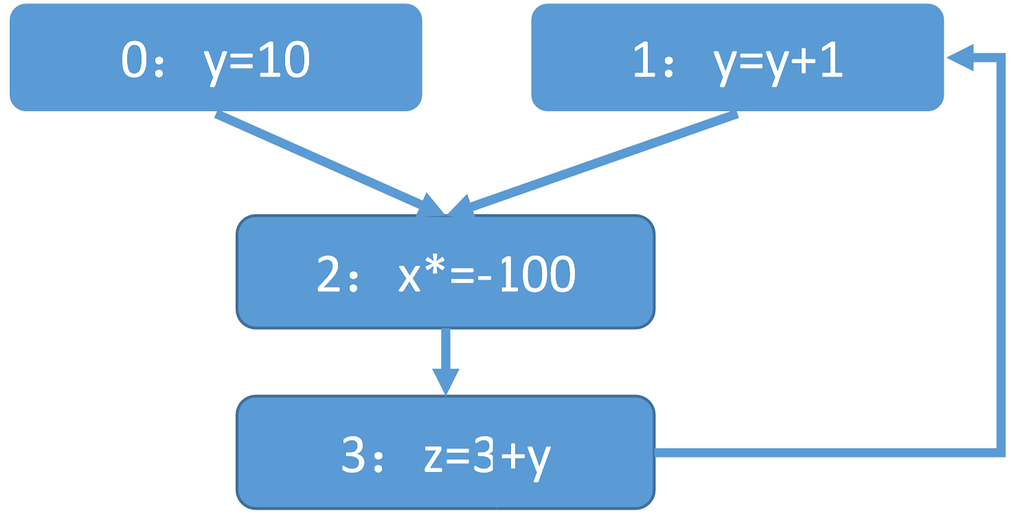
先前有很多数据流分析问题都是关于变量中的值分析,例如:符号分析、常量传播、污点分析等。考虑对以下CFG做数值分析:
- 在空间复杂度方面,对每个节点都需要保存一份关于x, y, z的值,而一个节点通常只影响了少数变量(如节点2与y,z 无关)
- 在时间复杂度方面,对当节点一更新y时,更新至于节点3有关,但是数据流必须通过2才能传到3
Def-Use关系
给定变量x,如果结点A可能改变x的值,结点B可能使用结点A改变后的x的值,则结点A和结点B存在Def-Use关系
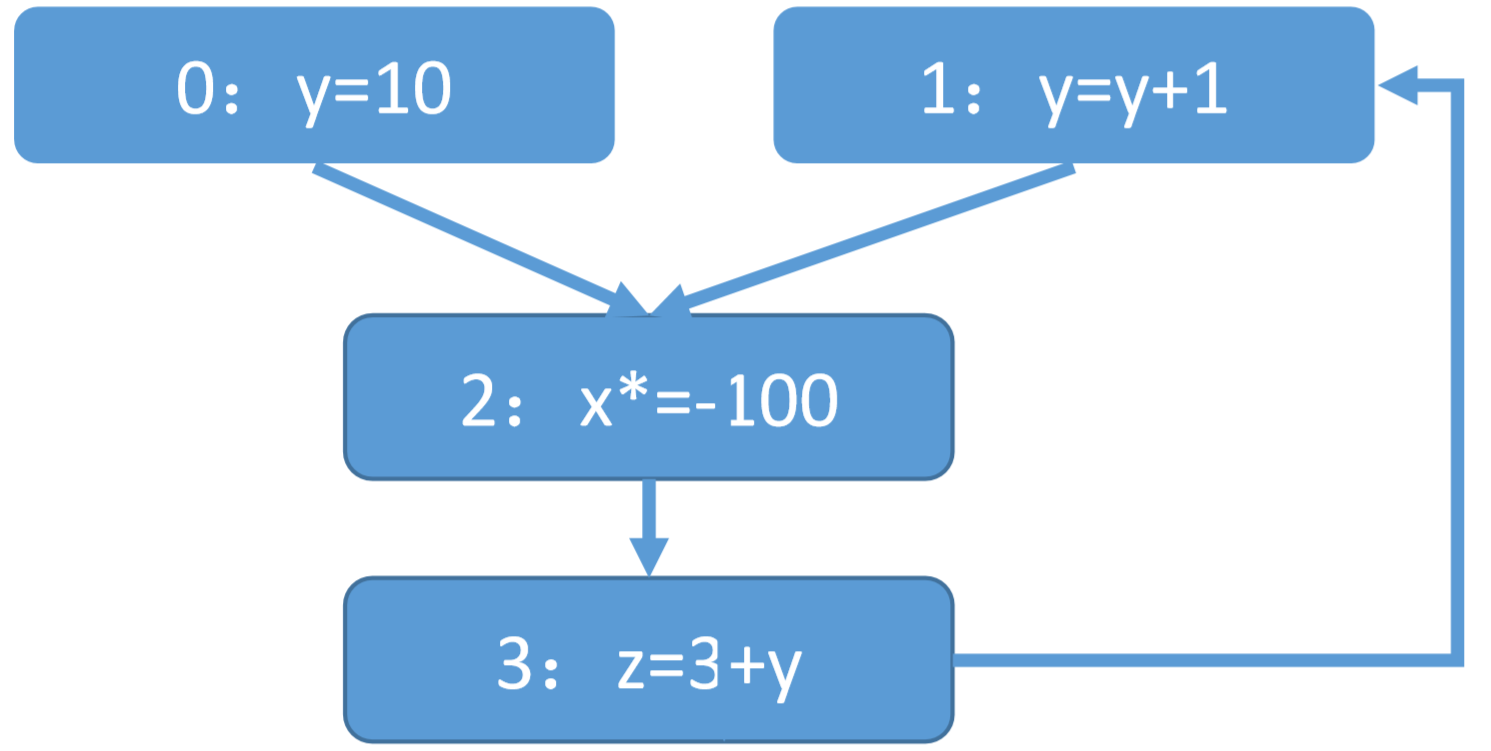
以上面的CFG来说,节点0和节点1,节点1和节点3就存在Def-Use关系。
基于Def-Use的数据流分析首先将其转换为Def-Use边的图,再根据DefUse边做数据流分析:

