
背景
当使用数据流分析来指导fuzzer探索更深的路径或者用来发现漏洞时,已经被证明是一种非常有效的方式,在该文中着眼于动态污点分析,传统的污点分析,通常实现起来有存在后面几种缺陷:(1 工作量是比较大的,(2 不精确 ,(3 速度慢,(4 对fuzzing的影响是非常低效的
在该文章中,提出了一种名叫 GreyOne的基于数据流敏感的fuzzing解决方法,通过引入了一个新的轻量级且sound的以fuzzing为驱动的污点推理过程(FTI),通过不断地mutating输入,并且监视变量值的变化来推断变量是否被污染。以这种方式为基础,建立了一个针对如何mutating某个输入seed优先级的模型,来决定探索哪条分支和mutate输入seed的哪个一个字节。 更进一步,描述每个独立的输入seed的约束符合性,用来优化fuzzing的进化方向。
前人工作的方法和不足
基于变异的fuzzing策略,被广泛应用,其中最核心的工作是如何决定fuzzer的进化方向,确切地说是针对一个特定的输入seed,该如何mutate它,使它能执行到更深的路径和满足特定的数据流约束来触发漏洞。
一个比较普遍的解决方案是通过符号执行,但是符号执行通常实现起来是一个非常重的框架,并不适用于稍微大一点应用,对于比较符号的约束条件也是很难求解的,比如单向函数,还有一些其他方案,比如使用深度学习和强化学习来增强fuzzer的效果,但是它们都刚处于起步状态,并没有很明显的优化效果。
数据流分析已经在实践中得到了证明,对fuzzer是有效果的,比如TaintScope用来定位checksum的位置,VUzzer用来定位出现在路径条件上的值,Angora用路径条件来刻画输入模型,这些方案都使用了污点分析来解决如何去mutating 一个输入seed,并且都有不错的效果。
但是传统动态污点分析有很多限制,前面也已经提到过了,比如VUzzer只支持x86平台,因为传统的污点分析需要对每一个独立的指令,编写一个传递规则,对于外部函数和系统调用,还需要建立对应的模型,实际并不精确,因为被污染的值,可能会影响路径条件,进一步影响其他的变量,这种情况就是通常说的隐式数据流,如果隐式的数据流被忽略,将会导致under taint的问题,相反如果完全考虑这样的情况,也将会导致over taint。最后整个分析过程将极其地慢。
挑战和解决思路
通过研究上述的多种限制,提出3个问题,该论文也是围绕着三个问题进一步展开。
- 如何通过轻量级且精确的污点分析来引导高效的fuzzing?
- 如何通过污点分析来有效地指导mutation过程?
- 如何通过数据流的特性来优化fuzzer的进化方向?
GreyOne的流程图
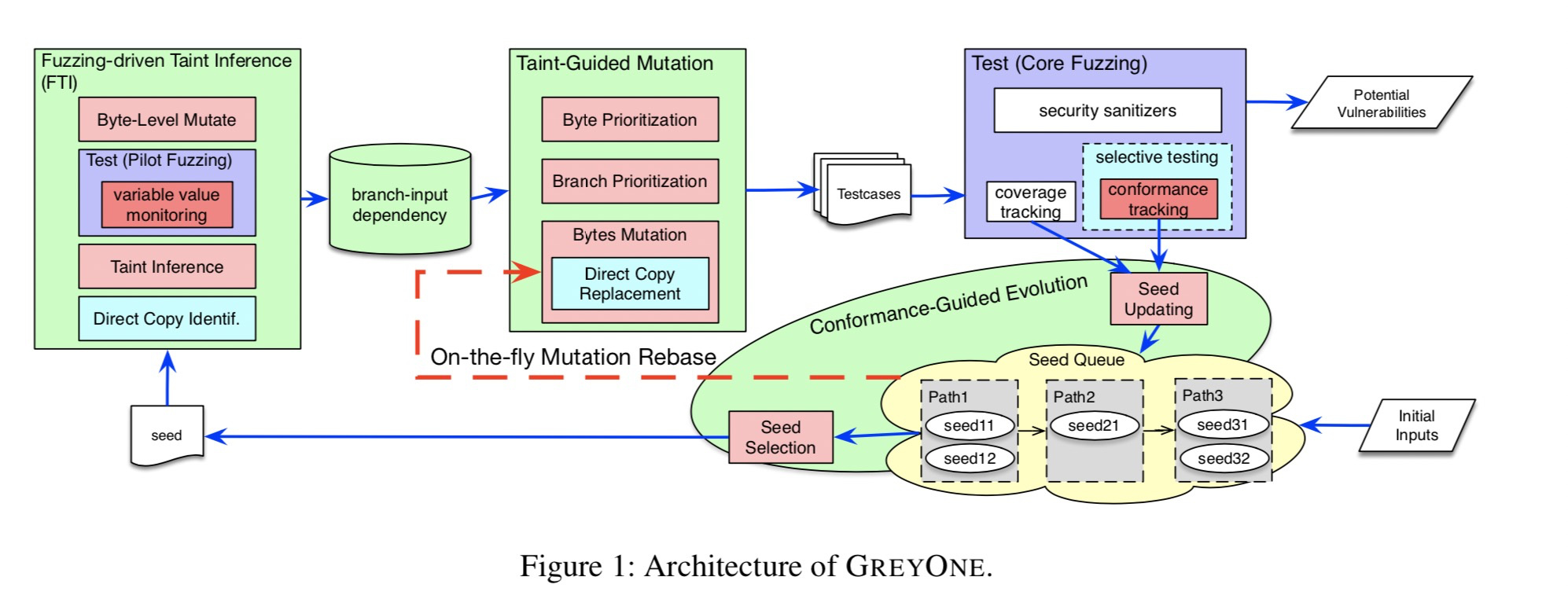
- 种子的生成和更新
- 种子的选择
- 种子的变异
- 测试和追踪
解决方案主要围绕下面三个改进展开:
Fuzzing-driven Taint Inference (FTI)
0x01 Overview
-
首先是个什么东西:通过fuzzing来监测变量值的变化,从而推理哪些变量是否可能被污染。(这是动态执行赋予的特性,羡慕
-
这个推理过程是sound,但是不存在over taint的问题,同时对隐式污点传递过程和调用外部函数带来的干扰有一定的免疫能力。
-
最大的优点就是避免人为编写污点传播规则,且运行时非常快。
0x02 从直觉出发
-
如果当我们改变了输入payload的某一字节,让某个变量的值发生了变化,我们可以推断整个流程依赖于这个字节,无论是显式地传播过程还是是隐式地传播过程(我们是可以忽略的。
- 更进一步说明,如果改变这个字节的值,可能满足或者不满足用到这个变量的条件分支中的条件,从而进入新的分支。
0x03 形式化的表示 (推理规则
- 假设有一个程序变量 var (具体某个指令处) 和 一个输入值 S ,用 S[i] 来表示改变了 S 的第 i 个字节的值,用 v(var,S) 来表示当输入为 S 时,变量 var 的值。所以定义下面的规则用来表示,变量 var 依赖于输入 S 的第 i 个字节。
v(var,S) \neq v(var,S[i])
同理,如果一个条件分支指令$br$的操作数变量依赖于输入 S 的第 i 个字节,我们就说这个分支 br 依赖于输入 S 的第 i 个字节,
0x04 与指令级别的taint analysis的区别
-
它追踪变量的值,是处于一个更高的层次。
-
手动工作少,指令级别的taint analysis需要手动的给每个指令编写传播规则,(平台无关
-
从速度上,FTI更快,(1 他依赖于静态的代码插桩而不是动态二进制插桩 (2 它只监控路径条件种的变量,而不是所有程序的变量。 (3 它不需要给每个独立的指令制定规则
-
从准确性上,FTI比传统的更准,整个的推导规则是sound,如果一个变量被指定为依赖某个输入的字节,很大程度上确实是这样。 从另一个方面来说,它不会出现over taint的错误,但是是可能造成under taint,通常情况是因为隐式的数据流传播,外部函数和系统调用。
-
将它和profuzz的比较起来了,profuzz也是一个一个字节的mutating(用于使数据结构化,但是只关注覆盖率,而不是变量的值。Mutaflow它只监控sink点参数中变量的变化,并不能提供关于其他变量的污染情况,其更关注APIs。
0x05 Taint inference具体细节
-
基于一字节的变异
- 为什么用每次只变异一个字节
- 多字节无法确定究竟是哪个字节影响了变量的值
- 一字节变异产生比较少的testcase 和性能开销。
- 为什么用每次只变异一个字节
-
变量监控
- 只监控出现在路径条件里的变量
- 监控少量的变量性能更快
- 这些变量会影响路径的探索,通过监控来达到探索尽可能多的路径。
- 只监控出现在路径条件里的变量
-
污点推导
- 经过 BLM(S,pos) ,如果变量 var 的值变了,我们就推断 var 被污染了,且依赖于输入 S 的第 pos 个字节
-
关于整个taint inference的算法

0x06 识别可以直接复制的输入值
- 含义是:一些字节上的值,如果导致了变量值的改变,可以保留这些字节上的实际值,例如魔数,checksum,lengt-check,这些精确的值是可以直接替换的。通过识别它们,可以有效解决路径探索上的一些问题。
