2020-09-23 20:26:00 Author: paper.seebug.org(查看原文) 阅读量:455 收藏
Author:LoRexxar'@Knownsec 404 Team
Date: September 23, 2020
Chinese Version: https://paper.seebug.org/1339/
Since mankind invented tools, mankind has been exploring how to do anything more conveniently and quickly. In the process of scientific and technological development, mankind keeps on trial,error, and thinking. So there is a great modern technological era. In the security field, every security researcher is constantly exploring how to automatically solve security problems in various fields in the process of research. Among them, automated code auditing is the most important part of security automation.
This time we will talk about the development history of automated code audit. And by the way, we will talk about the key to an automated static code audit.
Before talking about automated code audit tools, we must first understand two concepts, missing alarm rate and false alarm rate. -missing alarm rate refers to vulnerabilities/Bugs not found. -False alarm rate refers to the wrong vulnerabilities/Bugs found.
When evaluating all the following automated code audit tools/ideas/concepts, all evaluation criteria are inseparable from these two points. How to eliminate the two points or one of them is also the key point in the development of automated code auditing.
We can simply divide automated code audits (here we are discussing white boxes) into two categories. One is dynamic code audit tools, and the other is static code audit tools.
The principle of the dynamic code audit tool is mainly based on the code running process. We generally call it IAST (Interactive Application Security Testing).
One of the most common ways is to hook malicious functions or underlying APIs in some way, and use front-end crawlers to determine whether the malicious functions are triggered to confirm the vulnerability.
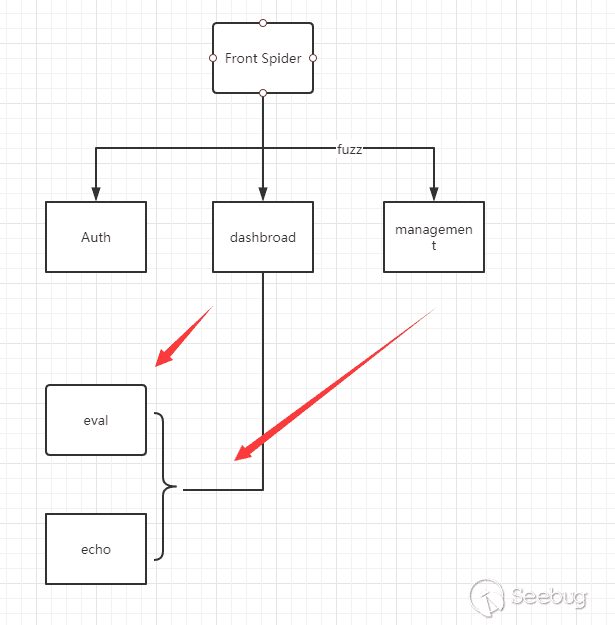
We can understand this process through a simple flowchart.
In the process of front-end Fuzz, if the Hook function is triggered and meets a certain condition,we will think the vulnerability exists.
The advantage of this type of scanning tool is that the vulnerabilities discovered have a low rate of false positives, and do not rely on code. Generally speaking, triggering a rule means that we can perform malicious actions. And being able to track dynamic calls is also one of the main advantages of this method.
But there are many disadvantages (1) The front-end Fuzz crawler can guarantee the coverage of normal functions, but it is difficult to guarantee the coverage of code functions.
If you have used dynamic code audit tools to scan a large number of codes, it is not difficult to find that the scan results of such tools for vulnerabilities will not have any advantages over pure black box vulnerability scanning tools. The biggest problem is mainly the coverage of code functions.
Generally speaking, it is difficult for you to guarantee that all the developed codes serve the features of the website. Perhaps the redundant code is left behind during the old version, or the developers did not realize that they wrote the code below will not just execute as expected. There are too many vulnerabilities that cannot be discovered directly from the front-end features. And some functions may need to be triggered by specific environments and specific requests. In this way, code coverage cannot be guaranteed. So how can it be guaranteed that vulnerabilities can be found?
(2) Dynamic code auditing depends on the underlying environment and check strategies
Since the vulnerability identification of dynamic code audit mainly relies on Hook malicious functions, for different languages and different platforms, dynamic code audit often needs to design different hook schemes. If the depth of the hook is not enough, a depth frame may not be able to scan.
Take PHP as an example. The more mature Hook solution is implemented through a PHP plug-in. Such like:
Due to this reason, general dynamic code audits rarely scan multiple languages at the same time, and generally target a certain language.
Second, Hook's strategy also requires many different restrictions. Take PHP's XSS as an example. It does not mean that a request that triggers the echo function should be identified as XSS. Similarly, in order not to affect the normal function, it is not that the echo function parameter contains <script> to be considered an XSS vulnerability. In the dynamic code audit strategy, a more reasonable front-end -> Hook strategy discrimination scheme is required, otherwise a large number of false positives will occur.
In addition to the previous problems, the strong dependence on the environment, the demand for execution efficiency, and the difficulty of integrating with business code also exist. When the shortcomings of dynamic code auditing are constantly exposed, from the author's point of view, dynamic code auditing has conflicts between the principle itself and the problem, so in the development process of automation tools, more and more eyes are put back to the Static code audit (SAST).
The static code audit mainly analyzes the target code, analyzes and processes through pure static means, and explores the corresponding vulnerabilities/Bugs.
Different from dynamic, static code audit tools have undergone a long-term development and evolution process. Let's review them together (the relative development period mainly represented by each period below is not relatively absolute before and after birth):
Keyword Match
If I ask you "If you were asked to design an automated code audit tool, how would you design it?", I believe you will answer me that you can try to match keywords. Then you will quickly realize the problem of keyword matching.
Here we take PHP as a simple example.

Although we matched this simple vulnerability, we quickly discovered that things were not that simple.

Maybe you said that you can re-match this problem with simple keywords.
Unfortunately, as a security researcher, you will never know how developers write code. So if you choose to use keyword matching, you will face two choices:
- High coverage
The most classic of this type of tool is Seay, which uses simple keywords to match more likely targets. And then users can further confirm through manual audits.
-High availability
The most classic of these tools is the free version of Rips.
Use more regulars to constrain and use more rules to cover multiple situations. This is also the common implementation method of early static automated code audit tools.
But the problem is obvious. High coverage and high availability are flaws that this implementation method can never solve. Not only is the maintenance cost huge, but the false alarm rate and the missing alarm rate are also high. Therefore, being eliminated by the times is also a historical necessity.
the AST-based code audit
Some people ignore the problem, while others solve it. The biggest problem with keyword matching is that you will never be able to guarantee the habits of developers, and you will not be able to confirm vulnerabilities through any standard matching. Then the AST-based code audit method was born. Developers are different, but the compiler is the same.
Before sharing this principle, we can first reproduce the compilation principle. Take the PHP code example:
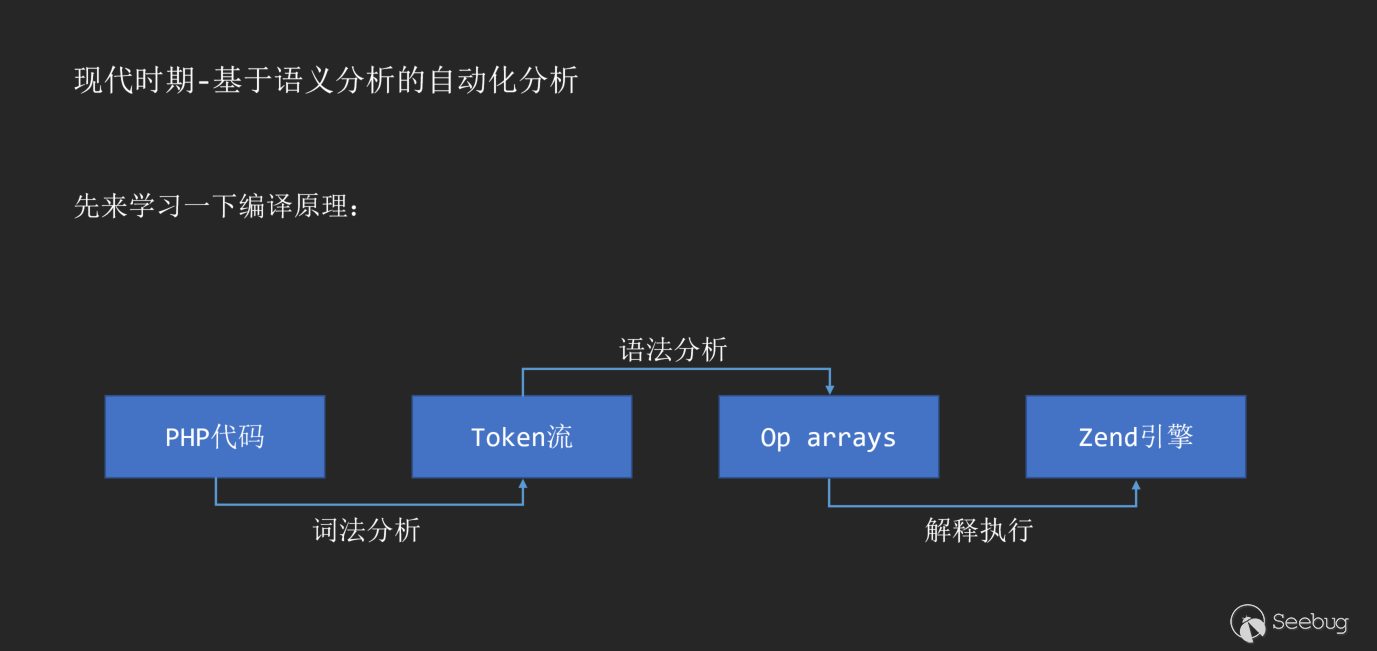
With the birth of PHP7, AST also appeared in the compilation process as an intermediate layer of PHP interpretation and execution.
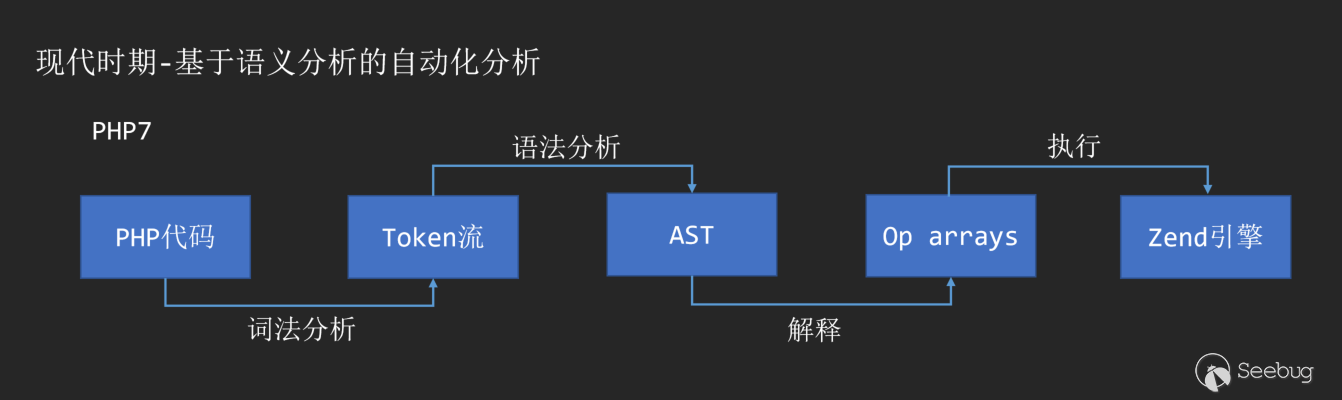
Through lexical analysis and syntax analysis, we can convert any piece of code into an AST syntax tree. Common semantic analysis libraries can refer to:
When we got an AST syntax tree, we solved the biggest problem of keyword matching mentioned earlier. At least we now have a unified AST syntax tree for different codes. How to analyze the AST syntax tree has become the biggest problem of such tools.
Before understanding how to analyze the AST syntax tree, we must first understand the three concepts of information flow, source, and sink.
- source: We can simply call it the input, which is the starting point of the information flow.
- sink: We can call it the output, which is the end of the information flow.
The information flow refers to the process of data flowing from source to sink.
Put this concept in the PHP code audit process, Source refers to user-controllable input, such as $_GET, $_POST, etc. While Sink refers to the sensitive function we want to find, such as echo, eval. If there is a complete flow from a Source to Sink, then we can think that there is a controllable vulnerability, which is based on the principle of code auditing of information flow.
After understanding the basic principles, I will give a few simple examples:

In the above analysis process, Sink is the eval function, and the source is $_GET. Through reverse analysis of the source of Sink, we successfully found an information flow that flows to Sink, and successfully discovered this vulnerability.
ps: Of course, some people may be curious about why you choose reverse analysis flow instead of forward analysis flow. This problem will continue to penetrate in the subsequent analysis process, and you will gradually understand its key points.
In the process of analyzing information flow, clear scope is the base of analyze. This is also the key to analyzing information flow, we can take a look at a simple code.
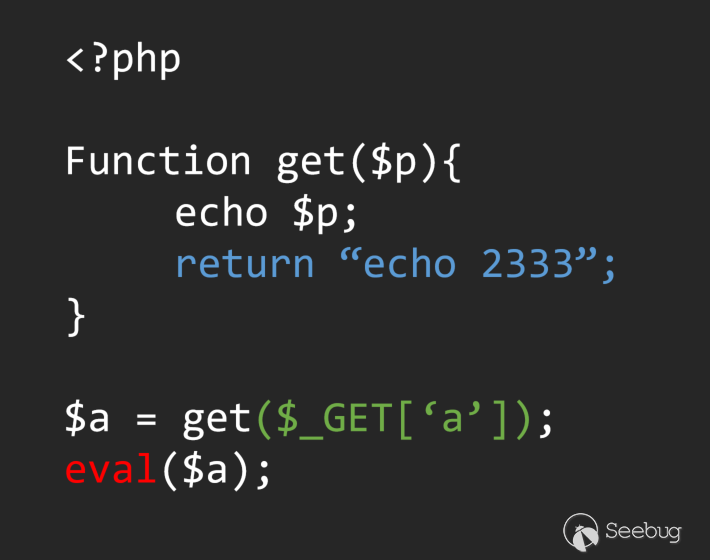
If we simply go back through the left and right values without considering the function definition, we can easily define the flow as:
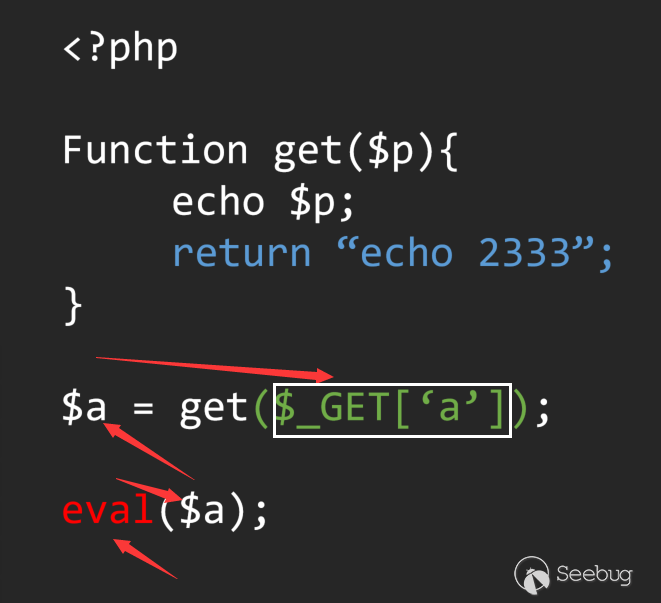
In this way, we mistakenly defined this code as a vul, but obviously not, and the correct analysis process should be like this:
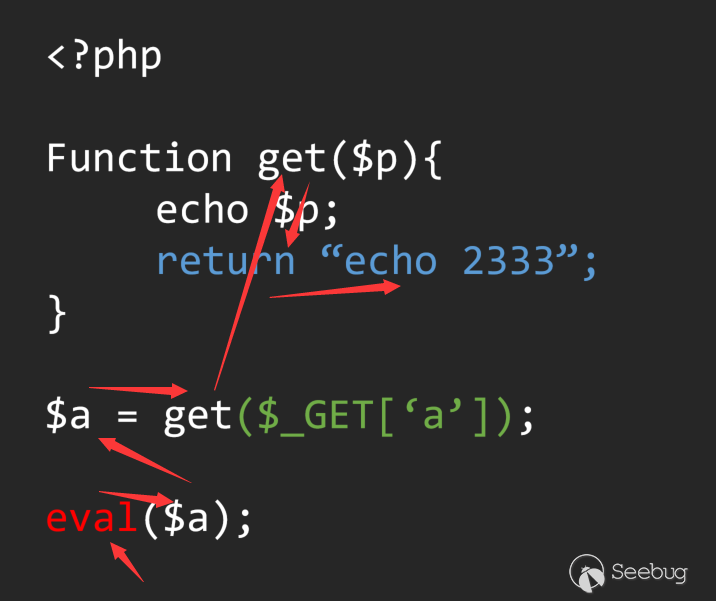
In this code, from the scope of the main syntax tree to the scope of the Get function. how to control the change of this scope is a major difficulty based on the analysis of the AST syntax tree. When we cannot in the code When avoiding the use of recursion to control the scope, the unified standard in the multi-layer recursion has become the core problem of the analysis.
