
2024-12-11 00:17:39 Author: hackernoon.com(查看原文) 阅读量:4 收藏
Table of Links
-
Discussion and Broader Impact, Acknowledgements, and References
D. Differences with Glaze Finetuning
H. Existing Style Mimicry Protections
5 Experimental Setup
Protection tools. We evaluate three protection tools—Mist, Glaze and Anti-DreamBooth—against four robust mimicry methods—Gaussian noising, DiffPure, Noisy Upscaling and IMPRESS++—and a baseline mimicry method. We refer to a combination of a protection tool and a mimicry method as a scenario. We thus analyze fifteen possible scenarios. Appendix J describes our experimental setup for style mimicry and protections in detail.

Artists. We evaluate each style mimicry scenario on images from 10 different artists, which we selected to maximize style diversity. To address limitations in prior evaluations (Shan et al., 2023b), we use five historical artists as well as five contemporary artists who are unlikely to be highly represented in the generative model’s training set (two of these were also used in Glaze’s evaluation).[2] All details about artist selection are included in Appendix J.
Implementation. Our mimicry methods finetune Stable Diffusion 2.1 (Rombach et al., 2022), the best open-source model available at the time when the protections we study were introduced. We use an off-the-shelf finetuning script from HuggingFace (see Appendix J.1 for details). We first validate that our style mimicry pipeline is successful on unprotected art using a user study, detailed in Appendix K.1. For protections, we use the original codebases to reproduce Mist and Anti-Dreambooth. Since Glaze does not have a public codebase (and the authors were unable to share one), we use the released Windows application binary (version 1.1.1) as a black-box. We set each scheme’s hyperparameters to maximize protections. See Appendix J.2 for details on the configuration for each protection.
We perform robust mimicry by finetuning on 18 different images per artist. We then generate images for 10 different prompts. These prompts are designed to cover diverse motifs that the base model, Stable Diffusion 2.1, can successfully generate. See Appendix K for details about prompt design.
User study. To measure the success of each style mimicry scenario, we rely only on human evaluations since previous work found automated metrics (e.g., using CLIP (Radford et al., 2021)) to be unreliable (Shan et al., 2023a,b). Moreover, style protections not only prevent style transfer, but also reduce the overall quality of the generated images (see Figure 3 for examples). We thus design a user study to evaluate image quality and style transfer as independent attributes of the generations.[3]
Our user study asks annotators on Amazon Mechanical Turk (MTurk) to compare image pairs, where one image is generated by a robust mimicry method, and the other from a baseline state-of-the-art mimicry method that uses unprotected art of the artist. A perfectly robust mimicry method would generate images of quality and style indistinguishable from those generated directly from unprotected art. We perform two separate studies: one assessing image quality (e.g., which image looks “better”) and another evaluating stylistic transfer (i.e., which image captures the artist’s original style better, disregarding potential quality artifacts). Our results show that these two metrics obtain very similar results across all scenarios. Appendix K describes our user study and interface in detail.
As noted by the authors of Glaze (Shan et al., 2023a), the users of platforms like MTurk might not have high artistic expertise. However, we believe that the judgment of non-artists is also relevant as they ultimately represent a large fraction of the consumers of digital art. Thus, if lay people consider mimicry attempts to be successful, mimicked art could hurt an artist’s business. Also, to mitigate potential issues with the quality of annotations (Kennedy et al., 2020), we put in place several control mechanisms to filter out low-quality annotations to the best of our abilities (details in Appendix K).
Evaluation metric. We define the success rate of a robust mimicry method as the percentage of annotators (5 per comparison) who prefer outputs from the robust mimicry method over those from a baseline method finetuned on unprotected art (when judging either style match or overall image quality). Formally, we define the success rate for an artist in a specific scenario as:
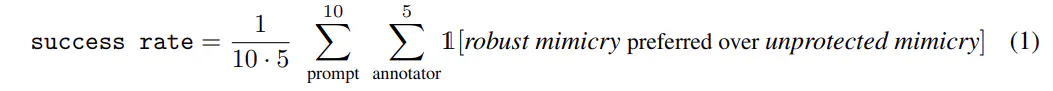
A perfectly robust mimicry method would thus obtain a success rate of 50%, indicating that its outputs are indistinguishable in quality and style from those from the baseline, unprotected method. In contrast, a very successful protection would result in success rates of around 0% for robust mimicry methods, indicating that mimicry on top of protected images always yields worse outputs.
[2] Contemporary Artists were selected from Artstation. We keep them anonymous throughout this work—and refrain from showcasing their art—except for artists who gave us explicit permission to share their identity and art. We will share all images used in our experiments upon request with researchers.
[3] The user study was approved by our institution’s IRB.
如有侵权请联系:admin#unsafe.sh