2020-08-27 10:24:31 Author: www.4hou.com(查看原文) 阅读量:172 收藏
0x00 前言
Outlook Web Access的缩写是OWA,是Exchange用于Web方式收发邮件的界面,默认对所有邮箱用户开启。
通常,我们会使用浏览器访问OWA并读取邮件。但站在渗透测试的角度,我们需要通过命令行实现相同的功能。
目前我没有看到合适的开源代码和参考资料,于是打算基于自己的理解编写Python代码实现读取邮件和下载附件的功能。
0x01 简介
本文将要介绍以下内容:
- 实现思路
- 实现细节
- 编写程序需要注意的问题
- 开源代码
- 使用流程
0x02 实现思路
我暂时没有找到介绍OWA协议格式的资料,所以只能通过抓包的方式实现;
这里我使用Chrome浏览器自带的抓包工具,在Chrome界面按F12选择`Network`即可。
0x03 实现细节
1.登录操作
访问的url为`https://
需要发送POST请求,数据格式:
destination=https:///owa&flags=4&forcedownlevel=0&username=&password=&passwordText=&isUtf8=1
登录成功后,Cookie包括X-OWA-CANARY,可以作为判断依据
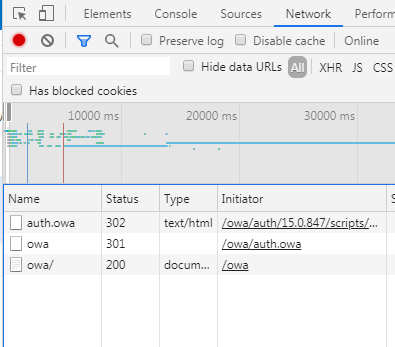
实际登录过程一共发送了三个数据包,如下图:

在程序实现上,使用Python的requests库不需要考虑这个细节。
完整的实现代码已上传至github,地址如下:
https://github.com/3gstudent/Homework-of-Python/blob/master/checkOWA.py
代码实现了对口令的验证;
这里需要注意OWA只能使用明文口令登录,无法使用hash。
2.访问资源
通过抓包发现,基本上每个操作会按照以下格式实现:
- 发送POST包
- Header中需要设置X-OWA-CANARY和Action
- X-OWA-CANARY可通过登录成功后返回的Cookie获得
- 需要设置Cookie
- POST包的数据格式为JSON
- 返回结果也是JSON格式
为了实现读取邮件内容和下载附件,我们需要通过程序实现以下操作:
(1)读取文件夹下所有邮件的信息
访问的url为"https://
对应的Action为FindItem。
POST包的数据格式:
{"__type":"FindItemJsonRequest:#Exchange","Header":{"__type":"JsonRequestHeaders:#Exchange","RequestServerVersion":"Exchange2013","TimeZoneContext":{"__type":"TimeZoneContext:#Exchange","TimeZoneDefinition":{"__type":"TimeZoneDefinitionType:#Exchange","Id":"SA Pacific Standard Time"}}},"Body":{"__type":"FindItemRequest:#Exchange","ItemShape":{"__type":"ItemResponseShape:#Exchange","BaseShape":"IdOnly"},"ParentFolderIds":[{"__type":"DistinguishedFolderId:#Exchange","Id":""}],"Traversal":"Shallow","Paging":{"__type":"IndexedPageView:#Exchange","BasePoint":"Beginning","Offset":0,"MaxEntriesReturned":999999},"ViewFilter":"All","ClutterFilter":"All","IsWarmUpSearch":0,"ShapeName":"MailListItem","SortOrder":[{"__type":"SortResults:#Exchange","Order":"Descending","Path":{"__type":"PropertyUri:#Exchange","FieldURI":"DateTimeReceived"}}]}}其中``需要修改为具体的文件夹名称,例如`inbox`或`sentitems`,`MaxEntriesReturned`我们可以指定为999999如下图

POST请求的返回结果也是JSON格式,包括文件夹中每个邮件的简要信息(例如标题、发件人、发送时间、是否已读和是否包含附件等,但不包括正文内容),同ews的`GetFolder`操作返回的结果基本相同
这里需要提取出每个邮件对应的`ConversationId`,用作读取邮件内容的参数
在程序实现上,我们需要使用requests中的session对象保持会话状态
具体的实现代码如下:
def ListFolder(url, username, password, folder, mode):
session = requests.session()
url1 = 'https://'+ url + '/owa/auth.owa'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
payload = 'destination=https://%s/owa&flags=4&forcedownlevel=0&username=%s&password=%s&passwordText=&isUtf8=1'%(url, username, password)
r = session.post(url1, headers=headers, data=payload, verify = False)
print("[*] Try to login")
if 'X-OWA-CANARY' in r.cookies:
print("[+] Valid:%s %s"%(username, password))
else:
print("[!] Login error")
return 0
print("[*] Try to ListFolder")
url2 = 'https://'+ url + '/owa/service.svc?action=FindItem'
headers = {
'X-OWA-CANARY': r.cookies['X-OWA-CANARY'],
'Action': 'FindItem',
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
body = {"__type":"FindItemJsonRequest:#Exchange","Header":{"__type":"JsonRequestHeaders:#Exchange","RequestServerVersion":"Exchange2013","TimeZoneContext":{"__type":"TimeZoneContext:#Exchange","TimeZoneDefinition":{"__type":"TimeZoneDefinitionType:#Exchange","Id":"SA Pacific Standard Time"}}},"Body":{"__type":"FindItemRequest:#Exchange","ItemShape":{"__type":"ItemResponseShape:#Exchange","BaseShape":"IdOnly"},"ParentFolderIds":[{"__type":"DistinguishedFolderId:#Exchange","Id":""}],"Traversal":"Shallow","Paging":{"__type":"IndexedPageView:#Exchange","BasePoint":"Beginning","Offset":0,"MaxEntriesReturned":999999},"ViewFilter":"All","ClutterFilter":"All","IsWarmUpSearch":0,"ShapeName":"MailListItem","SortOrder":[{"__type":"SortResults:#Exchange","Order":"Descending","Path":{"__type":"PropertyUri:#Exchange","FieldURI":"DateTimeReceived"}}]}}
body['Body']['ParentFolderIds'][0]['Id'] = folder
r = session.post(url2, headers=headers, json = body, verify = False)
for item in json.loads(r.text)['Body']['ResponseMessages']['Items'][0]['RootFolder']['Items']:
print('ConversationId:' + item['ConversationId']['Id'])代码会对返回结果的JSON格式进行解析,提取出每份邮件的`ConversationId`
(2)读取指定邮件的内容
访问的url为"https://
对应的Action为GetConversationItems。
POST包的数据格式:
{"__type":"GetConversationItemsJsonRequest:#Exchange","Header":{"__type":"JsonRequestHeaders:#Exchange","RequestServerVersion":"Exchange2013","TimeZoneContext":{"__type":"TimeZoneContext:#Exchange","TimeZoneDefinition":{"__type":"TimeZoneDefinitionType:#Exchange","Id":"SA Pacific Standard Time"}}},"Body":{"__type":"GetConversationItemsRequest:#Exchange","Conversations":[{"__type":"ConversationRequestType:#Exchange","ConversationId":{"__type":"ItemId:#Exchange","Id":""},"SyncState":""}],"ItemShape":{"__type":"ItemResponseShape:#Exchange","BaseShape":"IdOnly","FilterHtmlContent":1,"BlockExternalImagesIfSenderUntrusted":1,"AddBlankTargetToLinks":1,"ClientSupportsIrm":1,"InlineImageUrlTemplate":"data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAEALAAAAAABAAEAAAIBTAA7","MaximumBodySize":2097152,"InlineImageUrlOnLoadTemplate":"InlineImageLoader.GetLoader().Load(this)","InlineImageCustomDataTemplate":""},"ShapeName":"ItemPartUniqueBody","SortOrder":"DateOrderDescending","MaxItemsToReturn":20}}其中``需要修改为邮件对应的`ConversationId`这里需要注意,通过浏览器抓到的POST包数据格式,Python无法识别`false`和`true`,需要将`false`替换成0,将`true`替换成1
POST请求的返回结果是JSON格式,包括邮件的详细内容
这里需要提取出邮件附件对应的`Id`和`ContentType`,用作保存附件操作的参数
具体的实现代码如下:
def ViewMail(url, username, password, ConversationId):
session = requests.session()
url1 = 'https://'+ url + '/owa/auth.owa'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
payload = 'destination=https://%s/owa&flags=4&forcedownlevel=0&username=%s&password=%s&passwordText=&isUtf8=1'%(url, username, password)
r = session.post(url1, headers=headers, data=payload, verify = False)
print("[*] Try to login")
if 'X-OWA-CANARY' in r.cookies:
print("[+] Valid:%s %s"%(username, password))
else:
print("[!] Login error")
return 0
print("[*] Try to ViewMail")
url2 = 'https://'+ url + '/owa/service.svc?action=GetConversationItems'
headers = {
'X-OWA-CANARY': r.cookies['X-OWA-CANARY'],
'Action': 'GetConversationItems',
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
body = {"__type":"GetConversationItemsJsonRequest:#Exchange","Header":{"__type":"JsonRequestHeaders:#Exchange","RequestServerVersion":"Exchange2013","TimeZoneContext":{"__type":"TimeZoneContext:#Exchange","TimeZoneDefinition":{"__type":"TimeZoneDefinitionType:#Exchange","Id":"SA Pacific Standard Time"}}},"Body":{"__type":"GetConversationItemsRequest:#Exchange","Conversations":[{"__type":"ConversationRequestType:#Exchange","ConversationId":{"__type":"ItemId:#Exchange","Id":""},"SyncState":""}],"ItemShape":{"__type":"ItemResponseShape:#Exchange","BaseShape":"IdOnly","FilterHtmlContent":1,"BlockExternalImagesIfSenderUntrusted":1,"AddBlankTargetToLinks":1,"ClientSupportsIrm":1,"InlineImageUrlTemplate":"data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAEALAAAAAABAAEAAAIBTAA7","MaximumBodySize":2097152,"InlineImageUrlOnLoadTemplate":"InlineImageLoader.GetLoader().Load(this)","InlineImageCustomDataTemplate":"{id}"},"ShapeName":"ItemPartUniqueBody","SortOrder":"DateOrderDescending","MaxItemsToReturn":20}}
body['Body']['Conversations'][0]['ConversationId']['Id'] = ConversationId
r = session.post(url2, headers=headers, json = body, verify = False)
for item in json.loads(r.text)['Body']['ResponseMessages']['Items'][0]['Conversation']['ConversationNodes'][0]['Items']:
print('Subject:' + item['Subject'])
if 'From' in item:
print('From:' + item['From']['Mailbox']['Name'])
print('FromEmailAddress:' + item['From']['Mailbox']['EmailAddress'])
else:
print('From:' + 'Self')
for user in item['ToRecipients']:
print('ToRecipients:' + user['Name'])
print('ToRecipientsEmailAddress:' + user['EmailAddress'])
print('DisplayTo:' + item['DisplayTo'])
print('HasAttachments:' + str(item['HasAttachments']))
if item['HasAttachments'] == True:
for att in item['Attachments']:
print(' Name:' + att['Name'])
print(' ContentType:' + att['ContentType'])
print(' Id:' + att['AttachmentId']['Id'])
print('IsRead:' + str(item['IsRead']))
print('DateTimeReceived:' + item['DateTimeReceived'])
print('Body:\r\n' + item['UniqueBody']['Value'])
print('\r\n')
r.close()代码会对返回结果的JSON格式进行解析,提取出邮件的具体内容,如果包含多个附件,会逐个输出Name、ContentType和Id。
(3)下载附件并保存
访问的url为`https://
其中`
这里使用GET请求,返回结果的header中包括附件的文件名称,返回结果的网页内容为附件的内容
在保存附件时需要注意保存的格式,区分是文本文件还是二进制文件:
· 如果是文本文件,可保存`r.text`的内容
· 如果是二进制文件,可保存`r.content`的内容
具体的实现代码如下:
def DownloadAttachment(url, username, password, Id, mode):
session = requests.session()
url1 = 'https://'+ url + '/owa/auth.owa'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
payload = 'destination=https://%s/owa&flags=4&forcedownlevel=0&username=%s&password=%s&passwordText=&isUtf8=1'%(url, username, password)
r = session.post(url1, headers=headers, data=payload, verify = False)
print("[*] Try to login")
if 'X-OWA-CANARY' in r.cookies:
print("[+] Valid:%s %s"%(username, password))
else:
print("[!] Login error")
return 0
print("[*] Try to DownloadAttachment")
url2 = 'https://'+ url + '/owa/service.svc/s/GetFileAttachment?id=' + Id + '&X-OWA-CANARY=' + r.cookies['X-OWA-CANARY']
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
r = session.get(url2, headers=headers, verify = False)
pattern_name = re.compile(r"\"(.*?)\"")
name = pattern_name.findall(r.headers['Content-Disposition'])
print('[+] Attachment name: %s'%(name[0]))
if mode == 'text':
with open(name[0], 'w+', encoding='utf-8') as file_object:
file_object.write(r.text)
elif mode == 'raw':
with open(name[0], 'wb+') as file_object:
file_object.write(r.content)
r.close()完整的实现代码已上传至github,地址如下:
https://github.com/3gstudent/Homework-of-Python/blob/master/owaManage.py
使用示例:
(1)查看发件箱中的邮件
python owaManage.py 192.168.1.1 test1 DomainUser123! ListFolder
· 指定文件夹:sentitems
· 指定输出结果类型:full
如下图:

结果返回邮件总数和每个邮件的信息,这里获取邮件对应的ConversationId`:`AAQkADc4YjRlNDc1LWI0YjctNDEzZi1hNTQ5LWZkYWY0ZGZhZDM0NgAQAJdkOHS5cphDrNGlVbVpnIo=
(2)读取邮件内容
python owaManage.py 192.168.1.1 test1 DomainUser123! ViewMail
· 指定邮件对应的ConversationId
如下图:

结果返回邮件的具体内容,这里获得附件111.txt的类型为`text/plain`,对应的
Id:AAMkADc4YjRlNDc1LWI0YjctNDEzZi1hNTQ5LWZkYWY0ZGZhZDM0NgBGAAAAAABEBlGH6URWQp6Nlg9RxLmyBwA1ZCfAg9a0Sq75no2JOzsqAAAAAAEKAAA1ZCfAg9a0Sq75no2JOzsqAAAAAByNAAABEgAQAO2T/TJsdj9Emo9dwiMqlrM=
(3)下载附件
python owaManage.py 192.168.1.1 test1 DomainUser123! DownloadAttachment
· 指定附件对应的Id
· 指定保存格式为text
如下图:

0x04 小结
本文介绍了编写Python代码实现通过Outlook Web Access(OWA)读取Exchange邮件的实现细节,记录开发过程。
本文为 3gstudent 原创稿件,授权嘶吼独家发布,如若转载,请注明原文地址
如有侵权请联系:admin#unsafe.sh