
文章介绍了主域名搜集与子域名枚举的方法,包括使用Google语法、Ksubdomain和Subfinder等工具进行资产发现,并通过CDN绕过、端口扫描(如Naabu)、存活检测(如HTTPX)及指纹识别(如EHole_magic)进一步挖掘目标网站的真实IP地址与技术细节。同时强调了自动化脚本的重要性。 2025-7-11 06:39:39 Author: www.freebuf.com(查看原文) 阅读量:19 收藏
主域名搜集
[!NOTE] Title
非常重要,这个决定你后续可以搜索多少资产。
就把它看出一个大房子,后续去搜索出更多的小房子
谷歌语法
国外的网站的关键字信息进行搜索
拿Kelnur进行举例:
| 搜索目的 | Google 语法示例 | 说明 |
|---|---|---|
| 查找相似网站 | related:kelnur.com | 查找与目标网站内容相似的站点 |
| 搜索主域名含关键词 | site:.com "kelnur" -site:*.com | 在 .com 主域名中搜索关键词,排除子域名 |
| 查找反向链接的主域名 | link:kelnur.com -site:*.com | 查找直接链接到目标网站的主域名,排除子域名 |
| 查找新注册的含关键词域名 | "kelnur" daterange:20240101-20241231 -site:*.com | 搜索 2024 年新注册且包含关键词的域名,排除子域名 |
| 直接关键字查询 | “kelnur” | 搜索有关kelnur的站 |
网站图标
去空间测绘拿网站图标进行查询,可能存在别的主域名网站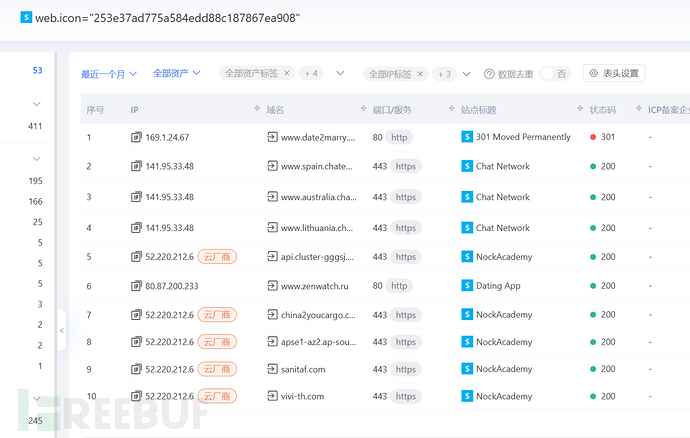
IP查询法
空间测绘根据网站的真实IP地址,查询主域名
IP域名反查
https://viewdns.info/reverseip/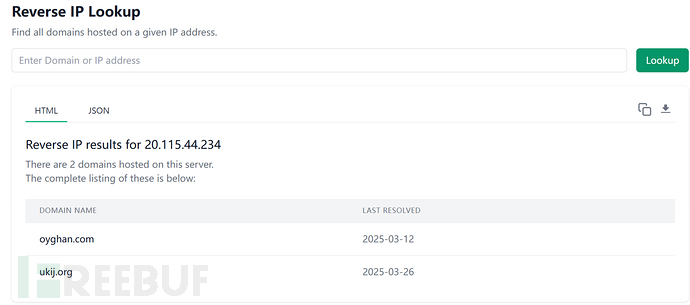
网站关联
根据网站的相关链接进行去寻找主域名
DNS查询
https://dnsdumpster.com/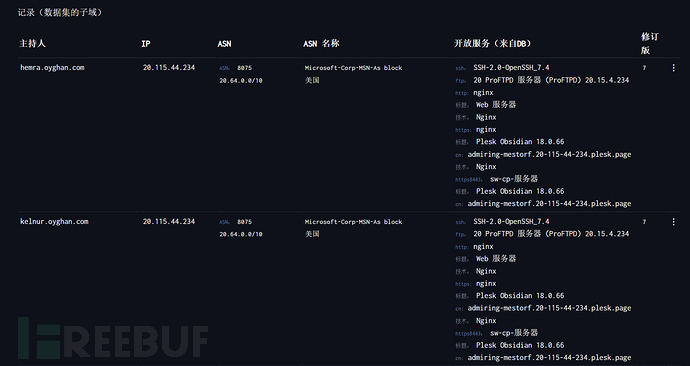
证书查询
https://crt.sh/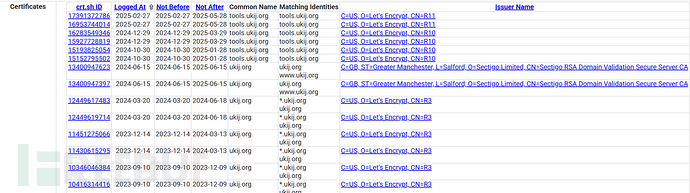
工具篇
Ksubdomain(主动收集)
[!NOTE] Title
子域名枚举工具,异步 dns 数据包,使用 pcap 在 1 秒内扫描 160 万个子域名
网站链接:https://github.com/boy-hack/ksubdomain
常用命令
cat url.txt|./ksubdomain e --stdin -o url2.txt
将收集到的主域名放在一起,进行爆破子域名
e:是ksubdomain的一个子命令,代表 “enumerate”,即进行子域名的主动或被动枚举。--silent:这个选项表示静默模式输出,也就是只输出核心结果,不打印多余的信息,便于后续处理或管道对接。-o url2.txt:将枚举出来的结果(子域名)输出保存到url2.txt文件中。
Subfinder(被动收集)
[!info] Title
快速被动子域枚举工具。
网站链接:https://github.com/projectdiscovery/subfinder
./subfinder -dL url.txt -o url2.txt
-dL url.txt:从文件url.txt中读取多个域名(domain list),每一行一个主域名,进行批量子域名收集。-o url2.txt:将收集到的所有子域名输出保存到url2.txt
去重处理
cat url2.txt >> url3.txt #把url2.txt文件的内容追加到url3.txt文件中
去重脚本
