原文标题:Characterization of Tor Traffic using Time based Features原文作者:Arash Habibi Lashkari, Gerard Dra 2025-1-13 15:15:0 Author: mp.weixin.qq.com(查看原文) 阅读量:6 收藏
原文标题:Characterization of Tor Traffic using Time based Features
原文作者:Arash Habibi Lashkari, Gerard Draper Gil, Mohammad Saiful Islam Mamun, Ali A. Ghorbani
原文链接:https://doi.org/10.5220/0006105602530262
发表会议:ICISSP 2017
笔记作者:宋坤书@安全学术圈
主编:黄诚@安全学术圈
1、背景介绍
流量分类是指在网络上对数据流进行识别和分类的过程。随着加密技术的普及,传统的流量分类方法面临越来越大的挑战。Tor是目前最流行的隐私增强工具,通过加密和隧道化流量来匿名化用户的身份和活动。本文关注如何通过分析Tor流量中的时间特征,降低流量的隐私性以识别不同类型的应用流量。
目前,已有多种研究方法试图识别和分类Tor流量。例如,AlSabah等人提出了一种基于QoS的机制,通过Tor电路生命周期、数据传输量等特征来区分不同类型的Tor流量[1]。Bai等人通过特定的字符串、数据包长度和频率进行指纹识别,成功区分了Tor和Web-Mix网络[2]。He等人采用隐马尔可夫模型(HMM)分析Tor流量,并将其分类为P2P、FTP、即时消息和Web,达到了92%的准确率[3]。这些研究结合了多种特征来识别Tor流量的类型,并在不同的应用场景中取得了一定成果。
然而,本文的创新在于专注于时间特征来分析Tor流量,而非依赖传统的流量特征如包大小、端口和标志等。具体来说,研究重点是通过流量的时间约束来区分不同类型的应用。例如,实时语音应用(如VoIP)有严格的带宽要求,而音频流媒体应用的带宽上限则由服务器和网络容量决定。这些差异在时间统计上有所体现,可以通过这些时间特征来识别流量类型。
2、数据集生成
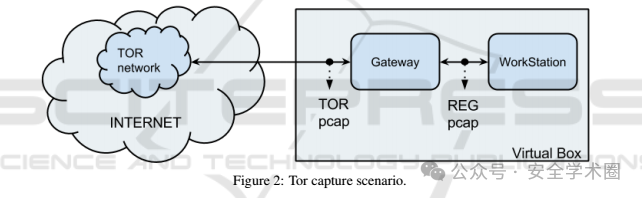
本文生成了一个包含8种流量类型(浏览、聊天、音频流、视频流、邮件、VoIP、P2P和文件传输)的Tor流量数据集。该数据集包含来自多个代表性应用(如Facebook、Skype、Spotify等)的真实流量。所有流量通过Whonix操作系统配置路由至Tor网络,分别捕获工作站和网关虚拟机的传出流量,即常规(REG)流量和Tor流量,生成相应的.pcap文件用于后续标记。流量捕获场景如下图:
数据标记采用两步法:首先从工作站捕获流量并确认应用类型,然后将相应的Tor流量标记为同一应用类型。由于Tor的电路路由机制,所有通过同一电路的流量将共享相同的加密路径,因此不同类型的流量无法被直接区分。这种标记方法可能会引入噪声,例如将某些流量错误标记为其他类型,从而影响分类准确性。数据集涵盖了多种应用类型流量,保证了数据集的多样性和代表性,为Tor流量分析和应用分类提供了丰富的实验数据。
3、网络流生成和时间特征提取
本文介绍了如何定义网络流并提取与时间相关的特征。流被定义为具有相同源IP、目标IP、源端口、目标端口和协议(TCP或UDP)的数据包序列。由于Tor网络仅支持TCP协议,因此所有流量都被视为TCP流。为了生成这些流并提取相应的特征,研究使用了ISCXFlowMeter工具。该工具支持生成双向流(即正向流和反向流),并计算每个流的多个统计特征,特别是时间相关的特征。研究还考虑了不同的流超时设置(10s、15s、30s、60s、120s)来探讨超时值对结果的影响。
特征提取的重点在于两种时间相关的度量方法:一种是测量包间到达时间和流的活动时间,另一种是在固定时间窗口内计算其他变量,如每秒字节数和每秒数据包数。论文共提取了23个特征,具体包括:前向(fiat)、反向(biat)和双向(flowiat)包间到达时间;流的活动(active)与空闲(idle)时间;每秒字节数(fb psec)和每秒包数(fp psec);以及流的持续时间(duration)。这些特征有助于分析Tor流量的时序行为,并为后续的流量分类任务提供支持。
4、实验设置
本文定义了两个实验场景来测试基于时间的特征。场景A关注于Tor流量的检测,而场景B则专注于识别Tor流量中的应用类型。
场景A通过合并两个数据集来创建:一个是本论文中的Tor数据集,另一个是Draper-Gil等人提供的加密流量数据集。本文从这两个数据集中生成流并提取时间特征,标记Tor数据集中的流为“Tor”,Draper-Gil数据集中的流为“NonTor”。
场景B则只使用本论文中的Tor数据集,生成不同应用(如浏览、音频流、聊天等)的流,并根据工作站上执行的应用程序进行标记。
4.1 特征选择和模型训练
本文使用Weka平台运行实验,数据集被分为测试集(80%)和验证集(20%)。其中,测试集用于特征选择和模型训练,验证集用于评估模型的最终性能。首先,针对不同的流超时设置的测试数据集,应用不同的特征选择算法(CfsSubsetEval+BestFirst,SE+BF和Infogain+Ranker,IG+RK)来选择最佳特征,并根据加权平均精确度和召回率来评估其效果。基于选择的特征,使用不同的机器学习分类算法进行训练和验证。场景A使用ZeroR、C4.5和KNN算法进行分类,而场景B则使用Random Forest、C4.5和KNN算法进行分类。所有模型在测试集上通过10折交叉验证进行训练,最终评估则在验证集上进行。分类性能通过精确度(Precision)和召回率(Recall)两个指标进行评估,