Taint-Guided Mutation
-
通过taint analysis 指导输入的变异过程
-
输入决定了覆盖率
-
优先选择能覆盖更多未触发的分支输入进行变异
-
如何刻画对每个字节进行变异的优先级?(字节的优先级
- 触发了更多untouched branch
- 触发了更多复杂的程序行为,直到触发了新的branch
-
对种子输入$S$的每一个字节,设定变异的优先级,下面是每个字节权重计算的公式:
W_{byte}(S, pos)=\sum_{br \in Path(S)}\ IsUntouched (br) * \operatorname {DepOn}(br, pos)
因为某一个位置的字节,可能会影响多个路径条件。
-
-
那么如何优先选择怎样的未曾触发的分支,进行变异呢?依赖于前面优先选择输入的过程? (branch的优先级
-
如果一个未触发的分支,依赖于输入$S$对应字节的权重之和越大,那么这个分支越越值得优先满足,即有下面的分支权重计算规则。
W_{br}(S, br)=\sum_{pos \in S}\ DepOn(br, pos) * W_{byte}(S, pos)
-
-
当探索一个分支时,通过已经制定好的优先级,对输入进行变异,包括精确的直接替换期望的输入?(在哪里变异 或 怎样变异?
-
哪里变异?
-
给定一个seed 等价于 给定了一条程序路径,根据前面的分支权重计算的结果递减排序,去探索这条程序路径上周围的未触发的分支路径。
-
当发现了一条新的分支路径,我们直接独立的变异其依赖的每一个字节,字节变异优先级按前面字节权重计算的结果递减排序。
-
-
怎么变异输入的直接拷贝?
- 核心问题是“如何获取精确的值?”,这个过程处于FTI,如果是常量,我们直接记录这个常量值,如果是类似checksum,需要运行时计算的值,首先构造一个畸形输入,获取运行时的对应值,然后用这个值进行一些细微的修改来满足需求。(这个过程感觉好隐晦
-
怎么变异输入的间接拷贝?
- 如果一些输入字节会影响某些为触发的分支路径,但是并不会直接在路径条件中使用它们的值,我们将会一个一个地变异这些字节(按照字节权重计算结果),不同于FTI中的byte-level,这里是可以多字节同时独立变异的。
-
如何缓解under taint的过程?
- 由于FTI得到需要变异字节并不是完整的,所以对于那些没有涉及到的字节也需要考虑变异,所以会以比较小的概率变异FTI得到字节的相邻字节。
-
Conformance-Guided Evolution(基于适应性指导的进化策略
-
为什么要做它:大多数fuzzer都是通过控制流的特性(即输入能触发路径),比如覆盖率,都指导整个进化策略。
-
它到底描述的是一个什么东西:tainted variable的值和在路径条件中这个variable期望的值的“距离”
-
适应性的计算
-
未触发的分支的适应性
对于给定未触发的分支$br$,依赖于两个操作数变量$var1$和$var2$,定义其适应性约束如下。
C_{b r}(b r, S)=NumEqualBits({var} 1, {var} 2)