In fact, even if you handle this simplest core problem, you will encounter endless problems. Here I give two simple examples.
(1) New function wrapper

This is a very classic piece of code. The sensitive function is wrappered to a new sensitive function, and the parameters are passed twice. In order to solve this problem, the direction of the information flow is reverse -> forward.

Control the scope by creating a large scope.
(2) Multiple call chain

This is a JS code with loopholes, it is easy to see the problem manually. But if you trace back the parameters in an automated way, you will find that there are multiple flow directions involved in the entire process.
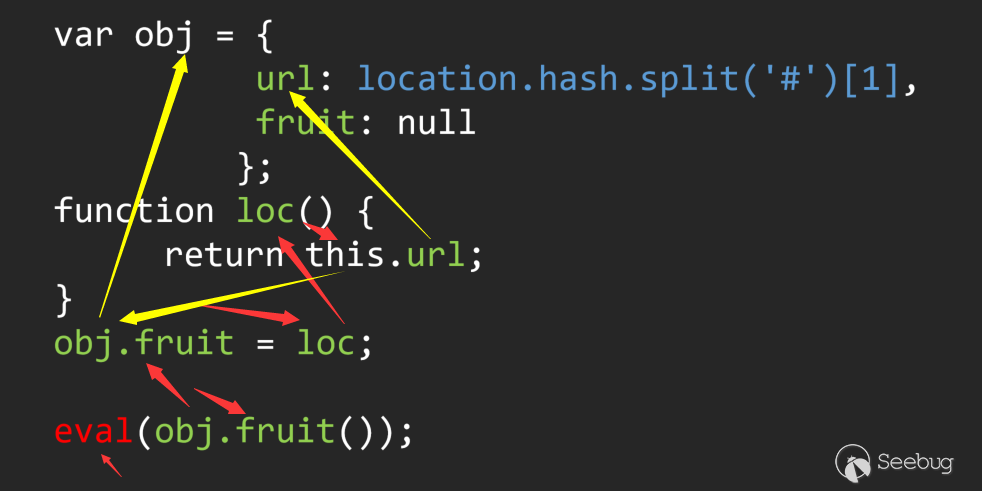
Here I use red and yellow to represent the two flow directions of the flow. This problem can only be solved by special backtracking for class/dictionary variables.
If it is said that the first two problems can be solved, there are still many problems that cannot be solved. Here is a simple example.

This is a typical global filter. And manual audit can easily see that it is filtered. But if in the process of automated analysis, when the source is backtracked to $_GET['a'], the information flow from Source to sink has been found. A typical false alarm occurs.
And the automated code audit tool based on AST is also playing a game with such problems, from the well-known Rips and Cobra in PHP automated code audit to my own secondary development Cobra-W.
- https://www.ripstech.com/
- https://github.com/WhaleShark-Team/cobra
- https://github.com/LoRexxar/Kunlun-M
They are all in different ways and methods to optimize the results of the information flow analysis, and the biggest difference is the two cores of high availability and high coverage that are inseparable.