例如上图,有以下转换函数:
- y_0=f_0()
- y_1=f_1(y_0\sqcap y_1)
- x_2=f_2(x_2\sqcap x_0)
- z_3=f_3(y_0\sqcap y_1)
对Def-Use的数据流分析有以下好处:
- 节点只需保存与自己相关的抽象值
- 图上的边大大减少,即图变为稀疏图
- 分析效率提高
相关性质
- may分析,返回结果是真实结果的超集;
- soundness和precision,等效于原数据流分析效果。
需要解决的问题
问题1:如何构造Def-Use?
可以用Reaching Definition分析得到,那么分析复杂度为 $O(nm^2)$,n为控制流图节点,m为赋值语句个数,速度不够快。
问题2:如果分支语句过多,Def-Use的边反而会增加:
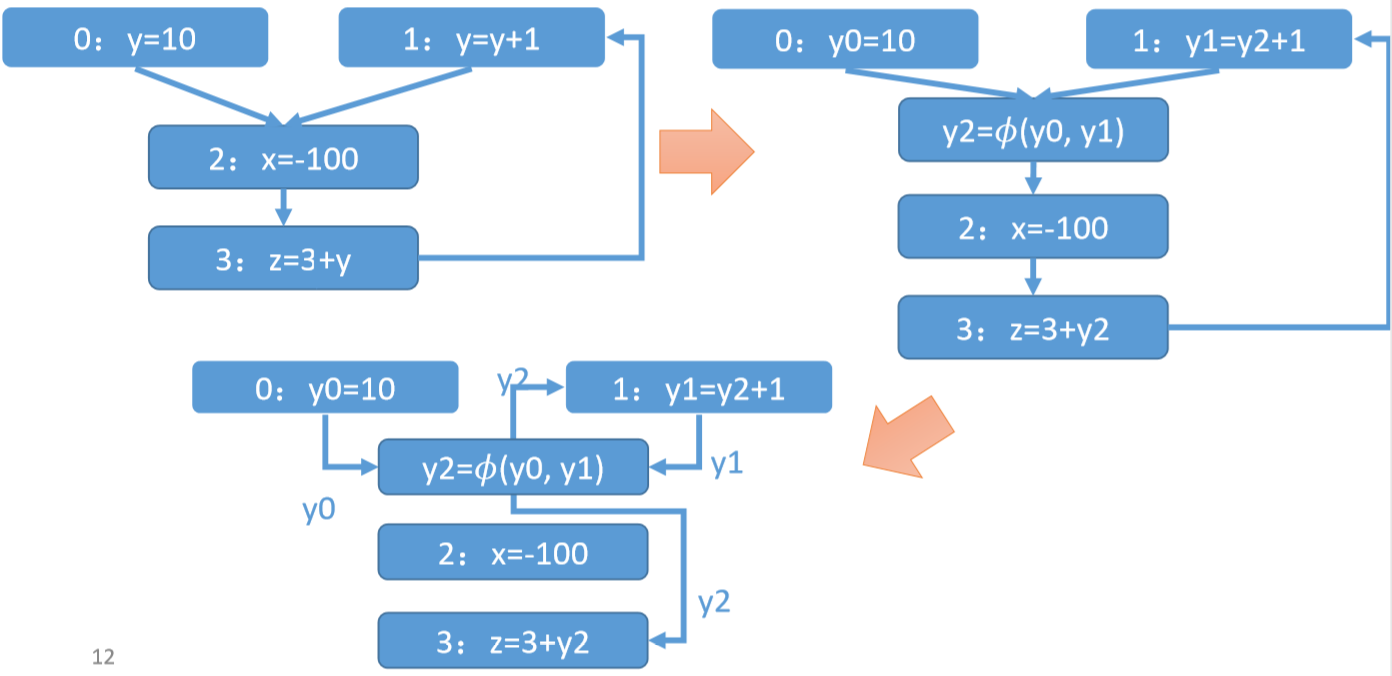
静态单赋值
为解决上述问题,引入静态单赋值(SSA),在SSA中,每个变量只被赋值一次,并且引入$\phi()$函数表示控制流汇聚的情况,例如如下代码(左侧)表示为静态单赋值形式(右侧):

