文章探讨了AI平台在企业中的应用及其带来的安全风险,包括未经授权的Shadow AI使用、Prompt Injection和Data Poisoning等威胁,并介绍了Cisco的AI Defense解决方案以应对这些挑战。 2025-3-11 17:31:53 Author: roccosicilia.com(查看原文) 阅读量:15 收藏
Avevo accennato il tema qui e recentemente l’argomento è emerso in alcune chiacchierate aziendali, ho quindi pensato di riprendere l’argomento strutturandolo meglio visto che mi è stato chiesto di trattarlo in un prossimo evento online.
Come i frequentatori di LinkedIn sanno faccio parte del team di NTS Italy, azienda che è ricca di iniziative sia interne che pubbliche; in occasione del Cisco Live (l’evento che ogni anno Cisco organizza anche nella versione europea) i team che hanno partecipato all’evento si fanno carico di riassumere i temi più interessanti per i colleghi (in senso ampio) che non hanno potuto partecipare. Al sottoscritto è stato chiesto di parlare di uno specifico tema: la sicurezza delle informazioni in relazione all’impiego delle piattaforme AI.
La sessione sarà trasmessa live il 12 marzo (credo sarà messa a disposizione anche la registrazione, in caso aggiungerò il link) ma come faccio spesso ho deciso di scrivere due righe sull’argomento in relazione all’approccio di uno specifico vendor, Cisco in questo caso, sul tema.
Gli strumenti che fanno uso di AI come i LLM sono rapidamente entrati nella routine di molti utenti che ne fanno diversi usi. Non tocco, in questo pezzo, i temi legati agli aspetti sociali/psicologici/neurologici/***ogici, l’obiettivo del post è analizzare se e come questi strumenti possono aumentare i rischi per la sicurezza delle informazioni che gli utenti maneggiano quotidianamente.
È abbastanza ovvio che inserire un contenuto, sia esso un prompt o un documento, nel LLM di turno significa anche condividere il contenuto con il provider che sta erogando il servizio, in quale lo tratterà nel rispetto delle proprie policies, a prescindere dalle politiche che la nostra company ha deciso per il trattamento dei dati aziendali. Faccio un esempio per comprendere meglio il problema: se l’utente vuole una sintesi di un documento di 100 pagine e per farlo utilizza ChatGPT, il contenuto del documento deve essere condiviso con OpenAI e se il documento è categorizzato come interno, riservato o classificato si sta di fatto violando una politica aziendale.
A questa tipologia di rischio ci si sta riferendo con il termine Shadow AI, ovvero l’utilizzo di strumenti e piattaforme AI a fini operativi/lavorativi senza l’autorizzazione dell’azienda e dell’owner dei dati oggetto dell’attività. Lo potremmo considerare come un sotto-insieme del tema Shadow IT.
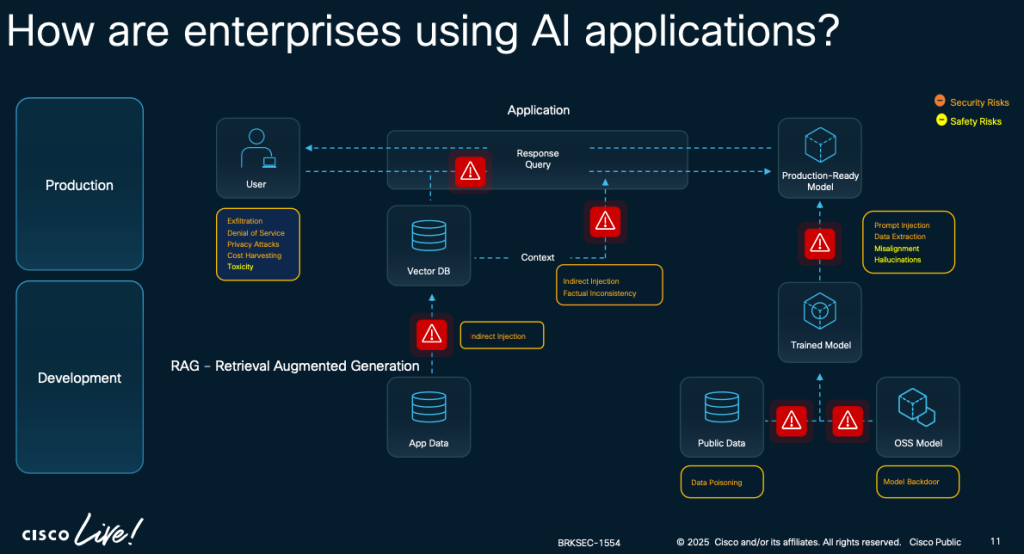
Un altro tema da considerare è più tecnico ed è relativo all’implementazione e l’integrazione delle piattaforme AI in tools e strumenti software. Lo sviluppo di software in grado di utilizzare le funzionalità delle piattaforme AI porta ad interrogarsi sulla sicurezza di queste applicazioni. Prendo in prestito una slide pubblica presentata al Cisco Live (le trovate tutte qui: https://www.ciscolive.com/c/dam/r/ciscolive/emea/docs/2025/pdf/BRKSEC-1554.pdf) per discutere il tema.

Di base chi sviluppa software che fanno uso di modelli di AI deve far fronte a diversi problemi di sicurezza, ce ne sono due che hanno attirato la mia attenzione e che mi sembrano abbastanza emblematici:
- il rischi legati all’injection di contenuti “malevoli” nel prompt
- il rischio di poisoning del modello
In entrambi i casi si tratta di problemi legati alla logica di funzionamento dei modelli di cui lo sviluppatore deve tener conto e su queste due casistiche vorrei spendere due parole in più.
Nota: come accennato i due scenari non sono gli unici, OWASP ha redatto la tipica Top10 relativa ai rischi per i LLM che vi suggerisco di leggere con attenzione.
Prompt Injection
Una vulnerabilità di Prompt Injection si verifica quando un input dell’utente altera il comportamento o l’output di un LLM in modi non previsti. Le vulnerabilità di Prompt Injection derivano dal modo in cui i modelli gestiscono i prompt, potenzialmente inducendoli a violare linee guida, generare contenuti dannosi, consentire accessi non autorizzati o influenzare decisioni critiche.
L’abuso di questa vulnerabilità è di particolare impatto quando il modello viene utilizzato da un’azienda come interfaccia pubblica a propri servizi.
Fonte: OWASP.
Data Poisoning
Il data poisoning si verifica quando i dati utilizzati per il pre-training, il fine-tuning o l’embedding vengono manipolati per introdurre vulnerabilità, backdoor o bias. Questo può compromettere la sicurezza, le prestazioni e l’etica del modello, portando a risultati dannosi o malfunzionamenti. I principali rischi includono degrado delle prestazioni, contenuti tossici o distorti e sfruttamento dei sistemi collegati. Essendo un attacco all’integrità del modello, il data poisoning altera la sua capacità di fornire risposte accurate, soprattutto quando proviene da fonti esterne non verificate.
Riporto un esempio di alterazione (involontaria) della capacità di un LLM di fornire risposte coerenti con la richiesta:

Il modello, in questo caso, è stato addestrato con dei dati che non gli hanno consentito di “imparare” come funziona un orologio a lancette o meglio non lo sa riprodurre. Paradossalmente se gli si chiede di analizzare l’immagine e leggere l’ora la risposta sarà corretta.
Inoltre, i modelli distribuiti tramite repository condivisi o open-source possono contenere minacce aggiuntive, come codice malevolo nascosto (ad esempio, tramite malicious pickling).
Fonte: OWASP.
Non essendo un addetto ai lavori (in ambito AI intendo) ci sono diversi elementi che mi mancano per una completa comprensione del problema. È evidente che, come per molte tecnologie, un utilizzo improprio e non controllato dello strumento può far danni. Inoltre, mia opinione personale, ho la sensazione che la mancanza di consapevolezza legata ad una generale ignoranza sul funzionamento di questi strumenti faccia da fattore moltiplicatore per i rischi correlati.
In questo post mi limito a riportare la visione ci Cisco sul tema del monitoraggio e mitigazione. Non mi dilungo eccessivamente in quanto è il tema che presenterò domani (12 marzo) durante il webinar. L’approccio di Cisco AI Defense prevede tre punti di “controllo” che vi racconto brevemente.
Discovery e monitoraggio delle integrazione con modelli AI di terze parti: è evidentemente indispensabile sapere quali nostre applicazioni/utenti fanno uso si modelli AI esterni, che dati condividono e che risposte ottengono. Questa funzione prende il nome di AI Cloud Visibility.
Individuazione di eventuali rischi e vulnerabilità legati al modello che si sta utilizzando: esattamente come ci siamo abituati a condurre security test per le applicazioni “tradizionali” dobbiamo governare un processo di verifica e gestione delle vulnerabilità dei modelli AI. Ci sono diversi modi per procedere in questa direzione, auspicabile l’utilizzo di strumenti dedicati. Questa funzione fa parte della componente AI Model and Application Validation di Cisco AI Defense.
Terzo elemento, credo il può complesso a livello tecnico, la protezione a runtime, ovvero monitorare il comportamento del modello mentre è in uso dall’utente. Sul piano tecnico significa validare la legittimità degli input dell’utente ed assicurarsi che le risposte del nostro modello non deviino dai parametri di sicurezza che abbiamo definiti. Questa funzione è la AI Runtime Protection di Cisco AI Defense.
Discutendo con diverse figure molto più competenti di me in merito al tema AI mi è stato fatto notare che queste misure di sicurezza dovrebbero far parte del software/modello stesso e che sono effettivamente molto complesse da gestire in quanto sono di fatto limiti controllati al comportamento che il modello “impara”.
La tecnologia che stiamo introducendo in alcuni processi produttivi e, in alcuni casi, decisionali ha un elevato grado di complessità ed ho la sensazione che il tasso di adozione cresca molto più rapidamente del tasso di comprensione, ammesso che quest’ultimo stia crescendo.
Sul piano della sicurezza dei dati è “una valle di lacrime” (cit.) e, come accaduto anche in altre epoche, ci troviamo a dover gestire problemi in esercizio, a cose fatte. L’ennesima occasione per ricordarci quanto sarebbe stata utile un’analisi del rischio prima dell’adozione di una nuova tecnologia.
如有侵权请联系:admin#unsafe.sh