seen = set()
with open('url3.txt', 'r', encoding='utf-8') as infile, open('url4.txt', 'w', encoding='utf-8') as outfile:
for line in infile:
line = line.strip()
if line:
first_part = line.split('=>')[0].strip()
if first_part not in seen:
seen.add(first_part)
outfile.write(first_part + '\n')
子域名解析IP
使用python脚本进行解析IP,并自动进行去重
import dns.resolver
import concurrent.futures
import sys
from tqdm import tqdm
def get_ip_from_local_dns(domain, dns_server="8.8.8.8", dns_port=53):
resolver = dns.resolver.Resolver()
resolver.nameservers = [dns_server]
resolver.port = dns_port
resolver.timeout = 2 # 减少超时时间
resolver.lifetime = 3 # 减少生命周期时间
try:
answers = resolver.resolve(domain, 'A')
ip_list = [rdata.address for rdata in answers]
return domain, ip_list, None
except Exception as e:
return domain, [], str(e)
def read_urls_from_file(file_path):
try:
with open(file_path, 'r') as file:
urls = file.readlines()
return [url.strip() for url in urls if url.strip()]
except FileNotFoundError:
print(f"[-] 文件 {file_path} 未找到")
return []
def write_ips_to_file(results, output_path="ips.txt"):
try:
with open(output_path, 'w') as file:
for ip in results:
file.write(f"{ip}\n")
print(f"[+] 所有 IP 地址已写入 {output_path} 文件")
except Exception as e:
print(f"[-] 写入文件时出错: {e}")
def process_result(result):
domain, ips, error = result
if error:
print(f"[-] {domain} 解析失败: {error}")
else:
print(f"[+] {domain} => {', '.join(ips)}")
return ips
def main():
if len(sys.argv) > 1:
file_path = sys.argv[1]
else:
file_path = input("请输入包含域名的文件路径 (如 url.txt): ")
domains = read_urls_from_file(file_path)
if not domains:
print("[-] 没有找到有效的域名")
return
print(f"[*] 开始处理 {len(domains)} 个域名...")
all_ips = []
# 使用线程池进行并发处理
with concurrent.futures.ThreadPoolExecutor(max_workers=50) as executor:
# 提交所有任务
future_to_domain = {executor.submit(get_ip_from_local_dns, domain): domain for domain in domains}
# 使用tqdm显示进度条
for future in tqdm(concurrent.futures.as_completed(future_to_domain), total=len(domains), desc="解析进度"):
result = future.result()
domain_ips = process_result(result)
all_ips.extend(domain_ips)
# 去重IP地址
unique_ips = list(set(all_ips))
print(f"[+] 共发现 {len(unique_ips)} 个唯一IP地址")
write_ips_to_file(unique_ips)
if __name__ == "__main__":
main()
CDN绕过(拓展)
[!NOTE] 简介
CDN(Content Delivery Network,内容分发网络)是一种分布式服务器系统,通过将网站内容(如静态文件、视频、图片等)缓存到全球多个节点,使用户可以从最近的服务器获取数据,从而提升访问速度、降低延迟,并减轻源站负载。
内部邮箱资源
公司内部的邮件系统通常部署在企业内部,没有经过CDN的解析,通过目标网站用户注册或者RSS订阅功能,查看邮件、寻找邮件头中的邮件服务器域名IP地址,Ping这个邮件服务器的域名,就可以获得目标的真实IP地址(注意,必须是目标自己的邮件服务器,第三方或公共邮件服务器是没有用的)。
扫描网站测试文件
如.phpinfo、.test等,从而找到目标的真实IP地址。
子域名反推法
对未启用CDN的子域名(如mail.example.com)解析获取IP
网络空间引擎搜索
直接语法查询主域名,定位真实IP地址
全球Ping
即可进行判断是否上CDN,还有概率进行绕过
https://tool.chinaz.com//speedworld/kelnur.com
phpinfo.php探针
C段
自行判断,如果你收集的IP是这个样的:
10.1.1.1,10.1.1.2,10.1.1.3,10.1.1.4
不妨去网络空间搜索引擎查询,该IP地址C段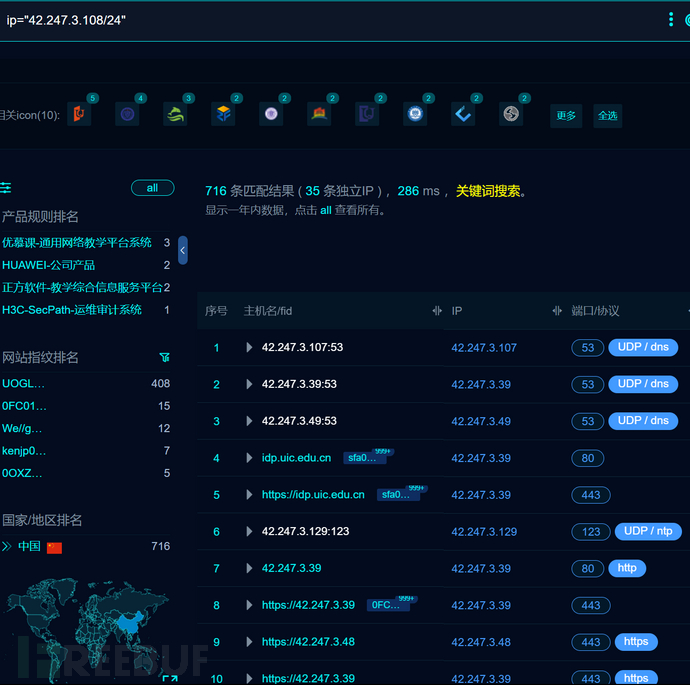
端口收集
Naabu
[!NOTE] Title
用 Go 编写的快速端口扫描程序,注重可靠性和简单性。旨在与其他工具结合使用,用于漏洞赏金和渗透测试中的攻击面发现
网站链接:https://github.com/projectdiscovery/naabu
端口收集非常重要,这能帮我们进一步打开攻击面,发现更多的比较隐蔽的资产。于是我们对前面收集整理到的ip.txt进行全端口扫描!这里就体现了前面为什么要整理好格式了
扫描时间比较长,建议放在国外的VPS上后台或者你自己的VPS运行完成
.\naabu.exe -l ips.txt -silent
可以根据扫描出的端口进行指定的攻击
| 端口 | 服务 | 入侵方式 |
|---|---|---|
| 21 | ftp/tftp/vsftpd文件传输协议 | 爆破/嗅探/溢出/后门 |
| 22 | ssh远程连接 | 爆破/openssh漏洞 |
| 23 | Telnet远程连接 | 爆破/嗅探/弱口令 |
| 25 | SMTP邮件服务 | 邮件伪造 |
| 53 | DNS域名解析系统 | 域传送/劫持/缓存投毒/欺骗 |
| 67/68 | dhcp服务 | 劫持/欺骗 |
| 110 | pop3 | 爆破/嗅探 |
| 139 | Samba服务 | 爆破/未授权访问/远程命令执行 |
| 143 | Imap协议 | 爆破 |
| 161 | SNMP协议 | 爆破/搜集目标内网信息 |
| 389 | Ldap目录访问协议 | 注入/未授权访问/弱口令 |
| 445 | smb | ms17-010/端口溢出 |
| 512/513/514 | Linux Rexec服务 | 爆破/Rlogin登陆 |
| 873 | Rsync服务 | 文件上传/未授权访问 |
| 1080 | socket | 爆破 |
| 1352 | Lotus domino邮件服务 | 爆破/信息泄漏 |
| 1433 | mssql | 爆破/注入/SA弱口令 |
| 1521 | oracle | 爆破/注入/TNS爆破/反弹shell |
| 2049 | Nfs服务 | 配置不当 |
| 2181 | zookeeper服务 | 未授权访问 |
| 2375 | docker remote api | 未授权访问 |
| 3306 | mysql | 爆破/注入 |
| 3389 | Rdp远程桌面链接 | 爆破/shift后门 |
| 4848 | GlassFish控制台 | 爆破/认证绕过 |
| 5000 | sybase/DB2数据库 | 爆破/注入/提权 |
| 5432 | postgresql | 爆破/注入/缓冲区溢出 |
| 5632 | pcanywhere服务 | 抓密码/代码执行 |
| 5900 | vnc | 爆破/认证绕过 |
| 6379 | Redis数据库 | 未授权访问/爆破 |
| 7001/7002 | weblogic | java反序列化/控制台弱口令 |
| 80/443 | http/https | web应用漏洞/心脏滴血 |
| 8069 | zabbix服务 | 远程命令执行/注入 |
| 8161 | activemq | 弱口令/写文件 |
| 8080/8089 | Jboss/Tomcat/Resin | 爆破/PUT文件上传/反序列化 |
| 8083/8086 | influxDB | 未授权访问 |
| 9000 | fastcgi | 远程命令执行 |
| 9090 | Websphere控制台 | 爆破/java反序列化/弱口令 |
| 9200/9300 | elasticsearch | 远程代码执行 |
| 11211 | memcached | 未授权访问 |
| 27017/27018 | mongodb | 未授权访问/爆破 |
探存活
HTTPX
[!NOTE] Title
HTTPX是一种快速且多功能的HTTP工具包,允许使用RetryableHTTP库运行多个探针。
网站链接:https://github.com/projectdiscovery/httpx
把前面的子域名进行探活处理
cat url4.txt | .\httpx.exe -status-code -title -tech-detect -follow-redirects -mc 200,302,403 -proxy http://127.0.0.1:7897 -threads 200 -timeout 10 -o result.json
#根据自己的需求去加参数,导出为json格式方便整理
| 参数 | 含义 |
|---|---|
.\httpx.exe | 调用当前目录下的httpx可执行文件 |
-status-code | 显示响应的 HTTP 状态码(如 200、301 等) |
-title | 抓取网页<title>,用于识别页面内容 |
-tech-detect | 检测目标使用的 Web 技术(如 nginx, PHP, WordPress) |
-follow-redirects | 自动跟随 HTTP 重定向(如 301, 302) |
-fc 404,500,502 | 过滤掉响应状态码为 404、500、502 的结果 |
-proxy http://127.0.0.1:7897 | 通过本地代理(如 Burp、Clash)发送请求,便于抓包或匿名 |
-threads 200 | 启用 200 个并发线程,加快扫描速度 |
-timeout 10 | 请求超时时间设为 10 秒,避免长时间等待 |
指纹收集
EHole_magic
[!NOTE] Title
EHole(棱洞)魔改。可对路径进行指纹识别;支持识别出来的重点资产进行漏洞检测(支持从hunter和fofa中提取资产)支持对ftp服务识别及爆破
