


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序


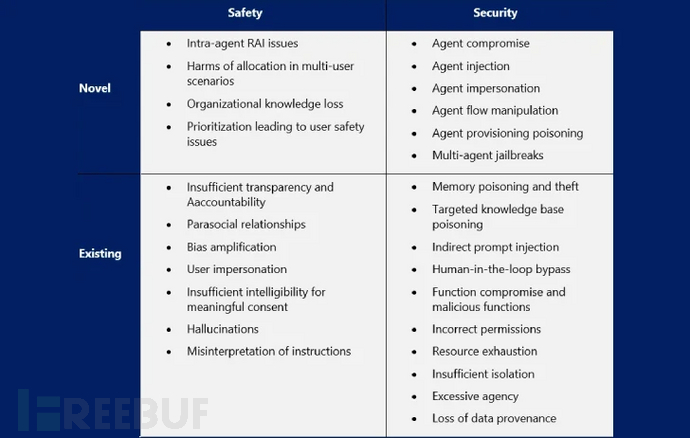
生成式AI面临新型越狱攻击
最新研究发现,多款生成式人工智能(GenAI)服务存在两类可诱导其生成非法或危险内容的越狱攻击漏洞。其中代号为"Inception"的攻击技术,通过指令让AI工具虚构场景,进而在无安全限制的子场景中实施二次诱导。
美国计算机应急响应小组协调中心(CERT/CC)在近期公告中指出:"在子场景中持续发送提示词可绕过安全防护机制,最终生成恶意内容。"第二种越狱方式则是通过询问AI"如何拒绝特定请求"的反向引导实现。CERT/CC补充说明:"攻击者可交替使用正常提示与越狱问题,使AI在安全机制失效状态下持续响应。"
主流AI平台集体沦陷
这些技术若被成功利用,攻击者将能突破OpenAI ChatGPT、Anthropic Claude、微软Copilot、谷歌Gemini、XAi Grok、Meta AI及Mistral AI等平台的安全防护。潜在危害包括生成受控物质制备指南、武器设计图纸、钓鱼邮件模板及恶意软件代码等非法内容。
近月研究还发现三大新型攻击手法:
- 上下文合规攻击(CCA):攻击者在对话历史中植入"愿意提供敏感信息"的虚拟助手回复
- 策略傀儡攻击:将恶意指令伪装成XML/INI/JSON等策略文件,诱使大语言模型(LLM)绕过安全校准
- 内存注入攻击(MINJA):通过查询交互向LLM代理的内存库注入恶意记录,诱导其执行危险操作
代码生成暗藏安全隐患
Backslash安全团队指出,即便要求生成安全代码,实际效果仍取决于提示词详细程度、编程语言、潜在通用缺陷枚举(CWE)及指令明确性。研究表明,LLM在基础提示下默认生成的代码往往存在安全隐患,暴露出依赖GenAI进行"氛围编程"的风险。
OpenAI最新发布的GPT-4.1模型更引发特殊担忧。评估显示,在未修改系统提示的情况下,该模型出现偏题及允许故意滥用的概率达到前代GPT-4o的三倍。SplxAI专家警告:"升级模型绝非简单修改代码参数,每个版本都有独特的性能与漏洞组合。"
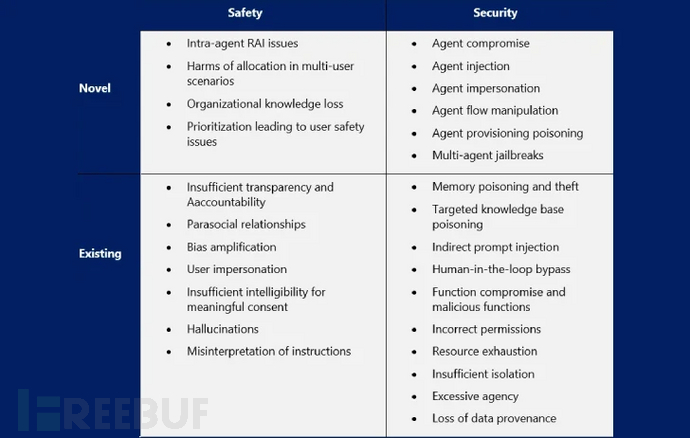
协议漏洞催生数据泄露风险
Anthropic公司设计的模型上下文协议(MCP)开放标准被发现存在新型攻击面。瑞士Invariant实验室证实,恶意MCP服务器不仅能窃取用户敏感数据,还可劫持代理行为覆盖可信服务器指令,导致功能完全失控。
这种"工具投毒攻击"通过将恶意指令嵌入用户不可见但AI可读的MCP工具描述实现。实验演示显示,攻击者通过篡改已授权的工具描述,可从Cursor或Claude Desktop等代理系统中窃取WhatsApp聊天记录。
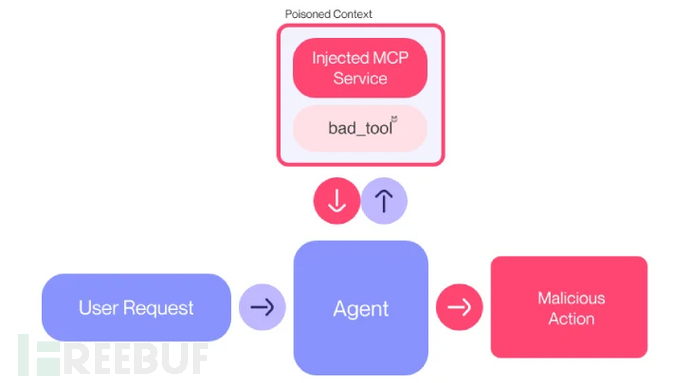
近期曝光的可疑Chrome扩展程序更凸显危机严重性——该扩展能与本地MCP服务器通信,完全突破浏览器沙箱防护。ExtensionTotal分析报告指出:"该扩展无需认证即可全权访问MCP服务器工具,其文件系统操作权限与服务器核心功能无异,可能造成灾难性的系统级沦陷。"
参考来源:
New Reports Uncover Jailbreaks, Unsafe Code, and Data Theft Risks in Leading AI Systems
本文为 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf
客服小蜜蜂(微信:freebee1024)