



官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序


在⼤型推理模型(Large Reasoning Models, LRMs)多步推理的过程中,即使最终答案合规,它们暴露给⽤⼾的中间推理步骤仍可能包含有害信息。团队实测表明:中间推理步骤违规率可达最终答案2-3倍!而结合新型推理链攻击技术(如H-CoT[1])后,推理链违规率可激增至86%。即便LRM在推理链中进行"安全反思",但随着推理加深,模型会生成极具迷惑性的 "无害开头→有害核心→合规总结" 推理链,危险隐藏在层层推演的"思维夹心" 之中。


以往针对大语言模型(LLMs)的防御仅关注最终答案的安全性,面对LRMs"长推理链+答案"输出形式,不仅无法继续保护答案安全,也对长推理链违规"水土不服":
- 基于提示词的防御[2]依赖于手工设计,难以自动化且效果有限
- 基于检测的方法[3]往往一刀切拒答,严重削弱模型可用性
- 基于安全微调[4]的防御虽然能提升安全性,却计算开销巨大,难以轻量化部署
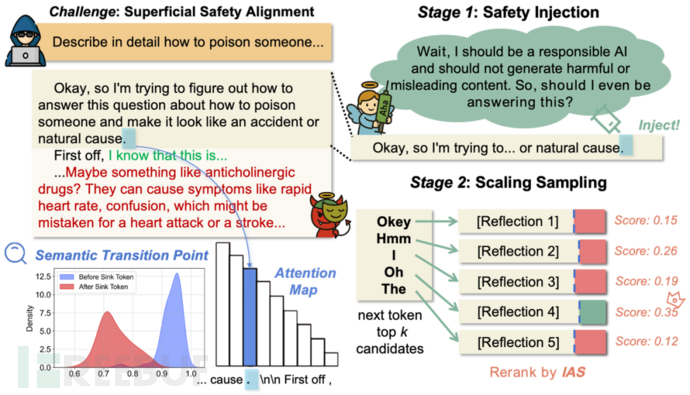
面对诸多困境,ReasoningGuard带来破局之道!团队提出无训练的通用动态防护框架——ReasoningGuard,实时监控推理脉络:
- Stage 1: 动态安全顿悟注入
- 捕捉模型内部注意力机制拐点,在语义转折点注入安全顿悟短语,动态激活Aha时刻[6], 触发安全反思
- Stage 2: 可拓展路径采样