https://github.com/lemonlove7/EHole_magic
对存活后的资产进行扫描
.\ehole_windows.exe finger -l .\url.txt --proxy http://127.0.0.1:7897
| 参数 | 含义 |
|---|---|
.\ehole_windows.exe | 调用当前目录下的 ehole Windows 可执行文件 |
finger | 指定模块为“指纹识别”模块 |
-l .\url.txt | 指定目标列表文件,格式通常是一行一个 URL |
--proxy http://127.0.0.1:7897 | 所有 HTTP 请求走本地代理(支持抓包、走代理链等) |

网站基本信息
语言
可以使用 Wappalyzer工具分析网站所使用的编程语言。
数据库
使用 Wappalyzer或 fofa进行数据库类型的识别。
web容器
同样,Wappalyzer和 fofa可以帮助识别网站使用的Web容器(如Apache、Nginx等)。
操作系统
可以通过对目标服务器进行大小写测试和Ping TTL值分析,间接推测目标服务器使用的操作系统。
目录扫描
FFUF
[!NOTE] Title
用 Go 编写的快速网络模糊器
网站链接:https://github.com/ffuf/ffuf
目录扫描不建议多网站进行扫描,当然如何你工作量比较大可以写一个遍历脚本。
目录扫描可不可以扫描到,就比较看你自己准备的字典了
常用命令
.\ffuf.exe -u https://www.eee.com/FUZZ -w ./common.txt -x http://127.0.0.1:7897 -mc 200 -recursion -recursion-depth 2 -c
| 参数 | 含义 |
|---|---|
-u https://www.mac.gov.tw/FUZZ | 目标 URL,FUZZ是 fuzz 的占位符 |
-w ./common.txt | 字典文件路径,一行一个爆破路径 |
-x http://127.0.0.1:7897 | 请求通过本地代理发送,可用于抓包或绕过 |
-mc 200,403 | 只显示返回状态码为 200 或 403 的结果(200 为存在,403 也可能是隐藏资源) |
-recursion | 对发现的目录自动递归爆破 |
-recursion-depth 2 | 限制递归深度为 2 层 |
-c | 使用颜色高亮输出 |
-v | 显示详细请求信息(Verbose 模式) |
字典
SecLists(Starred 62.3k)
https://github.com/danielmiessler/SecLists
[!info] Title
SecLists 是安全测试人员的得力助手。它汇集了安全评估过程中使用的多种类型的列表,并将它们集中到一处。列表类型包括用户名、密码、URL、敏感数据模式、模糊测试载荷、Web Shell 等等。
这个字典非常的全面
JS爬取
JSFinder
JSFinder是一个用于在目标网页中自动提取 JavaScript 文件并从中提取潜在敏感信息(如 API 路径、域名、密钥等)的信息收集工具
网站链接:https://github.com/Threezh1/JSFinder
常用命令
单个目标:
python .\JSFinder.py -u https://zhjs.wwww.edu.cn/ -c "_gscu_1123603759:434164374obd12" -d
# 加上cookie一般可以扫出更多有用的接口信息
| 参数 | 含义 |
|---|---|
-u https://zhjs.www.edu.cn/ | 指定目标网址 |
-c "cookie:434164374obizd2" | 指定Cookie |
-d | 深度扫描 |
小结
本篇文章讲述信息收集的顺序,当然信息搜集的艺术远不止此,你要根据自己的思维去不断的进行拓展
上述讲述的方法,偏向于国外网站的信息收集,你要基于自己的方式进行整理,也可以写一个自动化的脚本节省大量工作时间。
如有侵权请联系:admin#unsafe.sh