


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序


1、研究背景
由于加密技术的普及,传统基于端口或统计特征的分类方法逐渐失效,而深度学习通过自动提取原始数据中的特征在一定程度上提升了分类效果,但其高度依赖于大量标注数据。 近年来兴起的基础模型则可以根据大量未标记数据进行预训练,并针对特定任务进行微调,但现有方法主要侧重于单个数据包内部特征的建模,往往忽略了数据包之间的关联性,难以有效捕捉更高层次的流级交互特征。同时,由于加密流量中的token语义信息有限,仅依赖token级特征容易丢失流量的整体模式和跨数据包的全局关系,导致对流量行为的表征能力受限。 为此,本文提出了一种面向加密流量分类的多实例Transformer(Multi-Instance Encrypted Traffic Transformer, MIETT),通过结合数据包注意力和流注意力双层注意力机制(Two-Level Attention, TLA)捕捉token级和数据包级特征。本文还引入了掩码流预测 (MFP)、数据包相对位置预测(Packet Relative Position Prediction, PRPP)和流对比学习(Flow Contrastive Learning, FCL)这三个预训练任务,以更准确地表示流的结构并区分来自不同流的数据包。实验结果表明,所提出方法在加密流量分类任务中相较于现有方法具有更优的性能表现。
2、MIETT模型架构
2.1 MIETT编码
MIETT架构中多实例流量数据的表示方法,主要包括tokenization、packet representation和flow representation三个关键步骤。首先,tokenization阶段通过对流量的十六进制序列进行bi-gram分词,每两个字节作为一个基本单元,再使用BPE进行编码,生成用于模型训练的token序列;然后,packet representation阶段将每个数据包表示为一个以[CLS]开头的token序列,并固定每个包的长度为128个token;最后,flow representation阶段将多个数据包的表示堆叠成一个三维张量,其中为数据包数量,为数据包长度,为嵌入维度。
2.2 MIETT总体架构
传统方法在将二维的流量token映射为一维输入时,容易丢失数据包顺序等时间信息,且计算复杂度随包数量和长度增长迅速上升。因此,MIETT引入TLA架构以保留流量的层次结构并提高计算效率,使其可以更有效地捕捉数据包内和数据包间的依赖关系。TLA层架构如下图:
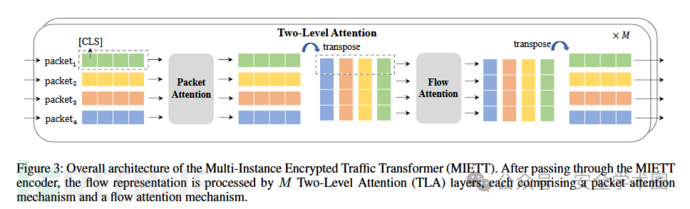
MIETT首先通过编码器将流量中的每个数据包表示为固定长度的token序列,多个数据包组成的流量则构成一个三维张量;随后,这个流量表示输入多个TLA层进行特征提取,而TLA则由两部分组成:第一层是数据包注意力(Packet Attention)机制,通过多头自注意力(Multi-Head Self-Attention, MHSA)机制捕捉单个包内不同token的关联关系;第二层是流注意力(Flow Attention)机制,在每个token位置上跨多个数据包进行自注意力建模,从而捕捉不同数据包之间的依赖关系。这种分层机制既保留了局部特征,又捕捉了全局结构。这种设计在有效建模复杂加密流量特征的同时,大幅降低了计算复杂度。
3、模型训练
MIETT模型的训练包括预训练和微调两个阶段:预训练阶段通过三个任务(MFP、PRPP和FCL)来帮助模型学习流量依赖、包序关系和流量特征差异;微调阶段则进一步优化模型,用于加密流量的最终分类。
3.1 预训练阶段
MIETT模型由多个TLA层组成,能有效捕捉数据包级和流级信息。预训练阶段,采用预训练的ET-BERT作为数据包注意力模块并保持冻结,同时训练流注意力模块以学习流的整体结构和依赖关系,实现对流级信息的强化。本文提出了三个预训练任务来强化模型性能,其结构如下图:
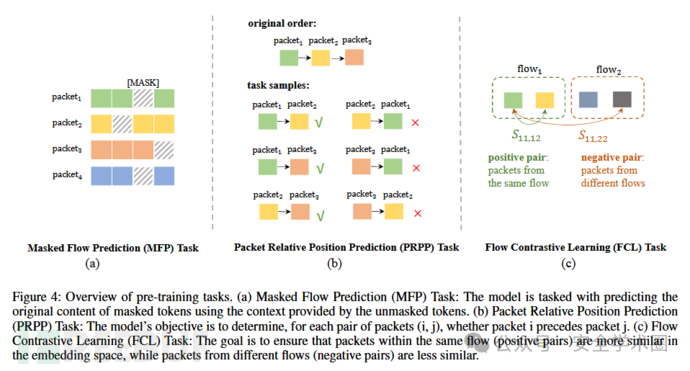
- MFP任务:通过随机遮蔽流中15%的token,训练模型利用未遮蔽的上下文预测被遮蔽内容,从而提升模型处理不完整流量信息的能力,帮助捕捉流的结构和依赖关系。
- PRPP任务:基于从每个数据包中提取的[CLS]嵌入,预测包在流中的相对顺序,帮助模型理解包的时序关系。PRPP通过线性变换和激活函数处理[CLS]嵌入,再计算包对间顺序的概率分布,并通过交叉熵损失与真实顺序进行比较,优化模型预测准确性。
- FCL任务:通过学习鲁棒的表示,增强模型区分不同流量流的能力。FCL使同一流中的包(正样本)在嵌入空间中更相似,不同流中的包(负样本)则更不相似,且比较基于相同包位置以保持一致性。具体方法是对每个包的[CLS]嵌入先经过MLP处理,再利用余弦相似度计算包间相似性,最后通过对比损失优化模型区分正负样本的能力。
预训练阶段的最终损失是以上三个损失的加权和: αβ
3.2 微调阶段
微调阶段的目标是将输入流量准确分类,在经过多个TLA层后,提取所有数据包的[CLS]嵌入向量,并通过平均池化聚合成整个流量的表示,该表示再经过MLP生成最终的分类结果。微调过程中,整个模型(包括此前冻结的数据包编码器和流编码器)均参与训练,采用最小化交叉熵损失的方式进行优化。
4、实验评估
4.1 实验设置
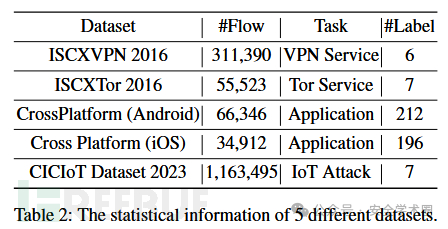
本文在ISCXVPN 2016、ISCXTor 2016、CrossPlatform(包含两个子集)和CIC IoT Dataset 2023五个加密流量分类数据集上评估所提出的方法。在预训练阶段使用通过Netbench预处理的五个数据集的训练集(不含标签),微调阶段根据不同任务进行分类,数据按8:1:1划分为训练集、验证集和测试集。在对比实验中,本文将所提出的方法和七种基准方法进行了比较。数据集的基本信息统计如下:
在预训练阶段,训练步数设置为150000步,并从前10个包中随机选取5个进行训练,MFP掩码比例为15%,MFP和PRPP任务权重均为0.2。在微调阶段,使用前5个包训练30个epoch。对于这两个阶段统一设置数据包长度为128,包数为5,嵌入维度为768,TLA层数为12,学习率为,优化器采用AdamW,所有实验均在配备两块 NVIDIA RTX A6000 GPU的服务器上进行。
4.2 实验结果
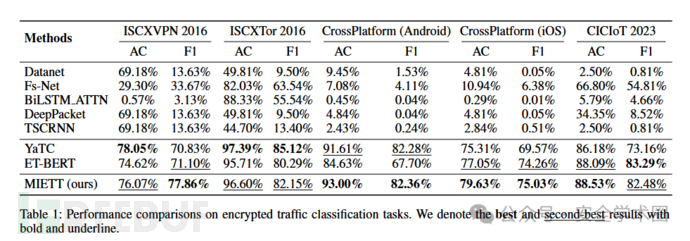
本文的主要评估指标为准确率和F1分数,实验结果表明,传统深度学习方法(如DataNet、DeepPacket、FS-Net等)在复杂数据集上泛化能力较差,尤其在CrossPlatform等多类别数据上F1分数较低。而MIETT模型在所有数据集上均显著提升了准确率和F1分数,尤其在CrossPlatform (Android)上,相较ET-BERT准确率提升8.27%,F1分数提升14.66%,验证了其对加密流量的有效建模能力。不同分类方法的性能对比如下:
5、本文贡献
- 提出了一种新颖的多实例加密流量转换器(MIETT)架构,并引入了双层注意力机制 (TLA),以有效捕捉流量流中token级和数据包级的关系。
- 引入了两项新型的预训练任务:数据包相对位置预测(PRPP)和流对比学习(FCL)。PRPP任务增强了模型对流内数据包顺序的理解,而FCL任务则提高了模型区分来自同一流和不同流的数据包的能力。
- 对所提出的MIETT模型在多个数据集上进行了广泛的实验验证,结果表明其分类性能优于多种现有方法。
免责声明
1.一般免责声明:本文所提供的技术信息仅供参考,不构成任何专业建议。读者应根据自身情况谨慎使用且应遵守《中华人民共和国网络安全法》,作者及发布平台不对因使用本文信息而导致的任何直接或间接责任或损失负责。
2. 适用性声明:文中技术内容可能不适用于所有情况或系统,在实际应用前请充分测试和评估。若因使用不当造成的任何问题,相关方不承担责任。
3. 更新声明:技术发展迅速,文章内容可能存在滞后性。读者需自行判断信息的时效性,因依据过时内容产生的后果,作者及发布平台不承担责任。
本文为 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf
客服小蜜蜂(微信:freebee1024)