5、实验结果分析
5.1 场景A实验结果分析
在场景A中,使用了 SE+BF 和 IG+RK 两种特征选择方法, SE+BF 将特征从23个减少到5个,而 IG+RK 则按权重排序所有特征。在测试阶段,C4.5和KNN算法表现优于ZeroR,尤其在短超时值(如10秒)时,精确度和召回率较高。对于长超时值(如120秒),虽然精确度较高,但结果趋近ZeroR的下限,表明数据集的不平衡,因此选择了15s的数据集进行验证。场景A的模型训练结果如下图所示:
验证结果显示,C4.5算法在精确度和召回率上都超过0.9,能够有效检测Tor和非Tor流量。ZeroR仅能识别非Tor流量,表现较差。C4.5的混淆矩阵显示,大部分Tor流量被正确分类,少量被误分类为非Tor流量。C4.5算法的混淆矩阵如下表:
| a=Tor | b = nonTor | |
|---|---|---|
| a | 1053 | 74 |
| b | 58 | 9567 |
场景A的验证实验结果如下图:
5.2 场景B实验结果分析
在场景B中,研究的目标是对Tor流量进行分类,识别出8种不同类型的流量。特征选择方法同样使用了 SE+BF 和 IG+RK ,通过特征 SE+BF 将特征从23个减少到10个,使用 IG+RK 则减少到15个。测试结果显示,流超时较短(如15s)的数据集表现最佳,算法效率随着流超时的增加而下降。随机森林算法在使用IG+RK特征选择方法时表现最好,因此被选为验证实验的算法。场景B的模型训练结果如下图所示:
验证结果显示,随机森林(Random Forest)算法的精确度和召回率均为最佳,分别为0.843和0.838,C4.5和KNN的精确度和召回率也表现不错。针对不同流量类型,VOIP 和 P2P 类型的流量分类效果较好,BROWSING类别的误报较多,这是由于由于许多应用程序都是基于Web的或使用https作为通信协议。随机森林算法的混淆矩阵如下表:
| a = VOIP | b = AUDIO | c = BROWSING | d = CHAT | e = MAIL | f = FT | g = P2P | h = VIDEO | |
|---|---|---|---|---|---|---|---|---|
| a | 292 | 1 | 11 | 0 | 0 | 2 | 2 | 1 |
| b | 1 | 81 | 15 | 1 | 2 | 0 | 0 | 2 |
| c | 2 | 9 | 193 | 12 | 3 | 1 | 0 | 19 |
| d | 0 | 1 | 24 | 24 | 1 | 0 | 0 | 0 |
| e | 0 | 3 | 10 | 0 | 23 | 1 | 0 | 2 |
| f | 0 | 0 | 8 | 1 | 2 | 101 | 1 | 5 |
| g | 1 | 0 | 1 | 0 | 0 | 0 | 144 | 1 |
| h | 2 | 3 | 25 | 1 | 1 | 4 | 1 | 87 |
场景B的验证实验结果如下图:
6、本文贡献
提出了基于时间特征的Tor流量检测和应用识别方法,实验结果表明,仅使用这些时间特征就能有效地检测Tor流量,并且能区分不同的应用流量。
研究了流超时对流量分类效率的影响,实验结果表明较短的流超时(15秒)能够提高分类器的效率,而传统的600秒流超时假设并不适用于Tor流量分类。
发布了Tor流量标签数据集和生成工具,方便其他研究者复制实验并进一步研究。
[1]Mashael AlSabah, Kevin Bauer, and Ian Goldberg. "Enhancing Tor's performance using real-time traffic classification." Proceedings of the 2012 ACM Conference on Computer and Communications Security (CCS '12). Association for Computing Machinery, 2012, pp. 73–84. https://doi.org/10.1145/2382196.2382208.
[2]X. Bai, Y. Zhang, and X. Niu. "Traffic Identification of Tor and Web-Mix." Proceedings of the 2008 Eighth International Conference on Intelligent Systems Design and Applications, Kaohsiung, Taiwan, 2008, pp. 548–551. https://doi.org/10.1109/ISDA.2008.209.
[3]He, G., Yang, M., Luo, J., & Gu, X. (2014). "Inferring application type information from Tor encrypted traffic." Proceedings of the 2014 Second International Conference on Advanced Cloud and Big Data, Huangshan, China, 2014, pp. 220–227. https://doi.org/10.1109/CBD.2014.37.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh