众所周知,LLM只能通过上下文进行交互,并不具备主动接触外界的功能。
因此LLM要靠“嘴”来调用给它准备好的工具,也就是tool-call—关于tool-call起源,从function calling的诞生,一直到了MCP的出现,请看我的web3与AI的接口一文:

关于这个提一个我以为很多人都知道,但在公司讲课过程中发现其实大家不知道的agent开发的重点技巧:tool-call,无论是function_calling还是MCP调用,都是分显式和隐式两种的。

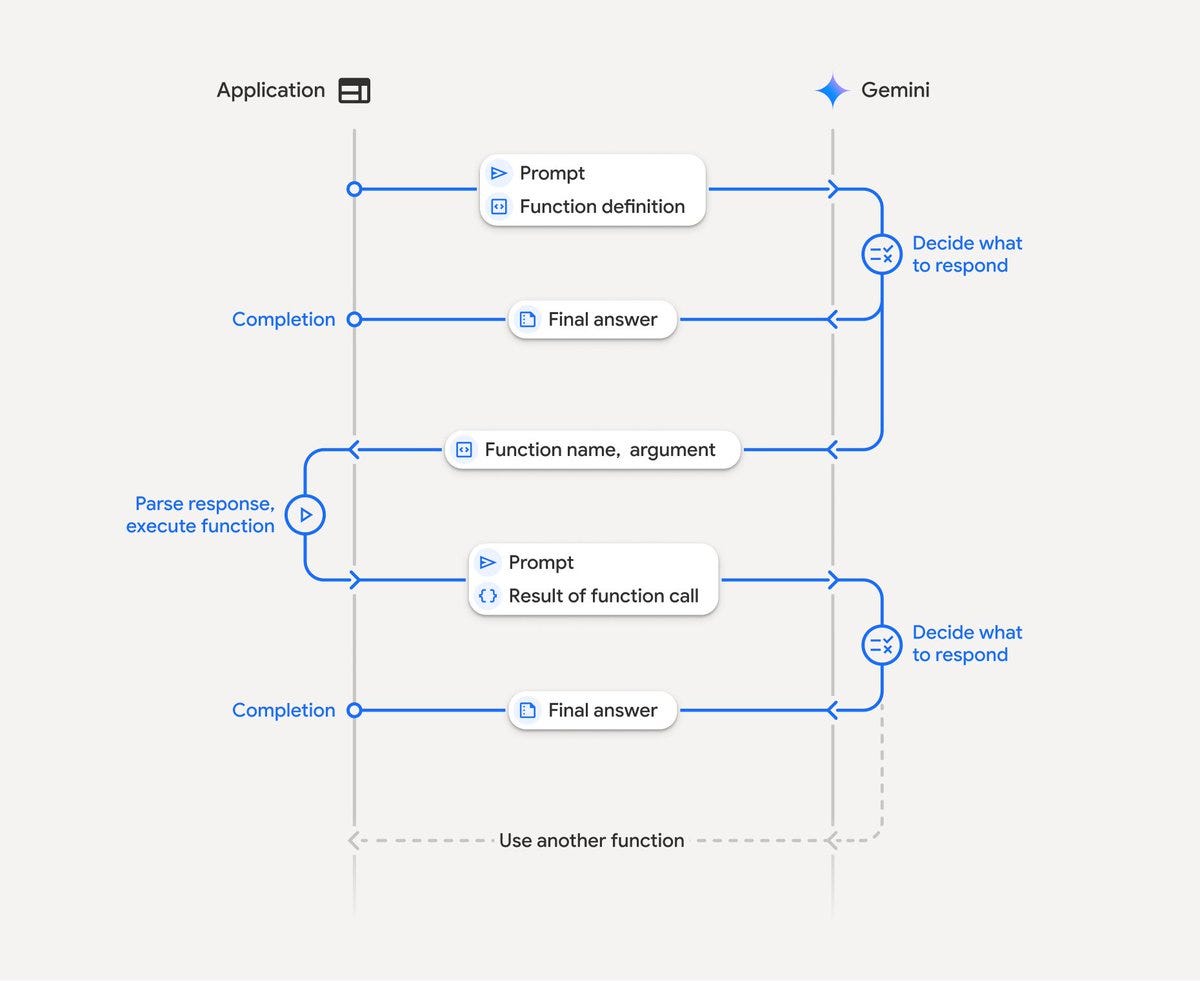
隐式调用:现代化的自动工具执行 最近的LLM都内置了自动工具调用能力。比如Gemini(你可以通过au tomatic_function_calling这个flag来控制这个特性)。由于官方文档和示例都以隐式调用为主,如果你是最近两个月才开始接触MCP开发,你使用的很可能一直都是隐式模式。 在隐式模式下,整个工具调用流程对开发者来说是黑盒的。LLM自动判断是否需要调用工具,自动选择合适的工具和参数,自动执行工具并整合结果。开发者只需要提供工具列表,然后就能直接获得最终的自然语言回答。 隐式是更新的技术,也是未来的趋势,随着大模型能力的进化,这种也应该会成为主流。 聪明的同学应该猜到了,夸完了,转折就来了。没错,隐式有着暂时难以避免的缺点。


隐式的缺点 隐式调用最大的缺陷就是:大模型现在进行结构化输出是依然会出岔子的。 @xicilion为了专门应对大模型输出的json的各种格式错误,甚至专门写过一个工具:
GITHUB:jaison
而且在实际开发中很多场景下,比如将现有API套一层MCP的皮时,由于现有api的返回已经是格式化的输出了,其实我们可能不需要LLM帮我们整理和生成JSON,这部分完全可以用普通的代码(甚至是现存服务里的代码)来进行处理。 但隐式调用时,由于你看不到LLM的调用过程,你也没办法拿到MCP的RAW Data。

显式调用:精确控制的手动解析模式 相对的,显式调用模式需要开发者手动处理工具调用的每个环节。你需要在系统提示中明确告诉LLM如何格式化工具调用请求,然后手动解析LLM回答中的工具调用指令,执行对应的工具,最后将结果整合到最终回答中。 这是古法调用MCP的方法(虽然也就传统了半年而已),隐式只是把这部分也由LLM进行处理。 不过实际上现在实际开发里使用的显式调用,也并不是完全古法的。

半自动回填式显示调用 方法名称是我乱起的。具体做法很简单,你需要在MCP Client中,对于用户的查询,给LLM工具列表后,要求它不是自己调用工具,而是返回需要调用的工具的名称。 接下来,你需要让Client手动调用MCP Server。由于这部分数据很可能就是普通的API返回的格式化好的JSON data,因此你可以把这个和LLM的应答一起封装起来返回。 这个方法适应范围并不那么宽泛,因为这要求多轮LLM对话,比单次对话还是要麻烦不少的。同时你的MCP HOST最好不是什么都管的那种完全通用的chat客户端,这个更适合固定的服务。 但好处就是有了raw data后,你可以完全自由处理数据,数据处理和UI显示等代码直接复用以前服务里的部分即可。而且这种方法兼容并没有自动工具调用的LLM。我们公司由我主导的新服务就是采用的这种方法,反响不错。