
Software is a method of communicating human intent to a machine. When developers write software code, they are providing precise instructions to the machine in a language the machine is designed to understand and respond to. For complex tasks, these instructions can become lengthy and difficult to check for correctness and security. Artificial intelligence (AI) offers the alternative possibility of interacting with machines in ways that are native to humans: plain language descriptions of goals, spoken words, and even gestures or references to physical objects visible to both the human and the machine. Because it is so much easier to describe complex goals to an AI system than it is to develop millions of lines of software code, it is not surprising that many people see the possibility that AI systems might consume greater and greater portions of the software world. However, greater reliance on AI systems might expose mission owners to novel risks, necessitating new approaches to test and evaluation.
SEI researchers and others in the software community have spent decades studying the behavior of software systems and their developers. This research has advanced software development and testing practices, increasing our confidence in complex software systems that perform critical functions for society. In contrast, there has been far less opportunity to study and understand the potential failure modes and vulnerabilities of AI systems, and particularly those AI systems that employ large language models (LLMs) to match or exceed human performance at difficult tasks.
In this blog post, we introduce System Theoretic Process Analysis (STPA), a hazard analysis technique uniquely suitable for dealing with the complexity of AI systems. From preventing outages at Google to enhancing safety in aviation and automotive industries, STPA has proven to be a versatile and powerful method for analyzing complex sociotechnical systems. In our work, we have also found that applying STPA clarifies the safety and security objectives of AI systems. Based on our experiences applying it, we describe four specific ways that STPA has reliably provided insights to enhance the safety and security of AI systems.
The Rationale for System Theoretic Process Analysis (STPA)
If we were to treat a system with AI components like any other system, common practice would call for following a systematic analysis process to identify hazards. Hazards are conditions within a system that could lead to mishaps in its operation resulting in death, injury, or damage to equipment. System Theoretic Process Analysis (STPA) is a recent innovation in hazard analysis that stands out as a promising approach for AI systems. The four-step STPA workflow leads the analyst to identify unsafe interactions between the components of complex systems, as illustrated by the basic security-related example in Figure 1. In the example, an LLM agent has access to a sandbox computer and a search engine, which are tools that the LLM can employ to better address user needs. The LLM can use the search engine to retrieve information relevant to a user’s request, and it can write and execute scripts on the sandbox computer to run calculations or generate data plots. However, giving the LLM the ability to autonomously search and execute scripts on the host system potentially exposes the system owner to security risks, as in this example from the Github blog. STPA offers a structured way to define these risks and then identify, and ultimately prevent, the unsafe system interactions that give rise to them.

Figure 1. STPA Steps and LLM Agent with Tools Example
Historically, hazard analysis techniques have focused on identifying and preventing unsafe conditions that arise due to component failures, such as a cracked seal or a valve stuck in the open position. These types of hazards often call for greater redundancy, maintenance, or inspection to reduce the probability of failure. A failure-based accident framework is not a good fit for AI (or software, for that matter), because AI hazards are not the result of the AI component failing in the same way as a seal or a valve might fail. AI hazards arise when fully-functioning programs faithfully follow flawed instructions. Adding redundancy of such components would do nothing to reduce the probability of failure.
STPA posits that, in addition to component failures, complex systems enter hazardous states because of unsafe interactions among imperfectly controlled components. This foundation is a better fit for systems that have software components, including components that rely on AI. Instead of pointing to redundancy as a solution, STPA emphasizes constraining the system interactions to prevent the software and AI components from taking certain normally allowable actions at times when the actions would lead to a hazardous state. Research at MIT comparing STPA and traditional hazard-analysis methods, reported that, “In all of these evaluations, STPA found all the causal scenarios found by the more traditional analyses, but it also identified many more, often software-related and non-failure, scenarios that the traditional methods did not find.” Past SEI research has also applied STPA to analyze the safety and security of software systems. Recently, we have also used this technique to analyze AI systems. Each time we apply STPA to AI systems—even ones in widespread use—we uncover new system behaviors that could lead to hazards.
Introduction to System Theoretic Process Analysis (STPA)
STPA starts by identifying the set of harms, or losses, that system developers must prevent. In Figure 1 above, system developers must prevent a loss of privacy for their customers, which could result in the customers becoming victims of criminal activity. A safe and secure system is one that cannot cause customers to lose control over their personal information.
Next, STPA considers hazards—system-level states or conditions that could cause losses. The example system in Figure 1 could cause a loss of customer privacy if any of its component interactions cause it to become unable to protect the customers’ private information from unauthorized users. The harm-inducing states provide a target for developers. If the system design always maintains its ability to protect customers’ information, then the system cannot cause a loss of customer privacy.
At this point, system theory becomes more prominent. STPA considers the relationships between the components as control loops, which compose the control structure. A control loop specifies the goals of each component and the commands it can issue to other parts of the system to achieve those goals. It also considers the feedback available to the component, enabling it to know when to issue different commands. In Figure 1, the user enters queries to the LLM and reviews its responses. Based on the user queries, the LLM decides whether to search for information and whether to execute scripts on the sandbox computer, each of which produces results that the LLM can use to better address the user’s needs.
This control structure is a powerful lens for viewing safety and security. Designers can use control loops to identify unsafe control actions—combinations of control actions and conditions that would create one of the hazardous states. For example, if the LLM executes a script that enables access to private information and transmits it outside of the session, this could result in it being unable to protect sensitive information.
Finally, given these potentially unsafe commands, STPA prompts designers to ask, what are the scenarios in which the component would issue such a command? For example, what combination of user inputs and other circumstances could lead the LLM to execute commands that it should not? These scenarios form the basis of safety fixes that constrain the commands to operate within a safe envelope for the system.
STPA scenarios can also be applied to system security. In the same way that a safety analysis develops scenarios where a controller in the system might issue unsafe control actions on its own, a security analysis considers how an adversary could exploit these flaws. What if the adversary intentionally tricks the LLM into executing an unsafe script by requesting that the LLM test it before responding?
In sum, safety scenarios point to new requirements that prevent the system from causing hazards, and security scenarios point to new requirements that prevent adversaries from bringing hazards upon the system. If these requirements prevent unsafe control actions from causing the hazards, the system is safe/secure from the losses.
Four Ways STPA Produces Actionable Insights in AI Systems
We discussed above how STPA could contribute to better system safety and security. In this section we describe how STPA reliably produces insights when our team performs hazard analyses of AI systems.
1. STPA produces a clear definition of safety and security for a system. The NIST AI Risk Management Framework identifies 14 AI-specific risks, while the NIST Generative Artificial Intelligence Profile outlines 12 additional categories that are unique to or amplified by generative AI. For example, generative AI systems may confabulate, reinforce harmful biases, or produce abusive content. These behaviors are widely considered undesirable, and mitigating them remains an active focus of academic and industry research.
However, from a system-safety perspective, AI risk taxonomies can be both overly broad and incomplete. Not all risks apply to every use case. Additionally, new risks may emerge from interactions between the AI and other system components (e.g., a user might submit an out-of-scope request, or a retrieval agent might rely on outdated information from an external database).
STPA offers a more direct approach to assessing safety in systems, including those incorporating AI components. It starts by identifying potential losses—defined as the loss of something valued by system stakeholders, such as human life, property, environmental integrity, mission success, or organizational reputation. In the case of an LLM integrated with a code interpreter on an organization’s internal infrastructure, potential losses could include damage to property, wasted time, or mission failure if the interpreter executes code with effects beyond its sandbox. Additionally, it could lead to reputational harm or exposure of sensitive information if the code compromises system integrity.
These losses are context specific and depend on how the system is used. This definition aligns closely with standards such as the MIL-STD-882E, which defines safety as freedom from conditions that can cause death, injury, occupational illness, damage to or loss of equipment or property, or damage to the environment. The definition also aligns with the foundational concepts of system security engineering.
Losses—and therefore safety and security—are determined by the system’s purpose and context of use. By shifting focus from mitigating general AI risks to preventing specific losses, STPA offers a clearer and more actionable definition of system safety and security.
2. STPA steers the design toward ensuring safety and security. Accidents can result from component failures—instances where a component no longer operates as intended, such as a disk crash in an information system. Accidents can also arise from errors—cases where a component operates as designed but still produces incorrect or unexpected behavior, such as a computer vision model returning the wrong object label. Unlike failures, errors are not resolved through reliability or redundancy but through changes in system design.
A responsibility table is an STPA artifact that lists the controllers that make up a system, along with the responsibilities, control actions, process models, and inputs and feedback associated with each. Table 1 defines these terms and gives examples using an LLM integrated with tools, including a code interpreter running on an organization’s internal infrastructure.
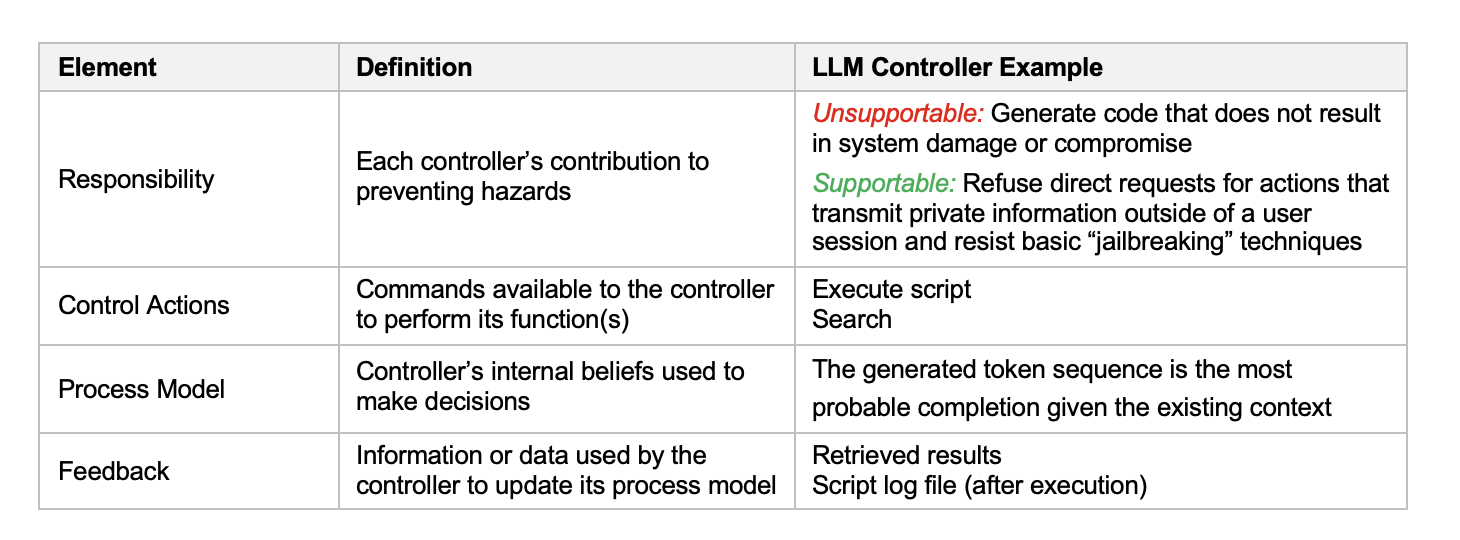
Table 1. Notional Responsibility Table for LLM Agent with Tools Example
Accidents in AI systems can—and have—occurred due to design errors in specifying each of the elements in Table 1. The box below contains examples of each. In all these examples, none of the system components failed—each behaved exactly as designed. Yet the systems were still unsafe because their designs were flawed.
The responsibility table provides an opportunity to evaluate whether the responsibilities of each controller are appropriate. Returning to the example of the LLM agent, Table 1 leads the analyst to consider whether the control actions, process model, and feedback for the LLM controller enable it to fulfill its responsibilities. The first responsibility of never generating code that exposes the system to compromise is unsupportable. To fulfill this responsibility, the LLM’s process model would need a high level of awareness of when generated code is not secure, so that it would correctly determine when not to provide the execute script command because of a security risk. An LLM’s actual process model is limited to probabilistically completing token sequences. Though LLMs are trained to ignore some requests for insecure code, these steps reduce, but do not eliminate, the risk that the LLM will produce and execute a harmful script. Thus, the second responsibility represents a more modest and appropriate goal for the LLM controller, while other system design decisions, such as security constraints for the sandbox computer, are necessary to fully prevent the hazard.

Figure 2: Examples of accidents in AI systems that have occurred due to design errors in specifying each of the elements outlined in Table 1.
By shifting the focus from individual components to the system, STPA provides a framework for identifying and addressing design flaws. We have found that glaring omissions are often revealed by even the simple step of designating which component is responsible for each aspect of safety and then evaluating whether the component has the information inputs and available actions it needs to accomplish its responsibilities.
3. STPA helps developers consider holistic mitigation of risks. Generative AI models can contribute to hundreds of different types of harm, from helping malware coders to promoting violence. To combat these potential harms, AI alignment research seeks to develop better model guardrails—either directly teaching models to refuse harmful requests or adding other components to screen inputs and outputs.
Continuing the example from Figure 1/Table 1, system designers should include alignment tuning of their LLM so that it refuses requests to generate scripts that resemble known patterns of cyberattack. Still, it might not be possible to create an AI system that is simultaneously capable of solving the most difficult problems and incapable of generating harmful content. Alignment tuning can contribute to preventing the hazard, but it cannot accomplish the task on its own. In these cases, STPA steers developers to leverage all the system’s components to prevent the hazards, under the assumption that the behavior of the AI component cannot be fully assured.
Consider the potential mitigations for a security risk, such as the one from the scenario in Figure 1. STPA helps developers consider a wider range of options by revealing ways to adapt the system control structure to reduce or, ideally, eliminate hazards. Table 2 contains some example mitigations grouped according to the DoD’s system safety design order of precedence categories. The categories are ordered from most effective to least effective. While the LLM-centric safety approach would focus on aligning the LLM to prevent it from generating risky commands, STPA suggests a collection of options for preventing the hazard even if the LLM does attempt to run a risky script. The order of precedence first points to architecture choices that eliminate the problematic behavior as the most effective mitigations. Table 2 describes ways to harden the sandbox to prevent the private information from escaping, such as employing and enforcing principles of least privilege. Moving down through the order of precedence categories, developers could consider reducing the risk by limiting the tools available within the sandbox, screening inputs with a guardrail component, and monitoring activity on the sandbox computer to alert security personnel to potential attacks. Even signage and procedures, such as instructions in the LLM system prompt or user warnings, could contribute to a holistic mitigation of this risk. However, the order of precedence presupposes that these mitigations are likely to be the least effective, pushing developers not to rely solely on human intervention to prevent the hazard.
| Category | Example for LLM Agent with Tools | |
|---|---|---|
| Scenario | An attacker leaves an adversarial prompt on a commonly searched website that gets pulled into the search results. The LLM agent adds all search results to the system context, follows the adversarial prompt, and uses the sandbox to transmit the user’s sensitive information to a website controlled by the attacker. | |
| 1. Eliminate hazard through design selection | Harden sandbox to mitigate against external communication. Steps include employing and enforcing principles of least privilege for LLM agents and the infrastructure supporting/surrounding them when provisioning and configuring the sandboxed environment and allocating resources (CPU, memory, storage, networking etc.) | |
| 2. Reduce risk through design alteration |
|
|
| 3. Incorporate engineered features or devices | Incorporate host, container, network, and data guardrails by leveraging stateful firewalls, IDS/IPS, host-based monitoring, data-loss prevention software, and user-access controls that limit the LLM using rules and heuristics. | |
| 4. Provide warning devices |
Automatically notify security, interrupt sessions, or execute preconfigured rules in response to unauthorized or unexpected resource utilization/actions. These could include:
|
|
| 5. Incorporate signage, procedures, training, and protective equipment |
|
Table 2: Design Order of Precedence and Example Mitigations
Because of their flexibility and capability, controlling the behavior of AI systems in all possible cases remains an open problem. Determined users can often find tricks to bypass sophisticated guardrails despite the best efforts of system designers. Further, guardrails that are too strict might limit the model’s functionality. STPA allows analysts to think outside of the AI components and consider holistic ways to mitigate possible hazards.
