This post is the first in a new series covering some of the reasoning behind decisions made in 2024-11-21 16:58:19 Author: soatok.blog(查看原文) 阅读量:41 收藏
This post is the first in a new series covering some of the reasoning behind decisions made in my project to build end-to-end encryption for direct messages on the Fediverse.
(Collectively, Fedi-E2EE.)
Although the reasons for specific design decisions should be immediately obvious from reading the relevant specification (and if not, I consider that a bug in the specification), I believe writing about it less formally will improve the clarity behind the specific design decisions taken.
In the inaugural post for this series, I’d like to focus on how the Fedi-E2EE Public Key Directory specification aims to provide Key Transparency and an Authority-free PKI for the Fediverse without making GDPR compliance logically impossible.
Background
Key Transparency
For a clearer background, I recommend reading my blog post announcing the focused effort on a Public Key Directory, and then my update from August 2024.
If you’re in a hurry, I’ll be brief:
The goal of Key Transparency is to ensure everyone in a network sees the same view of who has which public key.
How it accomplishes this is a little complicated: It involves Merkle trees, digital signatures, and a higher-level protocol of distinct actions that affect the state machine.
If you’re thinking “blockchain”, you’re in the right ballpark, but we aren’t propping up a cryptocurrency. Instead, we’re using a centralized publisher model (per Public Key Directory instance) with decentralized verification.
Add a bit of cross-signing and replication, and you can stitch together a robust network of Public Key Directories that can be queried to obtain the currently-trusted list of public keys (or other auxiliary data) for a given Fediverse user. This can then be used to build application-layer protocols (i.e., end-to-end encryption with an identity key more robust than “trust on first use” due to the built-in audit trail to Merkle trees).
I’m handwaving a lot of details here. The Architecture and Specification documents are both worth a read if you’re curious to learn more.
Right To Be Forgotten
I am not a lawyer, nor do I play one on TV. This is not legal advice. Other standard disclaimers go here.
Okay, now that we’ve got that out of the way, Article 17 of the GDPR establishes a “Right to erasure” for Personally Identifiable Information (PII).
What this actually means in practice has not been consistently decided by the courts yet. However, a publicly readable, immutable ledger that maps public keys (which may be considered PII) with Actor IDs (which includes usernames, which are definitely PII) goes against the grain when it comes to GDPR.
It remains an open question of there is public interest in this data persisting in a read-only ledger ad infinitum, which could override the right to be forgotten. If there is, that’s for the courts to decide, not furry tech bloggers.
I know it can be tempting, especially as an American with no presence in the European Union, to shrug and say, “That seems like a them problem.” However, if other folks want to be able to use my designs within the EU, I would be remiss to at least consider this potential pitfall and try to mitigate it in my designs.
So that’s is what I did.
Almost Contradictory
At first glance, the privacy goals of both Key Transparency and the GDPR’s Right To Erasure are at odds.
- One creates an immutable, append-only history.
- The other establishes a right for EU citizens’ history to be selectively censored, which means history has to be mutable.
However, they’re not totally impossible to reconcile.
An untested legal theory circulating around large American tech companies is that “crypto shredding” is legally equivalent to erasure.
Crypto shredding is the act of storing encrypted data, and then when given a legal takedown request from an EU citizen, deleting the key instead of the data.
This works from a purely technical perspective: If the data is encrypted, and you don’t know the key, to you it’s indistinguishable from someone who encrypted the same number of NUL bytes. In fact, many security proofs for encryption schemes are satisfied by reaching this conclusion, so this isn’t a crazy notion.
Is Crypto Shredding Plausible?
In 2019, the European Parliamentary Research Service published a lengthy report titled Blockchain and the General Data Protection Regulation which states the following:
Before any examination of whether blockchain technology is capable of complying with Article 17 GDPR; it must be underscored that the precise meaning of the term ‘erasure’ remains unclear.
Article 17 GDPR does not define erasure, and the Regulation’s recitals are equally mum on how this term should be understood. It might be assumed that a common-sense understanding of this terminology ought to be embraced. According to the Oxford English Dictionary, erasure means ‘the removal or writing, recorded material, or data’ or ‘the removal of all traces of something: obliteration’.494
From this perspective, erasure could be taken to equal destruction. It has, however, already been stressed that the destruction of data on blockchains, particularly these of a public and permissionless nature, is far from straightforward.
There are, however, indications that the obligation inherent to Article 17 GDPR does not have to be interpreted as requiring the outright destruction of data. In Google Spain, the delisting of information from research results was considered to amount to erasure. It is important to note, however, that in this case, this is all that was requested of Google by the claimant, who did not have control over the original data source (an online newspaper publication). Had the claimant wished to obtain the outright destruction of the relevant data it would have had to address the newspaper, not Google. This may be taken as an indication that what the GDPR requires is that the obligation resting on data controllers is to do all they can to secure a result as close as possible to the destruction of their data within the limits of [their] own factual possibilities.
Dr Michèle Finck, Blockchain and the General Data Protection Regulation, pp. 75-76
From this, we can kind of intuit that the courts aren’t pedantic: The cited Google Spain case was satisfied by merely delisting the content, not the erasure of the newspaper’s archives.
The report goes on to say:
As awareness regarding the tricky reconciliation between Article 17 GDPR and distributed ledgers grows, a number of technical alternatives to the outright destruction of data have been considered by various actors. An often-mentioned solution is that of the destruction of the private key, which would have the effect of making data encrypted with a public key inaccessible. This is indeed the solution that has been put forward by the French data protection authority CNIL in its guidance on blockchains and the GDPR. The CNIL has suggested that erasure could be obtained where the keyed hash function’s secret key is deleted together with information from other systems where it was stored for processing.
Dr Michèle Finck, Blockchain and the General Data Protection Regulation, pp. 76-77
That said, I cannot locate a specific court decision that affirms that crypto erasure is legally sufficient for complying with data erasure requests (nor any that affirm that it’s necessary).
I don’t have a crystal ball that can read the future on what government compliance will decide, nor am I an expert in legal matters.
Given the absence of a clear legal framework, I do think it’s totally reasonable to consider crypto-shredding equivalent to data erasure. Most experts would probably agree with this. But it’s also possible that the courts could rule totally stupidly on this one day.
Therefore, I must caution anyone that follows a similar path: Do not claim GDPR compliance just because you implement crypto-shredding in a distributed ledger. All you can realistically promise is that you’re not going out of your way to make compliance logically impossible. All we have to go by are untested legal hypotheses, and very little clarity (even if the technologists are near-unanimous on the topic!).
Towards A Solution
With all that in mind, let’s start with “crypto shredding” as the answer to the GDPR + transparency log conundrum.
This is only the start of our complications.
Protocol Risks Introduced by Crypto Shredding
Before the introduction of crypto shredding, the job of the Public Key Directory was simple:
- Receive a protocol message.
- Validate the protocol message.
- Commit the protocol message to a transparency log (in this case, Sigsum).
- Retrieve the protocol message whenever someone requests it to independently verify its inclusion.
- Miscellaneous other protocol things (cross-directory checkpoint commitment, replication, etc.).
Point being: there was very little that the directory could do to be dishonest. If they lied about the contents of a record, it would invalidate the inclusion proofs of every successive record in the ledger.
In order to make a given record crypto-shreddable without breaking the inclusion proofs for every record that follows, we need to commit to the ciphertext, not the plaintext. (And then, when a takedown request comes in, wipe the key.)
Now, things are quite more interesting.
Do you…
- …Distribute the encryption key alongside the ciphertext and let independent third parties decrypt it on demand?
…OR…
- Decrypt the ciphertext and serve plaintext through the public API, keeping the encryption key private so that it may be shredded later?
The first option seems simple, but runs into governance issues: How do you claim the data was crypto-shredded if countless individuals have a copy of the encryption key, and can therefore recover the plaintext from the ciphertext?
Your best option is the second one, clearly.
Okay, so how does an end user know that the ciphertext that was committed to the transparency ledger decrypts to the specific plaintext value served by the Public Key Directory? How do users know it’s not lying?
Quick aside: This question is also relevant if you went with the first option and used a non-committing AEAD mode for the actual encryption scheme.
In that scenario, a hostile nation state adversary could pressure a Public Key Directory to selectively give one decryption key to targeted users, and another to the rest of the Internet, in order to perform a targeted attack against citizens they’d rather didn’t have civil rights.
My entire goal with introducing key transparency to my end-to-end encryption proposal is to prevent these sorts of attacks, not enable them.
There are a lot of avenues we could explore here, but it’s always worth outlining the specific assumptions and security goals of any design before you start perusing the literature.
Assumptions
This is just a list of things we assume are true, and do not need to prove for the sake of our discussion here today. The first two are legal assumptions; the remainder are cryptographic.
Ask your lawyer if you want advice about the first two assumptions. Ask your cryptographer if you suspect any of the remaining assumptions are false.
- Crypto-shredding is a legally valid way to provide data erasure (as discussed above).
- EU courts will consider public keys to be PII.
- The SHA-2 family of hash functions is secure (ignoring length-extension attacks, which won’t matter for how we’re using them).
- HMAC is a secure way to build a MAC algorithm out of a secure hash function.
- HKDF is a secure KDF if used correctly.
- AES is a secure 128-bit block cipher.
- Counter Mode (CTR) is a secure way to turn a block cipher into a stream cipher.
- AES-CTR + HMAC-SHA2 can be turned into a secure AEAD mode, if done carefully.
- Ed25519 is a digital signature algorithm that provides strong security against existent forgery under a chosen-message attack (SUF-CMA).
- Argon2id is a secure, memory-hard password KDF, when used with reasonable parameters. (You’ll see why in a moment.)
- Sigsum is a secure mechanism for building a transparency log.
This list isn’t exhaustive or formal, but should be sufficient for our purposes.
Security Goals
- The protocol messages stored in the Public Key Directory are accompanied by a Merkle tree proof of inclusion. This makes it append-only with an immutable history.
- The Public Key Directory cannot behave dishonestly about the decrypted plaintext for a given ciphertext without clients detecting the deception.
- Whatever strategy we use to solve this should be resistant to economic precomputation and brute-force attacks.
Can We Use Zero-Knowledge Proofs?
At first, this seems like an ideal situation for a succinct, non-interactive zero-knowledge proof.
After all, you’ve got some secret data that you hold, and you want to prove that a calculation is correct without revealing the data to the end user. This seems like the ideal setup for Schnorr’s identification protocol.
Unfortunately, the second assumption (public keys being considered PII by courts, even though they’re derived from random secret keys) makes implementing a Zero-Knowledge Proof here very challenging.
First, if you look at Ed25519 carefully, you’ll realize that it’s just a digital signature algorithm built atop a Schnorr proof, which requires some sort of public key (even an ephemeral one) to be managed.
Worse, if you try to derive this value solely from public inputs (rather than creating a key management catch-22), the secret scalar your system derives at will have been calculated from the user’s PII–which only strengthens a court’s argument that the public key is therefore personally identifiable.
There may be a more exotic zero-knowledge proof scheme that might be appropriate for our needs, but I’m generally wary of fancy new cryptography.
Here are two rules I live by in this context:
- If I can’t get the algorithms out of the crypto module for whatever programming language I find myself working with, it may as well not even exist.
- Corollary: If libsodium bindings are available, that counts as “the crypto module” too.
- If a developer needs to reach for a generic Big Integer library (e.g., GMP) for any reason in the course of implementing a protocol, I do not trust their implementation.
Unfortunately, a lot of zero-knowledge proof designs fail one or both of these rules in practice.
(Sorry not sorry, homomorphic encryption enthusiasts! The real world hasn’t caught up to your ideas yet.)
Soatok’s Proposed Solution
If you want to fully understand the nitty-gritty implementation details, I encourage you to read the current draft specification, plus the section describing the encryption algorithm, and finally the plaintext commitment algorithm.
Now that we’ve established all that, I can begin to describe my approach to solving this problem.
First, we will encrypt each attribute of a protocol message, as follows:
- For subkey derivation, we use HKDF-HMAC-SHA512.
- For encrypting the actual plaintext, we use AES-256-CTR.
- For message authentication, we use HMAC-SHA512.
- Additional associated data (AAD) is accepted and handled securely; i.e., we don’t use YOLO as a hash construction.
This prevents an Invisible Salamander attack from being possible.
Next, to prevent the server from being dishonest, we include a plaintext commitment hash, which is included as part of the AAD (alongside the attribute name).
(Implementing crypto-shredding is straightforward: simply wipe the encryption keys for the attributes of the records in scope for the request.)
If you’ve read this far, you’re probably wondering, “What exactly do you mean by plaintext commitment?”
Plaintext Commitments
The security of a plaintext commitment is attained by the Argon2id password hashing function.
By using the Argon2id KDF, you can make an effective trapdoor that is easy to calculate if you know the plaintext, but economically infeasible to brute-force attack if you do not.
However, you need to do a little more work to make it safe.
Pass the Salt?
Argon2id expects both a password and a salt.
If you eschew the salt (i.e., zero it out), you open the door to precomputation attacks (see also: rainbow tables) that would greatly weaken the security of this plaintext commitment scheme.
You need a salt.
If you generate the salt randomly, this commitment property isn’t guaranteed by the algorithm. It would be difficult, but probably not impossible, to find two salts (


I’m handwaving the fact that the salts are stored for now.
Deriving the salt from public inputs eliminates this flexibility.
By itself, this reintroduces the risk of making salts totally deterministic, which reintroduces the risk of precomputation attacks (which motivated the salt in the first place).
Furthermore, any two encryptions operations that act over the same plaintext would, without any additional design considerations, produce an identical value for the salt, which would lead to an identical plaintext commitment.
Getting to the Root of the Problem
The scheme I’m designing, which encrypts the attributes of protocol messages and includes a commitment of the plaintext, doesn’t exist in a vacuum.
In my system, there is one additional public input we can use to increase the quality of the salt distribution (to resist precomputation) without introducing variability (to ensure the commitment is robust): A recent Merkle tree root.
Since every protocol message accepted by a Public Key Directory will have a distinct Merkle root, a high-traffic Public Key Directory will produce a high-entropy root hash every time a user issues a new protocol message. This is especially true if, when issuing multiple successive messages, they use the root of their previous accepted Merkle root as the “recent” root when calculating their next plaintext commitment.
Given that Sigsum uses SHA256, there are 
Crisis Averted?
This sure sounds like a solution, but let’s also consider another situation.
High-traffic Public Key Directories may have multiple users push a protocol message with the same recent Merkle root.
Later, if both of these users issue a legal takedown, someone might observe that the recent-merkle-root is the same for two messages, but their salts differ.
Is this enough leakage to distinguish plaintext records?
After pondering this for a bit, I decided this was a stupid problem to have, and reached for an oft-ignored tool in a cryptographer’s toolkit (except for modern hash function designers): Truncation.
If we truncate the salt to a smaller value, we can increase the chance of a birthday collision.
We do need to be careful: Too small, and we improve the economics of precomputation. Too large, and we risk creating a reliably crib for distinct plaintext values.
How Much is Too Much?
Let’s revisit the birthday paradox.
If you have a probability space of 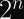
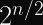
More interesting, you have a 

Given that I’m designing this project for the Fediverse, which has millions of accounts (and of which more than 100,000 can reasonably be considered “active”), I posit that a probability space of 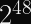
Because salts are expected to be 128 bits (at least with libsodium), we fix the other bytes to a protocol-specific constant, which contains some version information that can be changed in future iterations. This won’t be on the final exam.
Why
Simply put: we want salts to collide (albeit somewhat rarely).
Since the salt derivation algorithm is a faster hash than a KDF, collisions make it less useful for attackers hoping for a reliable plaintext crib.
With 48 bits left after truncation, a 50% collision probability is reached after 

How do you arrive at this number?
Let’s assume, for the moment, that my proposal sees widespread adoption with Fediverse users.
There are just under 11 million total, and 1 million monthly active, Fediverse users as of this writing. BlueSky just hit 20 million users.
These numbers are in the 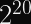

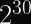
It is therefore expected that at least one pair of distinct plaintext Actor IDs, using two different recent Merkle roots, would produce the same salt for their plaintext commitment.
This gives attackers a disadvantage, since collisions make the salt (derived from a fast hash) useless, thereby forcing them to attack the KDF output instead.
Conversely, breaking the KDF output with precomputation strategies would still involve
This rounds off to about 9 petabytes of storage just for a 48-bit salt and a 208-bit Argon2id KDF output (for a total of 32 bytes).
Choosing Other Parameters
As mentioned a second ago, we set the output length of the Argon2id KDF to 26 bytes (208 bits). We expect the security of this KDF to exceed 
The other Argon2id parameters are a bit hand-wavey. Although the general recommendation for Argon2id is to use as much memory as possible, this code will inevitably run in some low-memory environments, so asking for several gigabytes isn’t reasonable.
For the first draft, I settled on 16 MiB of memory, 3 iterations, and a parallelism degree of 1 (for widespread platform support).
Plaintext Commitment Algorithm
With all that figured out, our plaintext commitment algorithm looks something like this:
- Calculate the HMAC-SHA512 hash (whose key is constant for domain separation) of:
- Recent Merle Root Lengh (64-bit unsigned integer)
- Recent Merkle Root
- Attribute Name Length (64-bit unsigned integer)
- Attribute Name
- Plaintext Length (64-bit unsigned integer)
- Plaintext
- Truncate this hash to the rightmost 6 bytes (48 bits).
- Calculate Argon2id with the salt set to the ASCII string
FE2EEPKDv1followed by the truncated hash (step 2), with an output length of 26 bytes (208 bits). - Concatenate the output steps 2 and 3.
The output (step 4) is included as the AAD in the attribute encryption step.
To verify a commitment (which is extractable from the ciphertext), simply recalculate the commitment you expect (using the recent Merkle root specified by the record), and compare the two in constant-time.
If they match, then you know the plaintext you’re seeing is the correct value for the ciphertext value that was committed to the Merkle tree.
If the encryption key is shredded in the future, an attacker without knowledge of the plaintext will have an enormous uphill battle recovering it from the KDF output (and the salt will prove to be somewhat useless as a crib).
Recap
I tasked myself with designing a Key Transparency solution that doesn’t make complying with Article 17 of the GDPR nigh-impossible. To that end, crypto-shredding seemed like the only viable way forward.
A serialized record containing ciphertext for each sensitive attribute would be committed to the Merkle tree. The directory would store the key locally and serve plaintext until a legal takedown was requested by the user who owns the data. Afterwards, the stored ciphertext committed to the Merkle tree is indistinguishable from random for any party that doesn’t already know the plaintext value.
I didn’t want to allow Public Key Directories to lie about the plaintext for a given ciphertext, given that they know the key and the requestor doesn’t.
After considering zero-knowledge proofs and finding them to not be a perfect fit, I settled on designing a plaintext commitment scheme based on the Argon2id password KDF, which uses a recent Merkle root to diversify the KDF salt selection, and truncates the result to make salt collisions likely (so anyone trying to attack the salt to guess plaintexts is at a disadvantage).
Altogether, this meets the requirements of enabling crypto-shredding while keeping the Public Key Directory honest. All known attacks for this design are prohibitively expensive for any terrestrial threat actors.
As an added bonus, I didn’t introduce anything fancy. You can build all of this with the cryptography available to your favorite programming language today.
Closing Thoughts
If you’ve made it this far without being horribly confused, you’ve successfully followed my thought process for developing message attribute shreddability in my Public Key Directory specification.
This is just one component of the overall design proposal, but one that I thought my readers would enjoy exploring in greater detail than the specification needed to capture.
如有侵权请联系:admin#unsafe.sh