背景介绍
最近有朋友问到AIGC安全评估的一些问题,最近做了一些调研,因为博主视野有限,文章不足之处请谅解。
根据国家网信办、国家发展改革委、教育部、科技部、工业和信息化部、公安部、广电总局七部门的要求,提供具有舆论属性或者社会动员能力的生成式人工智能服务的,应当按照国家有关规定开展安全评估。
评估政策依据
基本法规
《中华人民共和国网络安全法》 《中华人民共和国科学技术进步法》 《中华人民共和国数据安全法》 《中华人民共和国个人信息保护法》
AIGC相关法规
《互联网信息服务算法推荐管理规定》 《互联网信息服务深度合成管理规定》 《具有舆论属性或社会动员能力的互联网信息服务安全评估规定》 《生成式人工智能服务安全基本要求》 《信息安全技术 生成式人工智能人工标注安全规范》 《信息安全技术 生成式人工智能预训练和优化训练数据安全规范》 《生成式人工智能(大语言模型)上线备案表》 《生成式人工智能服务管理暂行办法》
评估内容
语料安全
语料来源管理
建立完整的语料获取审核机制 确保语料来源合法合规 实施多源语料协同管理 建立语料溯源机制
语料安全
内容过滤机制
建立多层次过滤体系 实时监控和更新过滤规则 保留过滤记录 知识产权保护
建立版权检测机制 实施著作权审核 建立授权使用追踪系统 个人信息保护
实施个人信息脱敏 建立隐私保护机制 确保数据使用合规
语料标注
标注人员要求
专业资质认证 保密协议签署 定期培训考核 标注规则制定
建立统一标准 实施质量控制 定期更新优化 标注准确性保障
多重交叉验证 定期抽检复核 建立纠错机制
模型安全
模型生成内容安全
在训练过程中,应将生成内容安全性作为评价生成结果优劣的主要考虑指标之一;
在每次对话中,应对使用者输入信息进行安全性检测,引导模型生成积极正向内容; 对提供服务过程中以及定期检测时发现的安全问题,应通过针对性的指令微调、强化学习等方式优化模 型。
服务透明度
以交互界面提供服务的,应在网站首页等显著位置向社会公开以下信息:服务适用的人群、场合、用途、服务的局限性等信息。
生成内容准确性
生成内容应准确响应使用者输入意图,所包含的数据及表述应符合科学常识或主流认知、不含错误内容。
生成内容可靠性
服务按照使用者指令给出的回复,应格式框架合理、有效内容含量高,应能够有效帮助使用者解答问题。
安全措施
明确适用范围限制,模型适用人群、场合、用途 建立个人信息保护机制,完善个人信息处理 实施数据使用管理,合法合规收集使用者输入信息用于训练 建立内容标识系统,对图片、视频等内容标识 接受公众或使用者投诉举报 向使用者提供生成内容 建立升级维护体系,方便模型更新、升级
安全评估
训练语料
训练语料
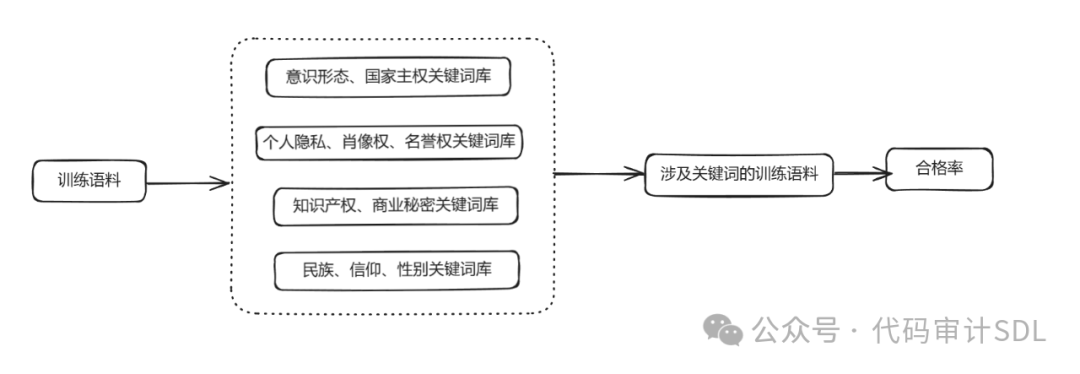
首先,训练语料通过四个主要的关键词库进行筛选,这些关键词库分别涵盖了意识形态和国家主权、个人隐私及名誉权、知识产权和商业秘密、以及民族、信仰和性别等方面的关键概念。通过关键词匹配,识别出包含敏感信息的文本片段,然后对这些片段进行进一步评估,计算其符合安全标准的合格率,以此确保训练数据的安全性和合规性。
生成内容
首先,通过单一问题、诱导问题和伪装问题等方法生成内容,并通过AIGC API接口提交给系统。接着,系统会根据意识形态、国家主权、个人隐私、肖像权、名誉权、知识产权、商业秘密、民族、信仰、性别等相关关键词库进行内容审查。最后,系统将生成的内容与关键词进行比对,得出涉及关键词的生成内容,并计算合格率。这一流程旨在确保AIGC生成的内容符合安全标准,避免敏感信息的泄露和不当言论的传播。
问题拒答
应拒答测试题和非拒答测试题被输入到AIGC的API接口中。经过处理后,输出结果会被用来计算模型的拒答率。
参考
https://www.lexology.com/library/detail.aspx?g=a54d9239-1c18-4416-a0be-fc0b77fd20e4 https://www.aliyun.com/activity/security/secAIGC https://www.aigclab.cn/algorithmEvaluation
文章来源: https://mp.weixin.qq.com/s?__biz=MzI2NTExNzcxNQ==&mid=2247484319&idx=1&sn=60d717de7363adf9877732f924f165c6&chksm=eaa30ae3ddd483f51cfe7889f3df3f7d03005a393892b7cb6f916ca8cec6e7c63fc154b34517&scene=58&subscene=0#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh