列的信息映射到E维的空间,从而更加详尽的扩充对于原始序列属性的表示(为了让后续模型可以更容易地把不同【恶意/攻击】流量区分开),即原始大小为[B,L]的序列数据经过Embedding层处理完之后变为了大小为[B,L,E]向量序列;
x = self.embedding(x) # [B, L, E]
x = x.permute(0, 2, 1) # [B, E, L]
随后利用卷积层的卷积核在序列上滑动,捕捉局部攻击特征(如 SQL 注入片段、目录穿越符号),
x = self.conv(x) # [B, C, L']
x = torch.relu(x)
再由最大池化层压缩特征,用于更聚焦关键特征信息(例如:在攻击流量识别中,关键的特征信息往往比细节更重要(比如 DROP TABLE 的存在比具体数字参数重要)。池化能突出这种显著特征。)
x = self.pool(x) # [B, C, L'//2]
最后经全连接层完成二分类预测。
x = x.view(x.size(0), -1) # Flatten
x = self.fc(x) # [B, 1]
return self.sigmoid(x)
整体的大致流程结构图如下图所示:
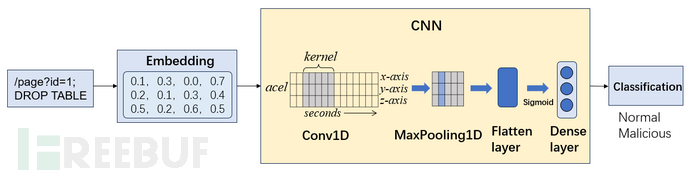
Transformer模型
另一方面,我们进一步考虑了引入Transformer 架构对网络流量序列进行建模处理,以识别潜在的恶意行为。首先,与1DCNN中一样,原始流量数据要经过预处理与特征提取,被转换为统一长度的序列输入。随后,这些序列将通过嵌入层(Embedding Layer)映射到高维特征空间,从而将原始离散特征表示为连续向量[B,L,E],其中 B 为批大小,L 为序列长度,E为嵌入维度。为了让模型理解数据序列中各个位置的顺序信息,就得依靠位置编码,其通过正弦和余弦函数计算,确保每个 token 的表示不仅依赖于其语义信息,还考虑其在序列中的相对位置。
# 位置编码
class PositionalEncoding(nn.Module):
"""
期望输入 x 的 shape 为 [seq_len, batch_size, d_model]
(这是 PyTorch Transformer 的默认格式,我们在 forward 中用的是这个格式)
"""
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
self.d_model = d_model
self.max_len = max_len
# 预先计算一个较大的位置编码缓存,注册为 buffer(不作为参数训练)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# pe shape: [max_len, d_model]
self.register_buffer('pe', pe) # 存在模型里,但不是可训练参数
def forward(self, x):
"""
x: [seq_len, batch_size, d_model]
返回 x + pe[:seq_len].unsqueeze(1) -> broadcast 到 [seq_len, batch, d_model]
如果 seq_len > max_len,则动态计算足够长度的 pe(避免越界)
"""
seq_len = x.size(0)
if seq_len <= self.pe.size(0):
pe = self.pe[:seq_len, :].to(x.device) # [seq_len, d_model]
else:
# 动态计算更长的 pe(不影响原先缓存)
position = torch.arange(0, seq_len, dtype=torch.float, device=x.device).unsqueeze(1)
div_term = torch.exp(torch.arange(0, self.d_model, 2, device=x.device).float() * -(math.log(10000.0) / self.d_model))
pe = torch.zeros(seq_len, self.d_model, device=x.device)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
return x + pe.unsqueeze(1) # [seq_len, 1, d_model] -> broadcast 到 [seq_len, batch, d_model]
接下来,嵌入后的向量序列将输入至多层堆叠的 Transformer 编码器(Transformer Encoder)中,其核心由多头自注意力机制(Multi-Head Self-Attention)和前馈网络(Feed-Forward Network, FFN)组成。
x = self.transformer_encoder(x) # [L, B, E]
多头注意力能够在不同子空间上并行学习序列中元素间的依赖关系,有效捕捉远距离上下文特征;而前馈网络则对经过注意力机制处理的特征进一步进行非线性变换与信息抽象。此外,每个子层间还进一步通过残差连接与层归一化(Layer Normalization)处理,以确保梯度稳定性和模型收敛性。
那么,通过这种层叠的注意力机制,模型能够逐层提取并强化潜在的攻击行为的特征。
在经过 Transformer 编码器的多层处理后,序列特征通过全局池化操作(如平均池化或 [CLS] 标记聚合)得到固定维度的向量表示。最后,该向量输入至全连接层与 sigmoid 激活函数,实现对流量的二分类输出,即区分正常流量与攻击流量。
x = x.permute(1, 0, 2).contiguous()# [B, L, E]
x = x.view(x.size(0), -1) # Flatten
x = self.fc(x) # [B, 1]
return self.sigmoid(x)
大致的结构流程如下图: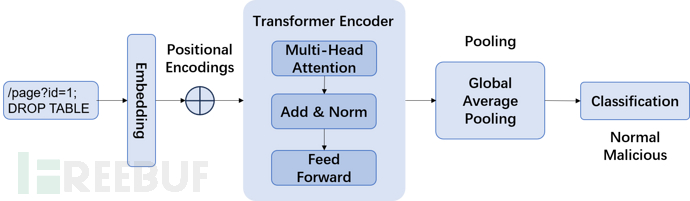
训练验证
下面就是针对模型的训练部分,由于我们现在的数据集规模还不是很大,我就只做了几千条数据,因此用cpu进行训练就够了,训练过程主要就是让模型去学习特征信息并保存最优权重,训练代码如下:
# ===================
# 3. 训练和验证
# ===================
if __name__ == "__main__":
# 数据
black_file = open(r'../datasets/black_log.txt','r', encoding='utf-8')
black = black_file.readlines()
white = open(r'../datasets/white_log.txt','r', encoding='utf-8')
white = white.readlines()
urls = black + white
labels = [1] * len(black) + [0] * len(white)
char2idx = build_vocab(urls)
X_train, X_val, y_train, y_val = train_test_split(
urls, labels, test_size=0.5, random_state=42
)
train_dataset = URLDataset(X_train, y_train, char2idx)
val_dataset = URLDataset(X_val, y_val, char2idx)
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=2)
# 使用修改后的 Transformer 模型
model = TransformerModel(vocab_size=len(char2idx))
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
best_f1 = 0.0
best_model_path = "best_transformer_model.pth"
# 训练
for epoch in range(10):
model.train()
total_loss = 0
for x, y in train_loader:
optimizer.zero_grad()
y_pred = model(x)
loss = criterion(y_pred.view(-1), y.view(-1))
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss={total_loss:.4f}")
# 验证
model.eval()
all_preds, all_labels = [], []
with torch.no_grad():
for x_val, y_val_batch in val_loader:
y_pred_prob = model(x_val)
y_pred = (y_pred_prob > 0.5).int()
all_preds.extend(y_pred.view(-1).cpu().numpy())
all_labels.extend(y_val_batch.view(-1).cpu().numpy())
acc = accuracy_score(all_labels, all_preds)
f1 = f1_score(all_labels, all_preds)
print(f"验证集: ACC={acc:.4f}, F1={f1:.4f}")
# 保存最佳模型
if f1 > best_f1:
best_f1 = f1
torch.save(model.state_dict(), best_model_path)
print(f"✅ 新最佳模型已保存: {best_model_path}, F1={f1:.4f}")
all_probs = []
all_preds = []
all_labels = []
with torch.no_grad():
for x_val, y_val_batch in val_loader:
y_prob = model(x_val)
y_pred = (y_prob > 0.5).int()
all_probs.extend(y_prob.view(-1).cpu().numpy()) # 保存预测概率
all_preds.extend(y_pred.view(-1).cpu().numpy()) # 保存预测标签
all_labels.extend(y_val_batch.view(-1).cpu().numpy()) # 保存真实标签
print("="*50)
训练结果如下: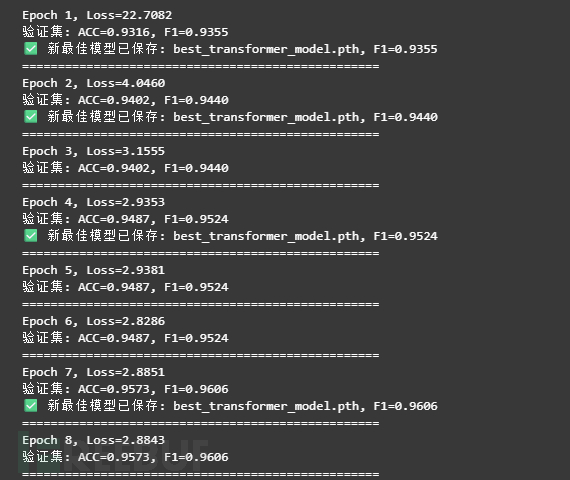
加载模型预测
为了验证我们训练模型的性能,并且让它有一定的实用价值,我们额外设置了一部分的数据用来让模型进行判别,具体来说,主要就是将黑白的路径数据均存入到b_w_f.txt中,然后加载模型对其中的数据进行判别,代码如下:
# ===================
# 加载模型 & 预测
# ===================
# 加载训练时保存的最佳模型
best_model = TransformerModel(vocab_size=len(char2idx))
best_model.load_state_dict(torch.load(best_model_path))
best_model.eval()
# 读取测试 URL
with open(r'../datasets/b_w_f.txt','r',encoding='utf-8') as f:
test_urls = [line.strip() for line in f if line.strip()]
# 对测试数据进行编码
test_encoded = torch.tensor([encode_url(u, char2idx) for u in test_urls], dtype=torch.long)
# 使用模型进行预测
with torch.no_grad():
preds = best_model(test_encoded)
preds_label = (preds > 0.5).int().view(-1).tolist()
# ===================
# 表格输出 & 统计
# ===================
malicious_count = sum(preds_label)
normal_count = len(preds_label) - malicious_count
# 打印预测结果表格
print(f"{'序号':<5} | {'URL':<60} | {'预测结果':<6}")
print("-"*80)
for i, (u, p) in enumerate(zip(test_urls, preds_label), 1):
result = "恶意" if p == 1 else "正常"
url_display = (u[:57] + "...") if len(u) > 60 else u # 截断长 URL
print(f"{i:<5} | {url_display:<60} | {result:<6}")
# 输出统计信息
print("\n总数:", len(test_urls))
print("预测为恶意:", malicious_count, f"({malicious_count/len(test_urls)*100:.2f}%)")
print("预测为正常:", normal_count, f"({normal_count/len(test_urls)*100:.2f}%)")
预测结果: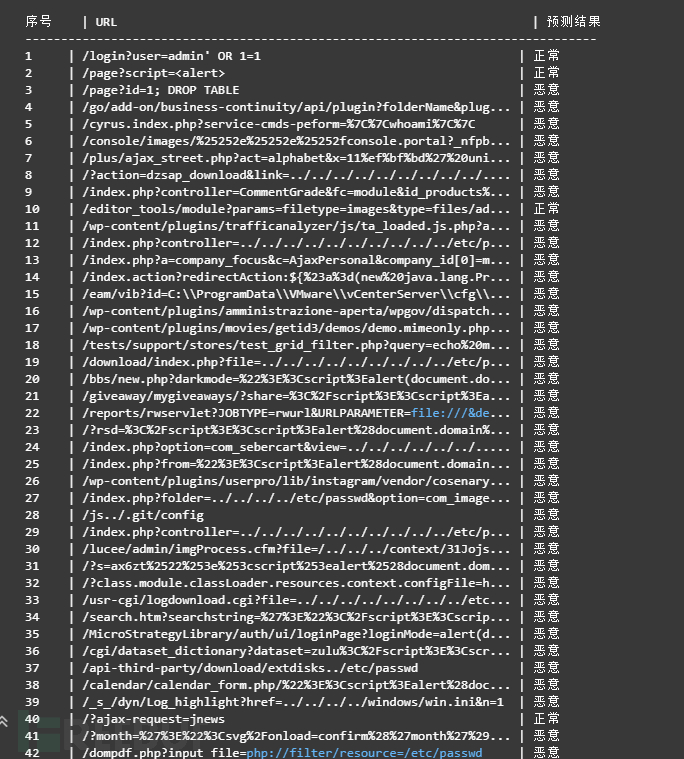
从预测结果初步来看,大部分都还是预测准确了,少部分数据,例如/login?user=admin' OR 1=1预测不准确,并不能直接表示训练的模型不准确。往往的攻击语句常被 URL-encoded、双重编码或以各种空格/大小写变体出现,如果训练与推理前没有统一做 decode、HTML unescape、unicode 规范化和空白归一化,模型看到的 token 就不一致;同时训练集中若缺乏足够的 OR 1=1、' OR 'a'='a 等等价写法的变体,模型就难以学到这些逻辑模式的共同特征。
为此,就需要通过增强样本和规范化输入即可逐步改善。
改进方案
数据编码
先对 URL 做 percent-decode、HTML-unescape、unicode normalize、去多余空白、统一小写(或保留大小写但要求一致)
# 放在数据加载/预测前使用
import urllib.parse, html, unicodedata, re
def preprocess_url(u, lower=True):
# decode percent-encoding(多次尝试解码)
s = u
for _ in range(2): # 一次或两次解码能处理常见双编码
s = urllib.parse.unquote(s)
s = html.unescape(s)
s = unicodedata.normalize("NFKC", s)
# collapse multiple spaces
s = re.sub(r"\s+", " ", s)
if lower:
s = s.lower()
return s.strip()
# 示例
print(preprocess_url("/login?user=admin%27%20OR%201=1"))
# -> "/login?user=admin' or 1=1"
规则检测
用几条正则捕获常见 SQLi/Tautology,作为高置信度规则直接标为恶意( cascade 方案:规则优先,模型复核其它)
import re
SQLI_PATTERNS = [
r"(?i)\bor\b\s+1\s*=\s*1", # or 1=1
r"(?i)union\s+select", # union select
r"(?i)select\s+.*\s+from", # select ... from
r"(?i)drop\s+table", # drop table
r"(--|#\s|/\*)", # sql comment markers
r"(?i)or\s+'.+'\s*=\s*'.+'", # or 'a'='a'
r"%27|%22|%3D", # encoded quotes / equal signs
]
COMPILED_SQLI = [re.compile(p) for p in SQLI_PATTERNS]
def rule_based_sqli(url):
for p in COMPILED_SQLI:
if p.search(url):
return True
return False
# 使用示例
u = preprocess_url("/login?user=admin%27%20OR%201=1")
print(rule_based_sqli(u)) # True
改进方案
# 在预测循环里:
for u in test_urls:
up = preprocess_url(u)
if rule_based_sqli(up):
label = 1 # 直接判恶意(或设置高置信度)
else:
enc = encode_url(up, char2idx) # 你的编码函数
prob = best_model(torch.tensor([enc], dtype=torch.long).to(device))
label = int(prob.item() > threshold)
数据增强
把常见变体合成进训练集(编码、大小写、空格替换、注释插入等)
import random, urllib.parse
def synth_sql_variants(url):
"""给一条带payload的样本生成若干常见变体"""
variants = set()
variants.add(url)
# percent-encode quotes/spaces
variants.add(urllib.parse.quote(url, safe="/=&?"))
# double-encode
variants.add(urllib.parse.quote(urllib.parse.quote(url, safe="/=&?"), safe="/=&?"))
# replace spaces with +
variants.add(url.replace(" ", "+"))
# uppercase/lowercase
variants.add(url.upper())
variants.add(url.lower())
# insert SQL comment at end
variants.add(url + " --")
# replace ' with %27 and vice versa
variants.add(url.replace("'", "%27"))
variants.add(url.replace("%27", "'"))
return list(variants)
# 用法:在训练数据中把这些变体附加为恶意样本
LLM辅助判别
通过调用大模型api来对判断结果做二次校验
# ===================
# 3. LLM 辅助核验
# ===================
API_URL = "api地址"
API_KEY = "" # TODO: 替换为你的真实 API Key
def llm_check(url, predicted_label):
"""
调用 GPT API 判断模型预测是否合理
返回 True = 正确, False = 错误
"""
result_str = "恶意" if predicted_label==1 else "正常"
prompt = f"""
你是一个网络安全专家。现在给你一个 URL 和模型预测的结果,请判断这个预测是否合理。
请只返回 "正确" 或 "错误"。
URL: {url}
模型预测: {result_str}
"""
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
data = {
"model": "gpt-3.5-turbo", # 可替换为 gpt-4o-mini / gpt-5
"messages": [{"role": "user", "content": prompt}],
"temperature": 0
}
response = requests.post(API_URL, headers=headers, data=json.dumps(data).encode('utf-8'))
if response.status_code != 200:
print(f"API请求失败: {response.status_code} {response.text}")
return False
resp_json = response.json()
# 提取 GPT 回复文本
reply = resp_json["choices"][0]["message"]["content"].strip()
return reply == "正确"
llm_correct = [llm_check(u, p) for u, p in zip(test_urls, preds_label)]
correct_count = sum(llm_correct)
incorrect_count = len(llm_correct) - correct_count
print("\nLLM 核验结果:")
print("正确预测:", correct_count, f"({correct_count/len(test_urls)*100:.2f}%)")
print("错误预测:", incorrect_count, f"({incorrect_count/len(test_urls)*100:.2f}%)")
写这篇文章主要是为了记录并分享尝试将先前阶段所学的神经网络与网络安全相结合的过程,以加深技术基础,并在此基础上探索更多可能的结合方案。在 AI 飞速发展和大模型普及的背景下,各领域与 AI 的融合已成为趋势。尽管目前直接使用 LLM 或已有模型即可较好地完成相关任务,但深入研究底层技术还是很有意义的哈。
一维卷积神经网络(1D-CNN)
基于Transformer的多模态异常检测实战
ET-BERT :一种针对加密流量分类的基于转换器的上下文数据报表示
如有侵权请联系:admin#unsafe.sh