2024-12-6 02:31:16 Author: securityboulevard.com(查看原文) 阅读量:2 收藏

|
Mathias Millet |

Let's face it: tasks and celery aren't exactly a match made in heaven. One's a boring to-do list, and the other's that sad, stringy vegetable sitting in your fridge drawer, probably plotting its revenge against your next salad.
But in our beloved programmatic world, these unlikely partners team up to handle some of our most critical background jobs. And just like its vegetable namesake, when a Celery task goes bad, it can leave a pretty unpleasant taste in your mouth.
If you’ve ever dealt with the frustration of a task going poof mid-execution, you’re not alone.
At GitGuardian, we depend on Celery to do some pretty heavy lifting—like scanning GitHub pull requests for secrets. When those tasks fail, it’s not just an “oops moment.” A stuck PR can grind our users’ workflows to a halt, which is about as fun as debugging a failing build five minutes before your weekend starts.
In this post, we’ll dive into how we’ve made our Celery tasks more resilient with retries, idempotency, and a sprinkle of best practices. Whether you’re here to prevent workflow catastrophes or just make your Celery game a little stronger, you’re in the right place.
Quick Refresher: Task Failures in Celery
When Celery tasks fail in production, they typically fall into three categories:
- Transient failures: Temporary hiccups like network issues or service outages that resolve with a retry. This typically corresponds to GitHub API timeouts, which we'll see handled with
autoretry_for - Resource limits: When tasks exhaust system resources, particularly memory, covered in our OOM Killer section
- Race conditions ocurring when updating a PR status, which underlines the absolute necessity of making sure tasks are really idempotent in the first place.
Not to forget that failures can also happen because of buggy code: in that case, we should not retry the task, since retrying a buggy operation will typically fail again with the same error, creating an infinite loop.
The bottom line is that blindly retrying every failed task isn't the answer—you need targeted solutions for each type of failure. This is crucial to implement robust background jobs
The following sections will show you how we handle each of these, providing practical patterns you can apply to your own Celery tasks.
Understanding GitHub Checks: A Core GitGuardian Feature
Running GitHub checks is an essential part of the GitGuardian Platform. These checks allow us to integrate into GitHub’s PR workflow and block PRs that contain secrets.
Using the REST API to interact with checks – GitHub Docs
You can use the REST API to build GitHub Apps that run powerful checks against code changes in a repository. You can create apps that perform continuous integration, code linting, or code scanning services and provide detailed feedback on commits.
![]() GitHub Docs
GitHub Docs
![]()
Under the hood of our platform, checks run as celery tasks, which we call, without much afterthought, github_check_task:
@celery_app.task()
def github_check_task(github_event):
problems = secret_scan(github_event)
update_checkrun_status(github_event, problems)With external APIs, network calls, and memory-hungry scans, plenty can go sideways. A failed (or slow) check means blocked PRs, angry developers, and support tickets ruining someone's afternoon.
So, how do we turn this simple task into a resilient workhorse that keeps our GitHub checks running smoothly? Let's dive in.
Building Resilient Tasks
1. Making Tasks Idempotent
Our check_run_task is very important and needs to be retried in case of failure due to external reasons.
First, we need to ensure the task is idempotent – meaning multiple executions with the same input won't change your application's state beyond the first run. This makes it safe to retry the task as many times as needed (for more details, see this StackOverflow explanation: What is an idempotent operation?).
💡
Of course, there are some edge cases. For instance, with email-sending tasks, you might accept occasional duplicate emails but you should still implement a maximum retry limit to prevent excessive repetition.
2. Handling Expected Failures
Some failures are just part of the game when integrating with external services and dealing with resource-intensive operations. The good news is that many of these can be caught cleanly as Python exceptions, allowing us to handle them gracefully with built-in retry mechanisms.
First obvious case, our task may be aborted because GitHub’s API is down when we try to update the check run’s status. If not handled explicitly, a Python exception will be raised when performing the request, and the task will fail.

In this case, we can rely on celery’s built-in retry mechanism, autoretry_for:
import requests
@celery_app.task(
autoretry_for=[requests.RequestException]
max_retries=5,
retry_backoff=True
)
def github_check_task(github_event):
problems = secret_scan(github_event)
update_checkrun_status(github_event, problems)💡
Best practices:
1. Use retry_backoff when retrying in case of network issues: it will increase the time between each retry so as to not overwhelm the remote services (and participate in keeping them down).
2. Never set max_retry to None (it is three by default). Otherwise, a task could be retried indefinitely, clogging your task queue and workers.
Other failures from the outside world that we can catch as Python exceptions include:
- All issues with a service that may not be responding, either because there are network issues or because the service itself is down or overloaded.
- Database deadlocks
💡
Best practice:
List specific exceptions in autoretry_for, not generic exceptions like Exception, to avoid unnecessary retries. Example below:
import requests
@celery_app.task(
autoretry_for=[requests.RequestException, django.db.IntegrityError],
max_retries=5,
retry_backoff=True
)
def github_check_task(github_event):
problems = secret_scan(github_event)
update_checkrun_status(github_event, problems)You may also manually retry your task, which gives you even more flexibility. More on that in the Bonus section at the end of this post.
3. Dealing with Process Interruptions
So, as we just saw, retrying tasks is pretty straightforward in Celery. Are we done yet? Not at all! There is another kind of event that we need to take into account: the interruption of the Celery process itself. Two main reasons could cause this:
- The OS/computer/container in which the process is running is shut down.
- The OS “kills” the process.

A typical scenario: your Celery worker runs as a pod in a Kubernetes cluster. When deploying a new version of your application, the pod restarts during rollout, potentially leaving incoming tasks unexecuted. Similarly, pod autoscaling events can trigger container restarts, which may cause unexpected task interruptions.
💡
In this case, k8s will first send a SIGTERM signal to the Celery process, then a SIGKILL once the grace period has elapsed (if the pod is still running). Upon receiving the SIGTERM, Celery will stop processing new tasks but will not abort the current task.
To handle these situations, Celery exposes the acks_late parameter, so that the message delivered by your task queue (typically, RabbitMQ or Redis) is only acknowledged after task completion. You can enable this for specific tasks like so:
import requests
@celery_app.task(
retry_on=(requests.ConnectionError,)
max_retries=5,
retry_backoff=True,
acks_late=True
)
def github_check_task(github_event):
problems = secret_scan(github_event)
update_checkrun_status(github_event, problems)If the task or worker is interrupted, any unack'ed message will eventually be re-delivered to the Celery worker, allowing the task to restart.
💡
Best practice: time-bound your tasks
Celery has two complementary options that you can use to time-bound your tasks: time_limit and soft_time_limit . Here is the official documentation, and we'll see an example of soft_time_limit in the Bonus section at the end of this article.
With an adapted GracePeriod in the orchestrator, you can avoid k8s killing your tasks.
⚠️
Warning! If you use Redis, be sure that the tasks for which acks_late is enabled are completed in less time than visibility_timeout.
With Redis as a queue, the visibility_timeout parameter comes into play (see doc), which defaults to one hour. This means that:
1. Aborted tasks will not be retried before one hour has elapsed.
2. If a task takes more than one hour to complete, it will be retried – possibly leading to infinite re-scheduling of the task!
Advanced Failure Scenarios: Beware The OOM Killer!
There are cases when we DO NOT want a task to retry—specifically when retrying could crash our system.
Consider tasks that require more memory than our systems can handle. In these situations, the operating system's Out Of Memory (OOM) Killer kicks in as a protective measure. The OOM Killer terminates processes that threaten system stability by consuming too much memory.
If we allowed automatic retries in these cases, we'd create an infinite loop: the memory-intensive task would launch, get killed by the OOM Killer, retry, and repeat endlessly.