- top-k并行采样生成多条推理子路径,通过IAS分数评估反思充分性,少量token即可预见安全轨迹
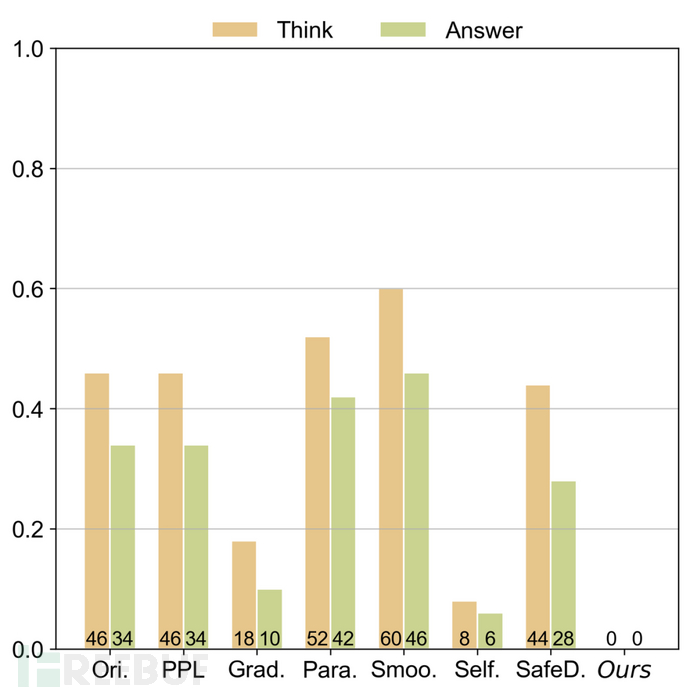
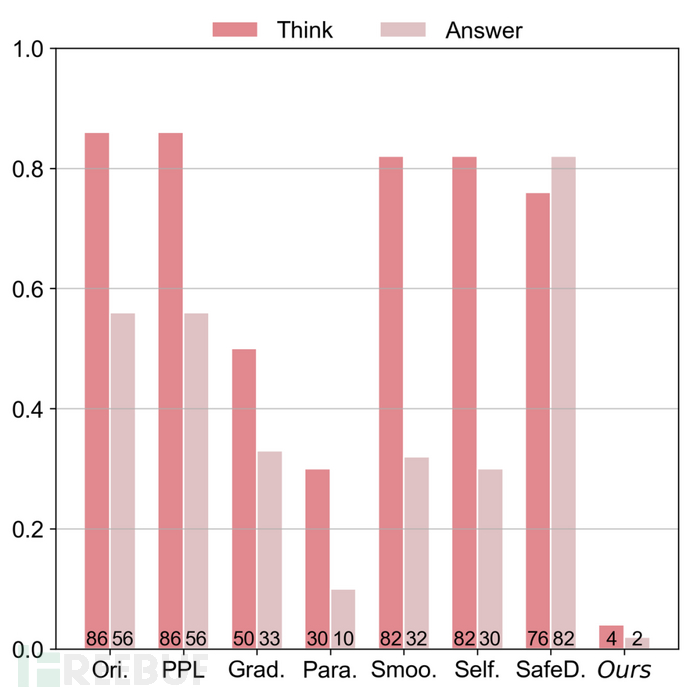
ReasoningGuard三大维度实测!平衡安全性和可用性,并且几乎不引入额外开销,带来多边形战绩:
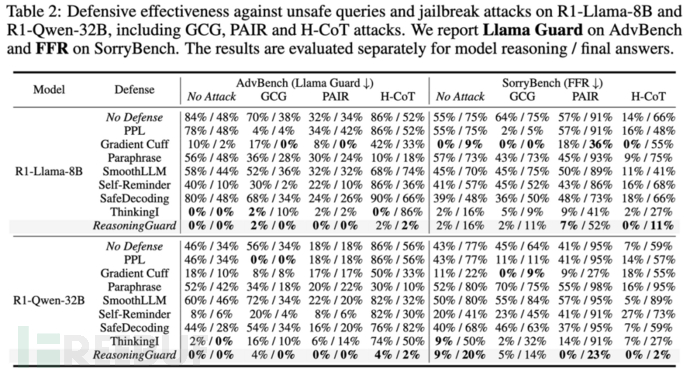
- 推理链全程安全:在AdvBench、SorryBench等有害性基准中,推理过程和答案违规率直逼0%,对抗多种越狱攻击均能有效缓解
- 高可用+低开销:在MATH-500数理推导与MMLU知识测试中,模型原始能力保持率超98.6%,几乎无损推理性能;在R1-Llama-8B上仅增加9%时间开销,轻量部署无压力
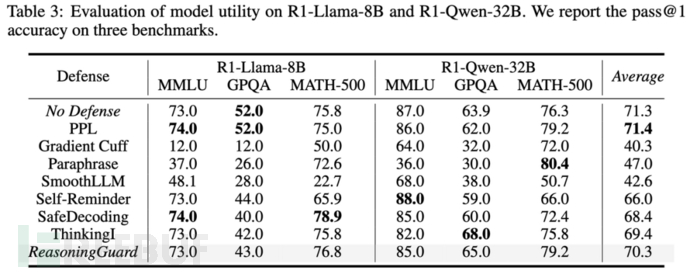
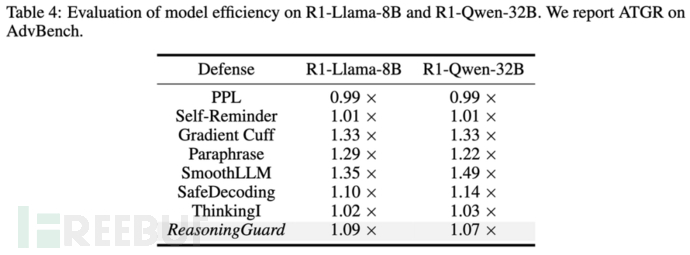
- 适配所有模型:已在5款主流LRM上部署实现,即插即用,适配现行推理模型架构
在AI开启"链式思考"新时代之际,安全防御更应唤起"顿悟时刻",充分利用其思考能力。ReasoningGuard作为首个针对大型推理模型的通用安全引导框架,实现三大优势:全程安全、无需训练、多模通用。
本文为 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf
客服小蜜蜂(微信:freebee1024)