安全漏洞风险会对业务带来严重影响,外部黑客通过对线上业务的渗透攻击,可拖取敏感资产数据、中断在线服务等。国内外不少知名公司都曾因安全问题导致数亿用户信息泄露。所以在越早期发现和修复,能更有效缓解现网威胁,从而保障业务的安全稳定运营。在研发阶段代码编写时实现安全漏洞检测和修复是一种高效且准确的方式。
![]()
腾讯啄木鸟代码安全团队依托腾讯混元大模型的超强代码理解和安全分析能力,在SQL注入威胁检测场景验证中,新增上百个有效的漏洞检测策略,相比传统方法人效比提升3.8倍,在Github高star项目上斩获10+0day漏洞。传统的安全检测方案,主要由检测引擎+策略规则组成。通过对历史badcase的持续跟踪分析,我们发现策略规则的缺失是造成漏水的重要原因。主要的方法途径有两种:一种是安全人员根据经验积累,针对一些常见的业务框架进行检测策略添加;一种是通过现网的case反向驱动策略添加(即新增一个漏水的case后,复盘发现属于策略缺失导致的话,就针对性的添加检测策略)。这两种传统方法均需要投入大量的人力,且易陷入被动救火状态而无法主动控盘。
![]()
在大型互联网企业中,研发团队众多,且不同的业务团队根据业务的特性与场景的不同,会选择适合各自团队和业务场景的开发框架。并且在一些场景,还会自研或者针对框架进行二次封装。诸如此类的问题,对策略规则的覆盖率提出了挑战:需要覆盖不同场景的各类研发框架。
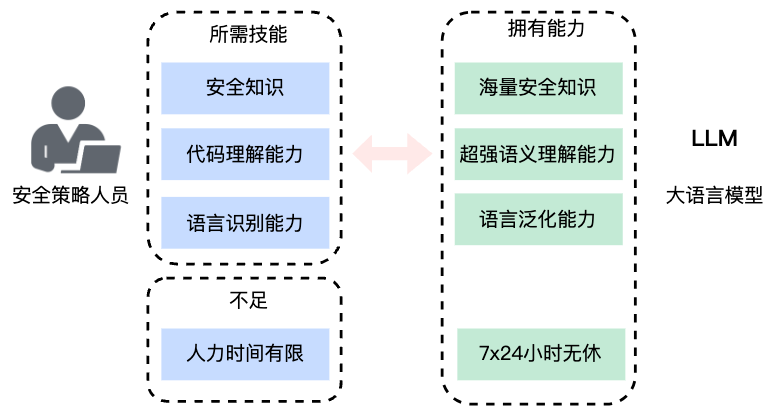
在检测策略规则编写的场景,安全人员需要审计业务代码,理解业务代码的语义,根据安全知识,来编写不同的策略规则。这中间主要需要三种技能,分别是:这三种能力正是大模型的强项,同时大模型还可以做到7x24小时无休,既解决了人才经验的问题、也解决了人力时间的问题。借助大模型能力,将策略规则编写工作交给它,高效且快速的分析代码语义,增加检测策略。下面是我们的一些demo实验,来印证大模型在此场景下的效果。![]()
得益于海量的互联网训练数据填喂,大模型能够正确识别开源框架这并不意外。
更值得称赞的是,针对业务自研的框架,如下图在没有业务背景知识的情况下,大模型也能够根据用户提供的代码上下文信息,识别出当前的代码的语义逻辑,并推测业务自研框架的功能。
![]()
结合大模型的超强代码理解能力, 我们建设了如下的工作流程:1、规则初筛:通过大模型针对全量代码都进行分析从成本性价比角度来看并不是最优,我们通过一些历史经验的初筛,先筛出一批疑似存在问题的代码函数块交给大模型处理,提升效率和质量。2、大模型提取:将规则初筛后的函数代码块,结合大模型的能力,在这些函数中提取相关可疑代码行,同时进行过滤去重。3、大模型生成规则:根据提取后的代码, 结合大模型能力,提取相关规则所需的信息,根据规则模板,生成检测规则。4、规则上线:针对大模型新增的检测策略规则,集成到现有的检测能力中,上线验证效果。![]()
在使用大语言模型进行工程化落地时,需要相关工作流程的输入与输出都是可控且精准的。由于chat类模型的特性,大语言模型在嵌入到工作流程中,相关的输出往往不能够做到100%可控。这里我们针对实际应用过程中遇到的工程化问题,分享两个已验证的优化tips。
场景1:复杂逻辑场景
使用大模型从一段复杂代码中提取检测策略所需要的代码行时,由于业务的代码情况多样、逻辑复杂,有可能出现初期输出的结果不符合预期。【优化Tips】借鉴ReAct提示工程方法,来让大模型根据每一步的执行结果进行反思,是否满足prompt的要求,从而提升提取效果的准确率。场景2:多判断条件场景
在大模型筛选疑似污点源的代码行时,需要针对提取的代码正确与否进行多个条件的判断,只有多个条件都满足才说明是符合要求的。此时引入一个新的问题:在一个prompt中让大模型进行多次判断,效果相对不稳定。【优化Tips】尝试拆分成多个prompt来让大模型做判断题,只有当多次的判断结果都正确,才说明当前的结果是我们所需要的。同时这一步也能优化效率,将大模型输出进行拆分,当一个条件不能满足时进行跳过,可降低调用大模型处理的次数。通过上述的优化Tips,在工程化落地保证准确率的同时,处理效率也有大幅提升。在同样的并发数下,从每分钟处理不足百个函数,提升至每分钟处理300+个。由于业务代码场景千变万化,通过人工分析生成检测策略去匹配所有的代码场景,一直存在着耗时耗力的短板。而腾讯混元大模型集自动化、代码语义理解能力和泛化能力为一体。以大模型为基础,结合安全专家经验辅助,能够大大提升代码安全检测策略迭代的效率问题。我们的探索当然不会止步于策略规则层面的更新维护。基于当前的探索验证,结合业务特性和需求痛点,在传统通用安全漏洞场景之外,我们也在积极尝试在代码编写阶段帮助业务团队提早发现安全风险,助力业务的安全稳定运营。同时,大模型为主的代码安全漏洞挖掘我们也有新的探索成果,详见:《AI猎手:我们用大模型挖到了0day漏洞!【大模型应用实践系列三】》
文章来源: https://mp.weixin.qq.com/s?__biz=MjM5NzE1NjA0MQ==&mid=2651206824&idx=1&sn=90071bc1722c0a9124fc1b54edd3ab0b&chksm=bd2cd10e8a5b5818dbcfee3ff4b88e2634eabcee28958d039eb864449de218e602bd524fac8a&scene=58&subscene=0#rd
如有侵权请联系:admin#unsafe.sh