Fortunately, Celery has built-in protection against this scenario. To understand how this works, we need to look under Celery's hood. Let me explain…
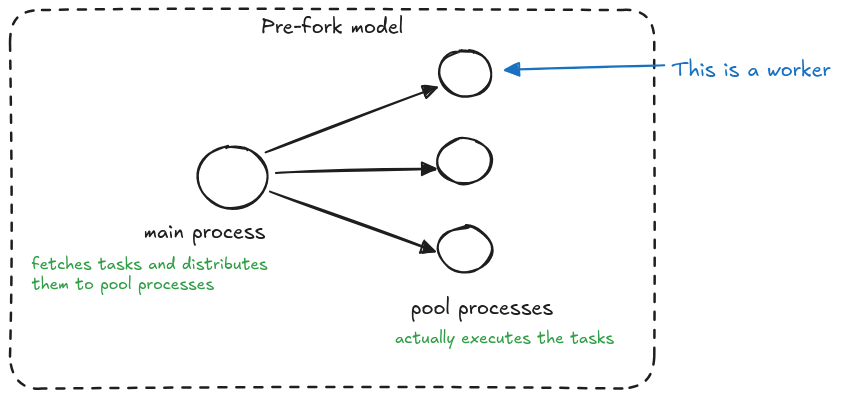
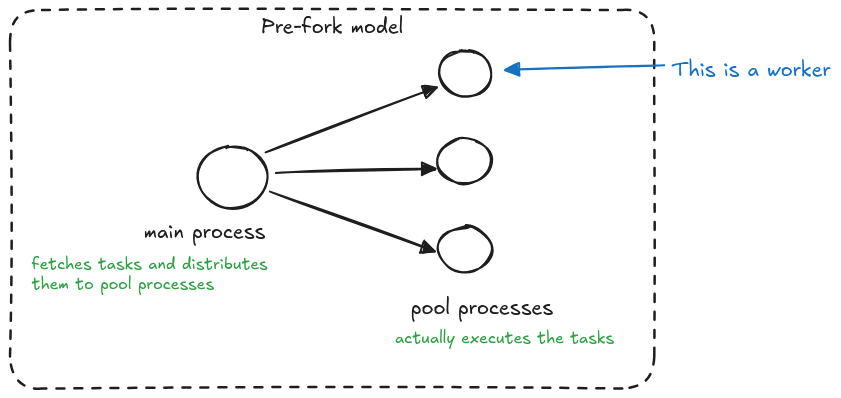
In Celery’s "pre-fork" model, a main process acts as the orchestrator of all operations. This main process is responsible for fetching tasks and smartly distributing them across a pool of worker processes. These worker processes, which are pre-forked from the main process, are the ones that actually execute the tasks.
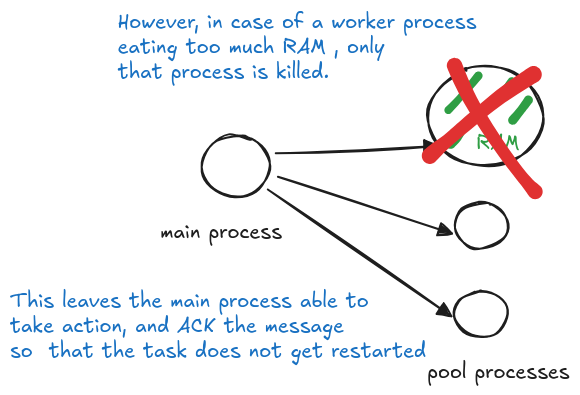
This architecture is crucial for fault tolerance – if a worker process encounters excessive memory usage and gets terminated by the OOM Killer, the main process remains unaffected. This clever separation allows Celery to detect when a pool process was killed during task execution and handle the failure gracefully, preventing infinite retry loops that could occur if the same memory-intensive task were repeatedly attempted.
💡
Best practice: never set task_retry_on_worker_lost to True
Setting the parameter to True opens the door to infinite task retries and possibly instability in the servers executing the tasks.
Important note about Celery execution models: while prefork is common, Celery also supports threads, gevent, and eventlet models. These alternative models run in a single process, which means they handle OOM kills differently.
