


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

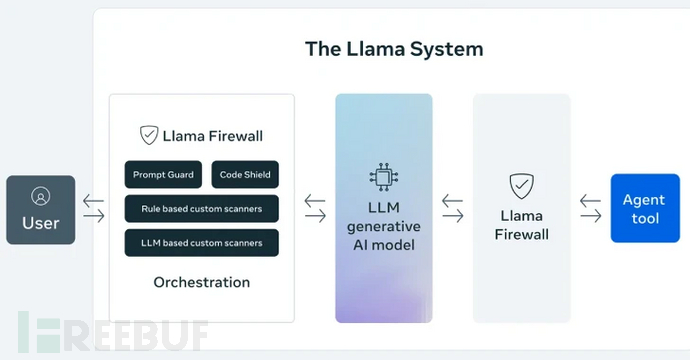
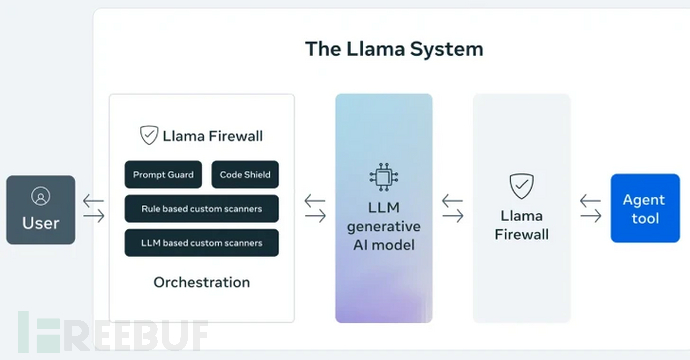
Meta公司周二正式发布开源框架LlamaFirewall,该框架旨在保护人工智能(AI)系统免受即时注入(prompt injection)、越狱攻击(jailbreak)及不安全代码等新兴网络安全威胁。
三重防护机制
据该公司介绍,该框架包含三大防护组件:PromptGuard 2、Agent Alignment Checks和CodeShield。其中PromptGuard 2可实时检测直接的越狱攻击和即时注入尝试;Agent Alignment Checks则能监测AI代理的推理过程,识别潜在的目标劫持和间接即时注入攻击场景。
CodeShield是一个在线静态分析引擎,专门用于阻止AI代理生成不安全或危险的代码。Meta在GitHub项目描述中表示:"LlamaFirewall设计为一个灵活的实时防护框架,用于保护基于大语言模型(LLM)的应用程序。其模块化架构使安全团队和开发者能够构建分层防御体系,覆盖从原始输入到最终输出的全流程——无论是简单聊天模型还是复杂自主代理。"

配套安全工具升级
与LlamaFirewall同步推出的还有LlamaGuard和CyberSecEval的升级版本。前者用于更精准检测各类违规内容,后者则用于评估AI系统的网络安全防御能力。CyberSecEval 4新增了名为AutoPatchBench的基准测试,专门评估大语言模型代理自动修复通过模糊测试(fuzzing)发现的C/C++漏洞的能力,这种技术被称为AI驱动的补丁修复。
Meta表示:"AutoPatchBench为评估AI辅助漏洞修复工具的有效性提供了标准化框架。该基准测试旨在全面了解各类AI驱动方法在修复模糊测试发现漏洞方面的能力与局限。"
安全开发者计划
此外,Meta还启动了名为"Llama for Defenders"的新计划,通过向合作组织和AI开发者提供开放、早期测试及封闭式AI解决方案,帮助应对特定安全挑战,例如检测用于诈骗和钓鱼攻击的AI生成内容。
这些技术发布恰逢WhatsApp预览名为"Private Processing"的新技术。该技术通过将用户请求卸载到安全保密环境中处理,使得用户在使用AI功能时无需担心隐私泄露。Meta表示:"我们正与安全社区合作审核改进架构,在正式产品化前将继续与研究人员协作,以开放方式持续完善Private Processing技术。"
参考来源:
Meta Launches LlamaFirewall Framework to Stop AI Jailbreaks, Injections, and Insecure Code
本文为 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf
客服小蜜蜂(微信:freebee1024)