今天要介绍的论文Balancing Analysis Time and Bug Detection: Daily Development-friendly Bug Detection in Linux来自2024年的USENIX ATC,作者是来自日本东京都的庆应义塾大学(Keio University)和法政大学(Hosei University)的研究人员(传说这两所学校很多不学习的富二代,剩下那些学生要拉高平均值就不得不很厉害)。来自日本的研究人员和世界其他国家地区的研究人员有很不一样的气质,他们的论文没有那么多套路(对比一下两天前的推荐),就是要解决实际问题:
这篇论文的思路非常直截了当:给你3小时,Linux内核代码全部扫描一遍,还要保证能够检测到问题。研究程序分析的同行都清楚,如果要把分析的精度提上去,就很容易变成像国际象棋和围棋里面无限进行深度搜索,一头栽进去就出不来了。但是你要降低分析的精度,又可能会漏掉真正的bug,所以怎么去权衡(trade off)到底在什么时候需要精确,什么时候需要直觉,有点像一门艺术对不对?
不少人应该用过Clang Static Analyzer(CSA)和CppCheck这类常见的C/C++代码静态漏洞扫描工具:CSA可以配置的选项更多,也可以指定扫描的深度,而CppCheck相对来说更简单,不过这两个工具都已经牺牲了很多分析精度去换取分析的效率,而就算这样,对Linux内核(5.x)进行完整的扫描,最简单的CppCheck也需要两个半小时左右的时间,而CSA需要27小时(更多工具的具体分析时间开销见下表,这里不考虑无限多核并发,作者的实验设备还是已经沦为电子垃圾的Intel Xeon E5-2620这种16核老设备,配上96G内存)。这种快速扫描的效果显然不能说是很理想:作者分析了64个Linux内核bug的提交报告和patch,发现其中只有24个报告中提到该问题的发现得到了静态分析工具的辅助支持。很明显,现有的工具对发现bug的帮助还没有达到一个“居家旅行必备”的程度,所以本文作者要考虑一些新的设计。
也许是经过了很多实践,本文作者提出了一种虽然使用了标准的技术方法,但是在各类配置上进行了精心处理的静态分析——FiT analysis(此处和清华FIT楼无关,全称是finger traceable analysis),这个FiT分析技术其实就是如下配置:
整体分析限定在只对单个编译单元(也就是单个源代码文件)进行,不搞那种把所有源代码合并成一个巨大的整体来分析的操作;
数据流分析执行inter-procedural分析;
数据流分析不考虑path-sensitive分析;
数据流分析对结构体的具体子元素(field-based)进行追踪,而且仅考虑函数内的别名信息(with intra-procedural alias information();
数据流分析不考虑indirect function call;
如果实施了这种配置,就可以认为是一种FiT分析(有没有专利申请里面的权利要求书的既视感)。之所以这么设计,也不是完全拍脑袋想出来,作者实际上是通过去逐个分析了105个Linux内核patch,总结了它们的特点(如下表所示),然后针对特性进行的设计,反正作者说了他们的研究就是针对Linux内核的静态扫描,也没宣传这种技术放之四海而皆准。虽然现在很多审稿人有一种莫名其妙的大一统理论的优越感,我们不要忘记了人类的认知过程是先有第谷·布拉赫然后才有开普勒和牛顿爵爷的。因此,我们也要为这种实践精神点一个赞。
我们来看两个例子(下图),第一个例子如果你熟悉G.O.S.S.I.P的工作Goshawk(https://goshawk.code-analysis.org/),那绝对不会觉得陌生,Goshawk通过识别自定义内存函数(这个例子里面是create_ttc_table、create_ttc_table_groups和destroy_flow_table)来简化数据流分析,从而高效识别内存漏洞(实际上Goshawk也能在几个小时里面搞定整个Linux内核的代码扫描)。但是对于这种简单的例子(所有涉及的函数都在同一个源代码文件里面),只需要按照FiT分析的配置就能轻松扫描出来。而下图中的第二个例子(一个reference counting bug),最近几年也有很多论文在讨论怎么设计更加复杂的refcount分析机制,可本文作者指出,并非程序分析不够好,而是程序分析不够简单:这个例子里面很明显就是一个在错误处理路径上忘记了对refcount进行减操作的bug(第7行是patch加上去的),所以基本的程序分析就应该能发现。
作者觉得,现在的大型软件的代码库里面存在太多这种“基础”的bug,只要静态代码分析工具足够实用,不需要什么高超的技艺也应该不难发现,但实际情况是CSA和CppCheck这种扫描的效果实在是糟糕,完全是因为它们的设置不够贴近生活。作者于是在CSA和LLVM-clang的基础上搞了一套框架,叫做FiTx,目标就是提供一个可以灵活扩展、同时又能支持快速代码扫描的分析系统。这整个系统的实现比较标准,基本上就是按照前面的配置原则来对标准的数据流分析、控制流遍历等等做一些细化。里面唯一一个比较特殊的点,看起来和Goshawk的思路也非常的像(然而它丝毫不提Goshawk),就是对函数的内存操作生成摘要(summary),当然FiTx是在LLVM IR上做的,而Goshawk是在CSA的基础上进行的改进,直接针对源代码(AST)进行分析。
FiTx最大的优点除了快,可能在于它的开发相当友好。论文作者给出的代码相当的完善,不仅不是空repo,还能够完整编译和测试,而且代码风格也很清晰。作者还专门强调:
Each plugin consists of less than 5 states and transitions, and requires less than 50 Lines of C++ code
希望了解这个代码的读者,推荐大家去阅读一下,并且动手编译测试一下。
在实验环节,作者用Linux内核(v5.15)进行了测试,一共分析了20634个源代码文件,在作者设定的分析配置下,分析时间只用了2小时33分钟(考虑到人家用的还是个E5 2620的CPU,你自己去淘宝看看多少钱一个)。作者还顺带测试了一下如果修改分析配置,分析时间的变化情况(见下表):
而FiTx框架和它的一系列detector一共报告了113个可能的问题,最后经过作者手工确认有47个是true positive,对于生产开发,这个报告的数字和比例都相当友好!而且和CSA、CppCheck对比,作者这个工具的优势还是比较明显的(见下表):
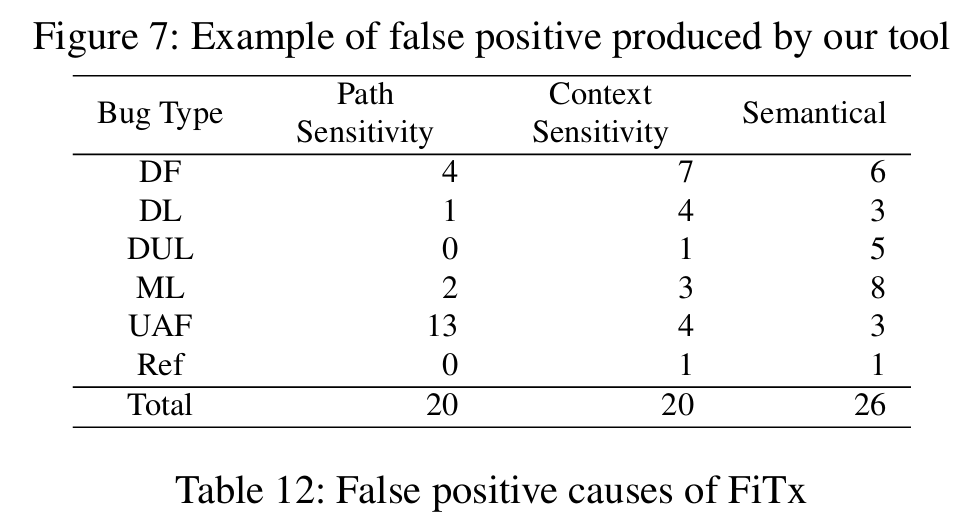
最后作者也统计了(因为削减了一些分析精度导致的)误报的情况,可以看出,不精确的分析一定程度上增加了分析结果的不准确,但是都在可接受的范围内,况且能把代码分析完就是很重要的,执着于分析精度也不见得是什么好事吧?
G.O.S.S.I.P 推荐指数:
strong accept(然而从作者提交的bug来看,这个似乎是2022年就完成的工作,和
Goshawk同年,也是过了好些年才发出来)
论文:https://www.usenix.org/system/files/atc24-suzuki.pdf
代码:https://github.com/sslab-keio/FiTx
如有侵权请联系:admin#unsafe.sh