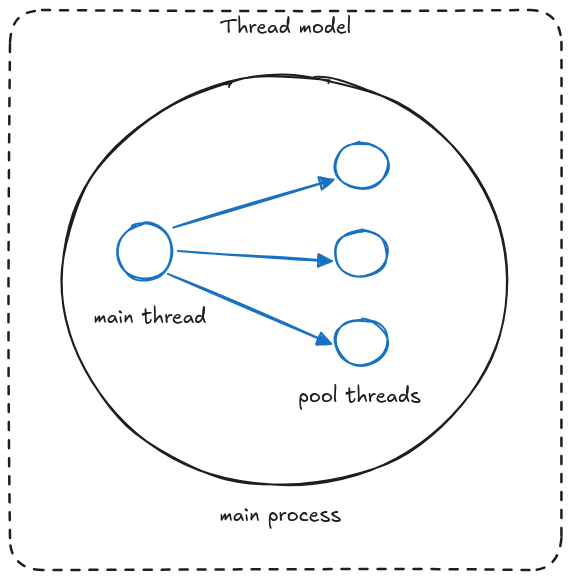
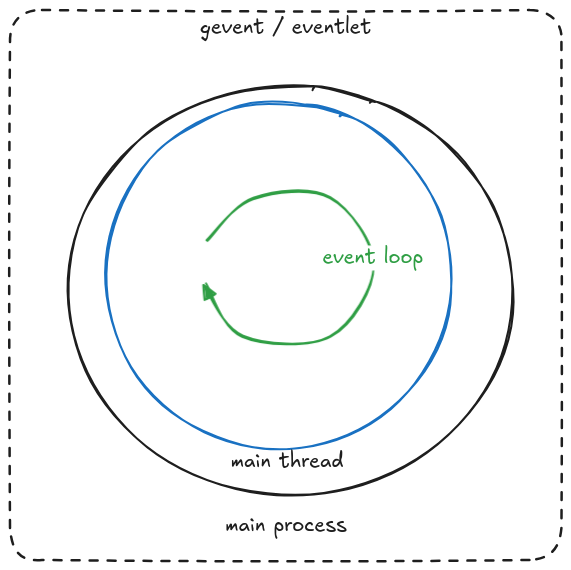
In single-process models, when the OOM killer terminates a task, Celery cannot detect this specific cause. It treats the termination like any other kill event.
This has an important implication: Tasks with acks_late enabled will retry after an OOM kill, potentially creating an infinite retry loop!
⚠️
Warning! If you're using threads, gevent, or eventlet instead of prefork, you won't have built-in protection against infinite retries after OOM kills.
Best Practices Summary
Let's recap the key strategies for building resilient Celery tasks:
- Make Tasks Idempotent
- Ensure multiple executions with the same input won't cause issues (critical for safe retries and consistent state).
- Handle Expected Failures
- Use
autoretry_forwith specific exceptions (not generic ones) - Enable
retry_backofffor network-related retries - Set reasonable
max_retries(never use None) - Example exceptions:
requests.RequestException,django.db.IntegrityError
- Use
- Process Interruption Protection
- Depending on the situation, you may enable
acks_late=Truefor critical tasks (make sure to understand how this works beforehand though!) - Be aware of Redis
visibility_timeoutimplications - Implement appropriate time limits (
time_limit,soft_time_limit)
- Depending on the situation, you may enable
- OOM Protection
- Never set
task_retry_on_worker_lost=True - Use prefork execution model when possible
- Be extra cautious with thread/gevent/eventlet models
- Monitor memory usage and set appropriate limits
- Never set
- Time Boundaries
- Set reasonable task timeouts
- Configure worker grace periods
- Align with infrastructure timeouts (K8s, Redis)
Remember: The goal isn't just to retry tasks, but to build a robust system that handles failures gracefully while maintaining system stability.
Let's be honest—while Celery tasks might not be the most exciting part of our codebase, implementing these resilient patterns turns them from flaky background jobs into rock-solid workhorses that keep our systems running smoothly!
Bonus: Retrying Tasks on a Different Queue
For our check runs, we have implemented a custom handler for tasks that exceed their time limit. Here's how it works:
- Tasks that take too long are re-scheduled on a separate queue
- These rescheduled tasks are processed by more powerful workers with longer timeout limits
This approach provides two key benefits:
- Cost optimization – most tasks can be handled by workers with limited memory
- Load management – prevents main worker pool from being overwhelmed by resource-intensive tasks
Here's how we implement this using Celery's soft_time_limit mechanism:
import requests
from celery.exceptions import SoftTimeLimitExceeded
@celery_app.task(
bind=True,
autoretry_for=[requests.RequestException],
max_retries=5,
retry_backoff=True,
soft_time_limit=30,
)
def github_check_task(task, github_event):
try:
problems = secret_scan(github_event)
update_checkrun_status(github_event, problems)
except SoftTimeLimitExceeded:
task.retry(
queue=RETRY_QUEUE,
soft_time_limit=300
)*** This is a Security Bloggers Network syndicated blog from GitGuardian Blog - Take Control of Your Secrets Security authored by Guardians. Read the original post at: https://blog.gitguardian.com/celery-tasks-retries-errors/
如有侵权请联系:admin#unsafe.sh