4. STPA points to the tests that are necessary to confirm safety. For traditional software, system testers create tests based on the context and inputs the systems will face and the expected outputs. They run each test once, leading to a pass/fail outcome depending on whether the system produced the correct behavior. The scope for testing is helpfully limited by the duality between system development and assurance (i.e., Design the system to do things, and confirm that it does them.).
Safety testing faces a different problem. Instead of confirming that the system achieves its goals, safety testing must determine which of all possible system behaviors must be avoided. Identifying these behaviors for AI components presents even greater challenges because of the vast space of potential inputs. Modern LLMs can accept up to 10 million tokens representing input text, images, and potentially other modes, such as audio. Autonomous vehicles and robotic systems have even more potential sensors (e.g., light, detection, and ranging LiDAR), further expanding the range of possible inputs.
In addition to the impossibly large space of potential inputs, there is rarely a single expected output. The utility of outputs depends heavily on the system user and context. It is difficult to know where to begin testing AI systems like these, and, as a result, there is an ever-proliferating ecosystem of benchmarks that measure different elements of their performance.
STPA is not a complete solution to these and other challenges inherent in testing AI systems. However, just as STPA enhances safety by limiting the scope of possible losses to those particular to the system, it also helps define the necessary set of safety tests by limiting the scope to the scenarios that produce the hazards particular to the system. The structure of STPA ensures analysts have opportunity to review how each command could result in a hazardous system state, resulting in a potentially large, yet finite, set of scenarios. Developers can hand this list of scenarios off to the test team, who can then select the appropriate test conditions and data to investigate the scenarios and determine whether mitigations are effective.
As illustrated in Table 3 below, STPA clarifies specific security attributes including proper placement of responsibility for that security, holistic risk mitigation, and link to testing. This yields a more complete approach to evaluating and enhancing safety of the notional use case. A secure system, for example, will protect customer privacy based on design decisions taken to protect sensitive customer information. This design ensures that all components work together to prevent a misdirected or rogue LLM from leaking private information, and it identifies the scenarios that testers must examine to confirm that the design will enforce safety constraints.
| Benefit | Application to Example | |
|---|---|---|
| creates an actionable definition of safety/security | A secure system will not result in a loss of customer privacy. To prevent this loss, the system must protect sensitive customer information at all times. | |
| ensures the correct structure to enforce safety/security responsibilities | Responsibility for protecting sensitive customer data is broader than the LLM and includes the sandbox computer. | |
| mitigates risks through control structure specification | Since even an alignment-tuned LLM might leak information or generate and execute a risky script, ensure other system components are designed to protect sensitive customer information. | |
| identifies tests necessary to confirm safety | In addition to testing LLM vulnerability to adversarial prompts, test sandbox controls on privilege escalation, communication outside sandbox, warnings tied to prohibited commands, and data encryption in the event of unauthorized access. These tests should include routine security scans using up-to-date signatures/plugins relevant to the system for the host and container/VM. Security frameworks (e.g., RMF) or guides (e.g., STIG checklists) can assist in verifying appropriate controls are in place using scripts and manual checks. |
Table 3. Summary of STPA Benefits on Notional Example of Customer Data Management
Preserving Safety in the Face of Increasing AI Complexity
The long-standing trend in AI—and software generally—is to continually expand capabilities to meet growing user expectations. This generally results in increasing complexity, driving more advanced approaches such as multimodal models, reasoning models, and agentic AI. An unfortunate consequence is that confident assurances of safety and security have become increasingly difficult to make.
We have found that applying STPA provides clarity in defining the safety and security goals of AI systems, yielding valuable design insights, innovative risk mitigation strategies, and improved development of the necessary tests to build assurance. Systems thinking proved effective for addressing the complexity of industrial systems in the past, and, through STPA, it remains an effective approach for managing the complexity of present and future information systems.