文章探讨了预训练数据中概念频率与零样本性能之间的关系,通过实验发现概念频率与零样本任务表现呈现强对数线性关系,并验证了这一趋势在不同提示策略、检索指标及图像到文本模型中的普适性。 2025-7-9 10:0:3 Author: hackernoon.com(查看原文) 阅读量:18 收藏
Table of Links
2 Concepts in Pretraining Data and Quantifying Frequency
3 Comparing Pretraining Frequency & “Zero-Shot” Performance and 3.1 Experimental Setup
3.2 Result: Pretraining Frequency is Predictive of “Zero-Shot” Performance
4.2 Testing Generalization to Purely Synthetic Concept and Data Distributions
5 Additional Insights from Pretraining Concept Frequencies
6 Testing the Tail: Let It Wag!
8 Conclusions and Open Problems, Acknowledgements, and References
Part I
Appendix
A. Concept Frequency is Predictive of Performance Across Prompting Strategies
B. Concept Frequency is Predictive of Performance Across Retrieval Metrics
C. Concept Frequency is Predictive of Performance for T2I Models
D. Concept Frequency is Predictive of Performance across Concepts only from Image and Text Domains
F. Why and How Do We Use RAM++?
G. Details about Misalignment Degree Results
I. Classification Results: Let It Wag!
A Concept Frequency is Predictive of Performance Across Prompting Strategies
We extend the zero-shot classification results from Fig. 2 in Fig. 8 with two different prompting strategies: the results in the main paper used the {classname} only as the prompts, here we showcase both (1) “A photo of a {classname}” prompting and (2) 80 prompt ensembles as used by Radford et al [91]. We observe that the strong log-linear trend between concept frequency and zero-shot performance consistently holds across different prompting strategies.
![Figure 8: Log-linear relationships between concept frequency and CLIP zero-shot performance. Across all tested architectures (RN50, RN101, ViT-B-32, ViT-B-16, ViT-L-14) and pretraining datasets (CC-3M, CC-12M, YFCC-15M, LAION-400M), we observe a consistent linear relationship between CLIP’s zero-shot classification accuracy on a concept and the log-scaled concept pretraining frequency. This trend holds for both “A photo of a {classname}” prompting style and 80 prompt ensembles [91]. ** indicates that the result is significant (p < 0.05 with a two-tailed t-test.), and thus we show pearson correlation (ρ) as well.](https://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-ie833e1.png?auto=format&fit=max&w=3840)
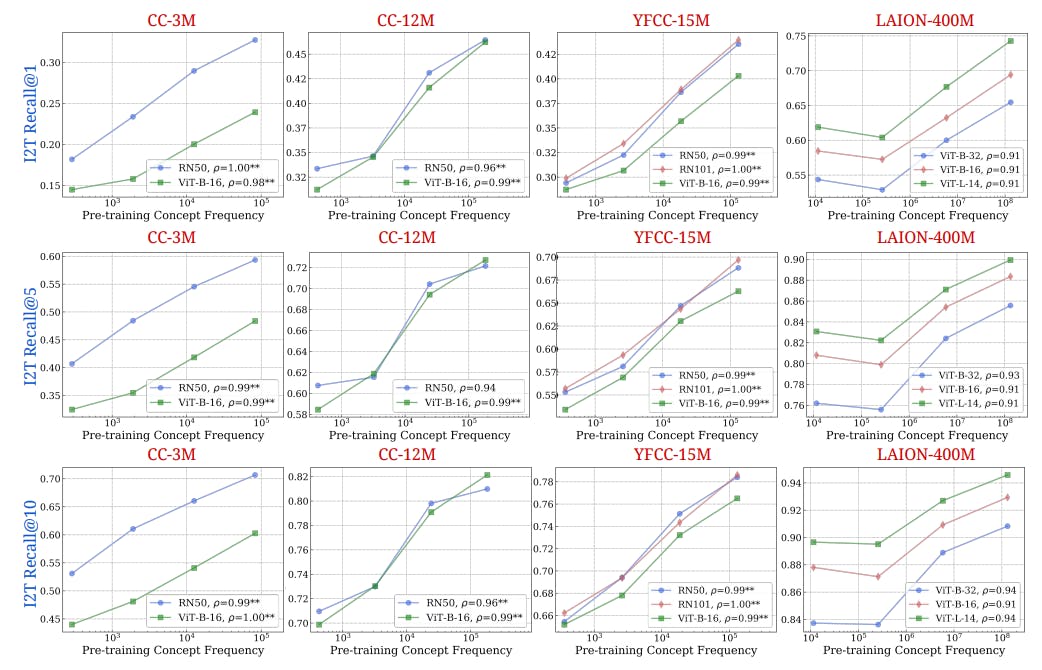
B Concept Frequency is Predictive of Performance Across Retrieval Metrics
We supplement Fig. 2 in the main paper, where we showed results with the text-to-image (I2T) recall@10 metric. In Figs. 9 and 10, we present results for the retrieval experiments across all six metrics: I2T-Recall@1, I2T-Recall@5, I2T-Recall@10, T2I-Recall@1, T2I-Recall@5, T2I-Recall@10. We observe that the strong log-linear trend between concept frequency and zero-shot performance robustly holds across different retrieval metrics.


Authors:
(1) Vishaal Udandarao, Tubingen AI Center, University of Tubingen, University of Cambridge, and equal contribution;
(2) Ameya Prabhu, Tubingen AI Center, University of Tubingen, University of Oxford, and equal contribution;
(3) Adhiraj Ghosh, Tubingen AI Center, University of Tubingen;
(4) Yash Sharma, Tubingen AI Center, University of Tubingen;
(5) Philip H.S. Torr, University of Oxford;
(6) Adel Bibi, University of Oxford;
(7) Samuel Albanie, University of Cambridge and equal advising, order decided by a coin flip;
(8) Matthias Bethge, Tubingen AI Center, University of Tubingen and equal advising, order decided by a coin flip.
如有侵权请联系:admin#unsafe.sh