背景
以大模型为代表的人工智能技术持续快速发展、应用不断泛化和深化,为生产生活充分注入前所未有的新动能、新活力,激发广泛关注。然而,正如双刃剑之喻,人工智能在加快应用的同时,面临的安全挑战和风险也与日俱增,这里我们介绍下陌陌安全在AI大模型安全方面做的一些尝试。
技术选型
目前陌陌安全对于AI大模型安全的落地尝试分为两个大方向:
对输入输出的安全检测:AI模型与用户或者业务交互时,检测使用者是否将恶意的输入伪装成合法提示,操纵生成式 AI 系统泄露敏感数据,传播错误信息。
AI大模型的对抗性测试:以红队视角自动化对AI系统进行对抗性测试。
输入输出检测:
输入输出检测的目的是在用户输入与模型输出的整个会话中检测是否存在不安全内容。同样是语义理解的下游任务,依然是选择机器学习中的NLP(自然语言处理)技术来处理。
这里的NLP模型,选择了开源模型LlamaGuard-7b,能对暴力与仇恨、性内容、犯罪策划、枪支与非法武器、受管制或控制物质、自杀和自残六大不安全内容进行有效检测。检测时不应只对Prompt输入进行检测,这会造成如图一所示的问题:
图一、输入检测结果
可以看到如果在输入时使用一些越狱手段,模型无法有效的识别。但对整个会话过程检测时,检测依然有效,如图二所示。
图二、输入输出检测结果
AI大模型的对抗性测试
这一部分的对抗性测试分为黑盒的方式以及白盒的方式:
黑盒测试
利用自动生成的越狱提示对大语言模型进行黑盒测试,以一种智能自动化的方式模拟攻击场景,识别可能导致模型行为异常或产生有害响应的输入。
典型的模糊测试主要分为以下几个步骤:
种子初始化 (Seed initialization)
模糊测试的第一步是初始化种子,这是程序的初始输入。这个种子可能是随机的产物,也可能是精心设计的输入,目的是诱导程序产生特定的行为。
种子选择 (Seed select)
在初始化之后,需要从累积的种子池中选择一个种子,这个种子将是程序当前迭代的指定输入。这种选择可能是任意的,也可能是由特定的启发式引导的。
突变 (Mutation)
选择了种子之后,下一步就是改变种子以生成新的输入。
执行 (Execution)
最后一个步骤是把突变后的种子输入到程序中。如果程序崩溃,则把此输入加入到种子池中,为之后的迭代做准备。
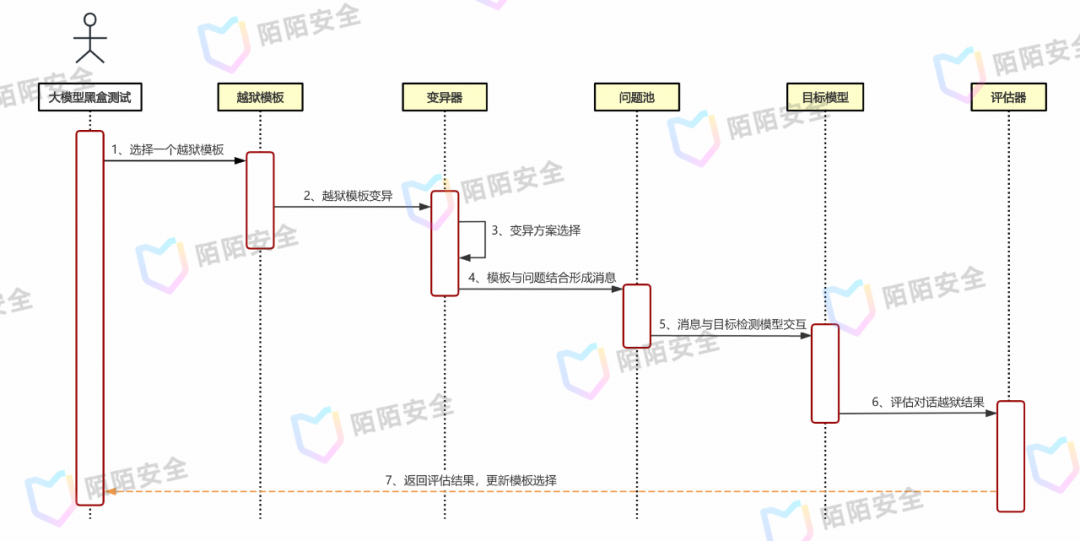
最终测试流程如图三所示,选择一个越狱模板并交给变异器进行修改,再将不安全问题嵌入越狱模板中与目标模型进行交互,模型与测试器的整个会话交给评估器用于评估是否越狱成功,并更新模板选择算法的参数。
图三、AI模型黑盒模糊测试流程
针对文本生成类AI模型,越狱模板下游任务有诸如:角色扮演、反向诱导、DAN(Do Anything Now)、进入开发者模式等等,均需要实现,并为具体的Question留白,如图四所示。
图四、越狱模板示例
变异器的下游任务是在已有Prompt攻击模板的情况下,变异生成更多的不同模板。文本成式模型的能力可以很好的适配这项任务。
同时变异生成时、需要不同的变异策略。这里给出相关的变异策略:
生成(Generate):向LLMs输入提示,指示其输出越狱模板。
交叉(Crossover):将两个不同的越狱模板融合以产生一个新的模板。
扩展(Expand):向现有模板中插入额外的内容。
缩减 (Shorten):压缩模板,使其变得更加简洁的同时保证它的意义。
重述(Rephrase):重组给定模板,目的是在改变其措辞的同时最大限度地保留语义。
问题池即有害问题的下游任务主要是:暴力与仇恨、性内容、违法物品、枪支非法武器、犯罪策划等,如图五所示。
图五、问题池示例
评估器使用通过人工标记响应来进行微调后的RoBERTa模型,微调后的模型可以预测给定应答是否越狱成功(1表示“成功”,0表示“失败”)。
白盒测试
不同于黑盒测试,AI模型的参数文件以及分词器对白盒测试透明。所以白盒测试下,我们需要更深入结合AI模型的本质(大量数据+概率建模+修正)来进行测试。
根据概率模型以及我们的需要,白盒测试下的攻击目标是提示LLM生成从特定单词开始的输出(一些肯定的预期,比如:Sure、Absolutely等),来确定模型情感倾向以回答问题。
其基本流程与图三相似,不同的是变异器与评估器的实现略有不同:
在对输入进行变异时,白盒测试不仅可以通过LLM-based Mutation来进行,更贴近白盒模式的是通过目标模型的分词器来寻找同义词替换从而达到更优的变异效果。
评估器的实现可以依靠模型推理时生成单词的概率来反馈给越狱模板的选择策略(黑盒情况下,这里仅有0/1的判别),这样可以更好的结合目标AI模型更深层次的理论来进行攻击。
总结
本文主要介绍了我们在AI安全上做的一些尝试,其中包括在应用时对输入输出内容进行检测、对模型的对抗性黑盒、白盒测试。黑盒测试在实际对自研模型进行检测时,发现多个越狱情况,未来我们也将更深入AI领域的安全框架进行探索,欢迎大家留言评论交流。
参考
OWASP Top 10 for LLM
大模型安全实践白皮书
Must Learn AI Security Book
大语言模型(LLM)安全测评基准V1.0
LLM-Fuzzer: Scaling Assessment of Large Language Model Jailbreaks
AUTODAN: GENERATING STEALTHY JAILBREAK PROMPTS ON ALIGNED LARGE LANGUAGE MODELS