其中$NumEqualBits$返回值为两个参数之间相等的字节数量,类似于switch 语句中条件和case 的值相互依赖。
-
基本块的适应性
对于给定的输入$S$和已经发现的基本块$bb$,$bb$的适应性约束为其相邻的未触发的分支适应性约束的最大值。(有点绕
C_{BB}(bb, S)= MAX_{br \in E d g e s(b b)} IsUntouched (b r) * C_{b r}(b r, S)
-
测试用例的适应性
对于一个给定测试用例$S$,它的适应性约束定义为其路径上所有的$bb$适应性约束之和。
C_{\text {seed}}(S)=\sum_{b b \in \operatorname{Path}(S)} C_{B B}(b b, S)
从定义的结构上来看,如果一个seed具有比较大的适应性约束,可能有比较多的未触发的分支,且每个独立的分支具有比较高的适应性约束,其更有可能触发更多的路径。
-
-
基于适应性指导的种子更新
-
传统的种子队列,用链表来表示,一个结点就是一个种子,通过扩展每个结点保护多个种子,这些种子是具体相同的执行路径和相同的适应性,但是具有不同的块适应性。
-
关于种子的更新策略,有下面三种。
-
如果产生了新的执行路径,将创建一个新的结点,用存储这个种子
-
如果种子发现已经存在的路径,但是具有更高的适应性,清空这个结点,并把这个种子加入到这个结点
-
相同的执行路径和相同的适应性,但是具有不同的基本块适应性,直接将其加入到对应的结点
-
-
关于应用方面
- 静态分析和插桩
- 覆盖率的计算
- 适应性的计算
- 变量值监控
Evaluation
-
基础fuzzer的比较
-
目标应用的测试
-
性能指标
-
种子的初始化 (这是greyone的一个痛点,无法自生成seed
-
随机性的缓解
-
实现环境
漏洞发现
-
独立的crash cases比较

-
路径覆盖和边界覆盖的比较
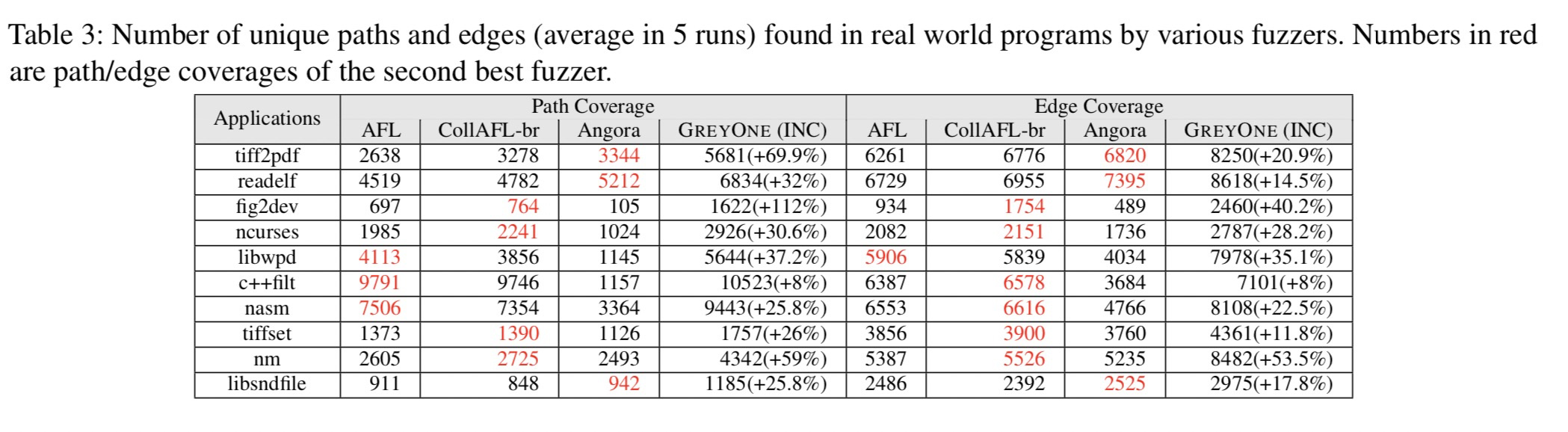
总共发现了105个漏洞,其中25个是已知的,在其余的80个漏洞中,其中有41个被确定为CVE。
深度分析
- FTI的性能的分析
- 完整性:通过和DFSan的DTA(dynamic taint analysis)引擎比较
- 性能消耗
相关的研究
-
污点推理
-
对传统污点分析的改进
Dytan 通过跟踪间接污点传播过程来缓解under taint的问题,DTA++ 通过定位隐式数据流传播分支,使用离线式的符号执行来推理污点传播过程,TAINTINCLUDE通过基于测试的方法来自动生成污点传播分析规则,但是这个框架还是太重了。
-
基于变异的推理过程
Sekar采用黑盒测试的方法,利用预先定义的mutate规则来推断污点传播过程,能监测注入类型的漏洞,mutaflow前面提到了,它关注APIs,即source。REDQUEEN通过随机变异策略给输入着色,用以推断污点情况!!!!!Fairfuzz和ProFuzzer都只是通过监控CFG的变化。
-
-
种子变异
- 基于静态分析的优化
- 基于学习模型
- 基于符号执行
- 基于污点分析
-
种子的选择和更新