SSA有如下几个好处:
- SSA直接提供了def-use链,如下所示,等号左边变量为入度,等号右边变量为出度:
-
SSA的边不会平方增长(因为有$\phi()$):

-
SSA上的流非敏感分析和流敏感分析等价(变量间赋值关系反映了数据流向)

稀疏分析
基于SSA的分析被称为稀疏分析(sparse program analysis)
首先讨论 \phi 的加入条件,对于一个代码块B,若满足一下条件,需要在B前加$\phi$:
-
到达B的路径≥2;
-
其中有一条路径经过了某变量i的赋值语句s;
-
有一条路径没有经过s;
-
s和B之间没有别的代码块满足条件。
支配关系
节点A支配(dominate)节点B,指所有从Entry到B的路径都要经过A,如下两种情况,A都支配B:

结点A严格支配(Strictly dominate)结点B,A支配B并且A和B不是一个结点(如上图中,只有左图A严格支配B)。
结点A的支配边界(Dominance Frontier)中包括B,当且仅当:
- A支配B的某一个前驱结点,即A在B的某条路径上:
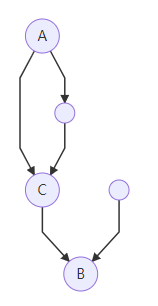
- 或者,A不严格支配B,即A==B:
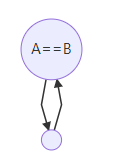
对于任意赋值语句`x=...`所在的节点A,在A的所有支配边界插入$\phi$。
对任意变量i,令 A 为所有对 i 赋值的节点,节点 $a \in A$,$DF(a)$为 a 的支配边界集合,$DF^+(A) 为所有需要插入 \phi(i)$ 的节点:
- \mathrm{DF}(\mathrm{A})=\mathrm{U}_{\{\mathrm{a} \in \mathrm{A}\}} \mathrm{DF}(\mathrm{a})
-
\mathrm{DF}^{+}(\mathrm{A})=\lim _{i \rightarrow \infty} D F^{i}(A)
- DF^{1}(A)=DF(A)
- DF^{i+1}(A)=D F\left(\cup_{j \leq i} DF^{j}(A)\right)
计算支配边界
计算直接支配者(immediate dominator):a严格支配b,并且不存在c,a严格支配c且c严格支配b, 则a是b的直接支配者,记为idom(b)
直接支配关系实际上是一个树,即支配树,支配树可以反映支配边界:

计算支配树的算法有两种:
- Lengauer and Tarjan算法
- 复杂度为$O(E\alpha(E,N))$
- E为边数,N为结点数,𝛼为Ackerman函数的逆(Ackerman函数基本可以认为是常数)
- Cooper, Harvey, Kennedy算法
- 复杂度为 $O(N^2)$,实际比 Lengauer and Tarjan 快
SSA需要每个内存位置一旦赋值,其值都不会发生改变,但是在指针操作时并不满足,例如下面C代码的指针操作:
a=10;
i=&a;
*i=20;
b=a; // b=?
/* to SSA */
a=10;
i=&a;
*i=20;
b=a; // b=10
将其翻译成SSA之后,可以看到b值实际上被变量 i 影响,但是SSA没法反应这个信息,因此分析下来 b=10 ,这种情况在java也存在:
a.f=10;
y=a;
y.f=20;
b=a.f; // b=?
/* to SSA */
a.f=10;
y=a;
y.f=20;
b=a.f; // b=10
因此在实际使用时,会做部分SSA,只对能转换的组做优化。
对于Java来说,栈上的变量为优化组,堆上的变量为不优化组;
对于C的情况:和top-level(从没被&取过地址的变量)为优化组,address-taken(曾经被&取过地址的变量 )为不优化组。