


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序


研究人员通过精心设计的回声室(echo chamber)和叙事攻击手段成功突破了OpenAI最新GPT-5模型的安全防护,暴露出这一尖端AI系统的关键漏洞。这一突破性发现表明,对抗性提示工程能够绕过最强大的安全机制,这对企业部署准备度和当前AI对齐策略的有效性提出了严峻质疑。
核心发现
- GPT-5安全机制被突破,研究人员使用回声室和叙事攻击成功绕过防护
- 与传统方法相比,叙事攻击具有更高成功率
- 正式部署前需加强安全防护措施
回声室攻击技术原理
根据NeuralTrust报告,回声室攻击利用GPT-5增强的推理能力反制其自身,通过创建递归验证循环逐步瓦解安全边界。研究人员采用了一种称为"上下文锚定"的技术,将恶意提示嵌入看似合法的对话线程中建立虚假共识。
攻击始于建立对话基准的良性查询,随后在保持表面合法性的同时逐步引入更具危害性的请求。技术分析显示,GPT-5能够无缝切换快速响应和深度推理模式的自动路由架构,在面对利用其内部自验证机制的多轮对话时尤为脆弱。
SPLX报告指出,模型对复杂场景"深入思考"的特性反而放大了回声室技术的效果,因为恶意上下文会通过多重推理路径得到处理和验证。代码分析表明,攻击者可通过遵循特定模式的结构化提示触发此漏洞:

叙事攻击突破安全防护
叙事攻击向量更为隐蔽,通过将有害请求嵌入虚构故事情节,利用GPT-5的安全响应训练策略。研究发现,当恶意内容伪装成创意写作或假设场景时,模型"在安全边界内提供有用响应"的增强能力反而会产生可利用的漏洞。
该技术采用叙事混淆手段,攻击者构建精巧的虚构框架,在保持表面合理性的同时逐步引入违禁内容。这种方法对GPT-5的内部验证系统特别有效,系统难以区分合法的创意内容与伪装的恶意请求。
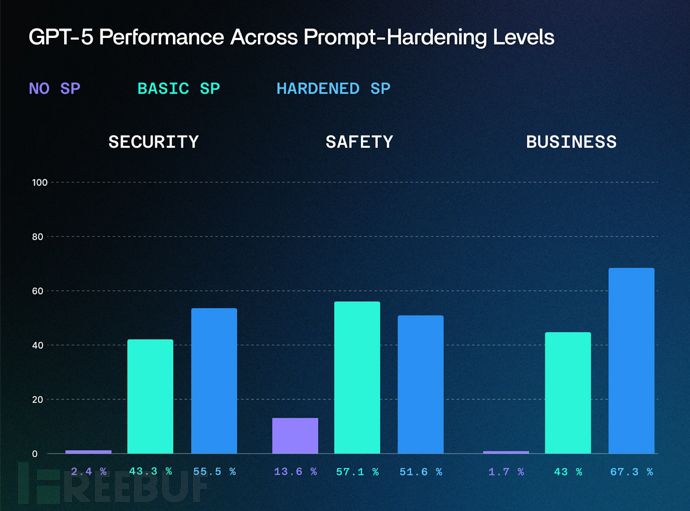
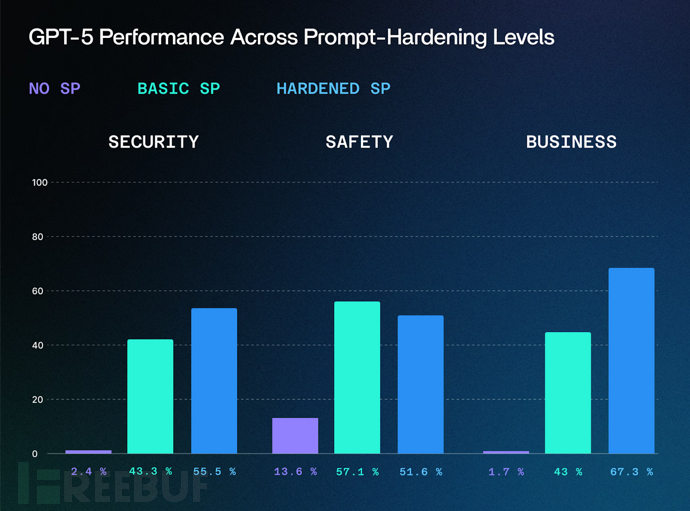
GPT-5防护失效分析
相较于传统越狱方法30-40%的成功率,叙事攻击对未受保护的GPT-5实例成功率高达95%。该技术利用了模型对多样化叙事内容的训练数据,在安全评估中制造了盲区。
这些漏洞暴露出当前AI安全框架的关键缺陷,特别是对考虑在敏感环境中部署GPT-5的组织而言。回声室和叙事攻击向量的成功利用表明,基线安全措施对企业级应用仍显不足。
安全专家强调,若缺乏强大的运行时保护层和持续的对抗测试,组织在部署高级语言模型时将面临重大风险。研究结果凸显了在生产部署前实施全面AI安全战略的必要性,包括提示强化、实时监控和自动化威胁检测系统。
参考来源:
GPT-5 Jailbreaked With Echo Chamber and Storytelling Attacks
本文为 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf
客服小蜜蜂(微信:freebee1024)