- Cobra is a static automated code scanner developed by the Mogujie security team. The low false negative rate is the core of this type of tool, because Party A cannot bear the consequences of undiscovered vulnerabilities, which is why this type of tool focuses on optimization key.
After I found that it was impossible to trace the process of each stream perfectly, I put the positioning of the tool on the white hat for personal use. From the initial Cobra-W to the KunLun-M, I focused on the low false alarm rate.I will only recognize the accurate and reliable flow. Otherwise, I will mark it as a suspected vulnerability, and customize the custom function and detailed log in the multi-ring, so that the security researcher can target the target multiple times during the use process Optimize scanning.
For AST-based code analysis, the biggest challenge is that no one can guarantee that they can handle all AST structures perfectly. Coupled with the one-way flow-based analysis method,they cannot cope with 100% of the scenes. It is the problem faced by such tools (or, this is why the reverse engineering is chosen).
Code analysis based on IR/CFG
If you have a deep understanding of the principles of AST-based code analysis, you will find many disadvantages of AST. First of all, AST is the upper layer of IR/CFG in the compilation principle, and the nodes saved in the ast are closer to the source code structure.
In other words, analyzing AST is closer to analyzing code. In other words, the flow based on AST analysis is closer to the flow of code execution in the mind, ignoring most branches, jumps, and loops that affect execution. The condition of the process sequence is also a common solution based on AST code analysis. Of course, it is difficult to distinguish the consequences of ignoring from the result theory. So based on IR/CFG solutions with control flow, it is now a more mainstream code analysis solution. But it is not the only.
First of all, we have to know what IR/CFG is. - IR: It is a linear code similar to assembly language, in which each instruction is executed in sequence. Among them, the mainstream IR is a three-address code (quadruple). - CFG: (Control flow graph) control flow graph. The simplest control flow unit in the program is a basic block. In CFG, each node represents a basic block, and each edge represents a controllable control transfer. CFG represents the control flow chart of the entire code.
Generally speaking, we need to traverse the IR to generate CFG, which needs to follow certain rules. But we won't mention it if it is not the main content here. Of course, you can also use AST to generate CFG. After all, AST is a higher level.
The advantage of code analysis based on CFG is that for a piece of code, you first have a control flow diagram (or execution sequence). And then you get to the vulnerability mining step. Compared with AST-based code analysis, you only need to focus on the process from Source to Sink.
Based on the control flow graph, the subsequent analysis process is not much different from AST. The core of the challenge is still how to control the flow, maintain the scope, handle the branching process of the program logic, and confirm the Source and Sink.
Of course, since there is code analysis based on AST and code analysis based on CFG, there are naturally other types. For example, the mainstream fortify, Checkmarx, Coverity and the latest Rips in the market all use an intermediate part of the language constructed by themselves. For example, fortify and Coverity need to analyze an intermediate language compiled from source code. The source umbrella, which was acquired by Ali some time ago, even realized the generation of a unified IR in multiple languages. So the difficulty of scanning support for new languages has been greatly reduced.
In fact, whether it is based on AST, CFG, or a self-made intermediate language, modern code analysis ideas have become clear. And a unified data structure has become the base of modern code analysis.
The future - the .QL concept
.QL refers to an object-oriented query language for querying data from relational databases. Our common SQL is a kind of QL, which is generally used to query data stored in the database. Of course, what I mean here is more of the logic used to query the relationship, not related to SQL.
In the field of code analysis, Semmle QL is the first QL language that was born. It was first applied to LGTM and used for Github's built-in security scanning to provide free for the public. Immediately afterwards, CodeQL was also developed as a stable QL framework in the community of github.
So what is QL? What does QL have to do with code analysis?
First of all, let's review the biggest feature of code analysis based on AST and CFG. No matter what kind of middleware is based on the code analysis process, three concepts are inseparable, flow, Source and Sink. The principle of this kind of code analysis, whether it is forward or reverse, is to find in Source and Sink One stream. The establishment of this flow revolves around the flow of code execution, just like a compiler compiling and running, the program always runs in a stream. This way of analysis is Data Flow.
QL is to visualize each link of this flow, visualize the operation of each node as a state change, and store it in the database. In this way, by constructing the QL language, we can find nodes that meet the conditions and construct them into streams. Let me give a simple example:
<?php $a = $_GET['a']; $b = htmlspecialchars($a); echo $b;
We simply write the previous stream as an expression.
echo => $_GET.is_filterxss
Here is_filterxss is considered to be a mark of input $_GET. When analyzing this kind of vulnerability, we can directly express it in QL.
select * where {
Source : $_GET,
Sink : echo,
is_filterxss : False,
}
We can find this vulnerability (the code above is only pseudo-code). From such an example, it is not difficult to find that QL is actually closer to a concept. And it encourages the visualization of information flow so that we can use a more general way Go write rule screening.
It is also on this basis that CodeQL was born. It is more like a basic platform, so you don’t need to worry about the underlying logic. Whether to use AST or CFG or a certain platform, you can simplify the automated code analysis into We need to use what kind of rules to find the characteristics that satisfy a certain vulnerability. This concept is also the mainstream realization idea of modern code analysis, which is to transfer the demand to a higher level.
Like most security researchers, my work involves a lot of code auditing. Every time I audit a new code or framework, I need to spend a lot of time and cost to get familiar with debugging. When I first came into contact with automated code auditing , I just hope to help me save some time.
The first project I came across was Cobra from the Mogujie team.
This should be the earliest open source automated code audit tool for Party A. In addition to some basic feature scanning, AST analysis was also introduced as an auxiliary means to confirm vulnerabilities.
In the process of using it, I found that the first version of Cobra had too few restrictions on the AST, and did not even support include (then it was 2017). So I corrected Cobra-W and deleted a large number of open source vulnerabilities. Scanning solutions (such as scanning low-level packages of java),the needs of Party A that I can’t use...and deeply reconstructed the AST backtracking part (more than a thousand lines of code), and reconstructed the underlying logic to make it compatible windows.
In the long-term use process, I encountered a lot of problems and scenarios (the vulnerability sample I wrote to reproduce the bug has more than a dozen folders). The simpler ones are the new ones mentioned in the previous vulnerability sample Function encapsulation. And finally a large recursive logic is added to create a new scan task to solve it. I also encountered various problems such as Hook's global input, self-implemented filter function, branch and loop jump process, among which nearly 40 issues were created by myself...
In order to solve these problems, I refactored the corresponding syntax analysis logic according to the underlying logic of phply. Added the concept of Tamper to solve self-implemented filter functions. Introduced the asynchronous logic of python3, optimized the scanning process, etc...
It was during the maintenance process that I gradually learned the current mainstream CFG-based code analysis process, and also found that I should self-implement a CFG analysis logic based on AST...Until the emergence of Semmle QL, I realized it again the concept of data flow analysis. These concepts of code analysis are also constantly affecting me during the maintenance process.
In September 2020, I officially changed the name of Cobra-W to KunLun-M. In this version, I largely eliminated the logic of regular + AST analysis, because this logic violates the basis of streaming analysis, and then added I used Sqlite as a database, added a Console mode for easy use, and also disclosed some rules about javascript code that I developed before.
KunLun-M may not be an automated code audit tool with technical advantages, but it is the only open source code audit tool that is still maintained. In the course of years of research, I have deeply experienced the information barriers related to white box auditing. Mature white-box audit vendors include fortify, Checkmarx, Coverity, rips. And source umbrella scanners are all commercial closed-source. Many domestic vendors’ white-box teams are still in their early stages. Many things are crossing the river by feeling the stones and want to learn. In recent years, I have only seen the "Software Analysis" of Nanjing University. Many things can only read paper... I also hope that the open source of KunLun-M and this article can also be brought to the corresponding practitioners. Some help.
At the same time, KunLun-M is also a member of the Starlink project, adhering to the principle of open source and long-term maintenance. And it is hoped that KunLun-M can serve as a star to link every security researcher.
the Starlink project: - https://github.com/knownsec/404StarLink-Project
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1345/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1345/
如有侵权请联系:admin#unsafe.sh