2024-11-16 03:0:18 Author: hackernoon.com(查看原文) 阅读量:4 收藏
Hello everyone! I'm Dmitriy Apanasevich, Java Developer at MY.GAMES, working on the game Rush Royale, and I'd like to share our experience integrating the OpenTelemetry framework into our Java backend. There’s quite a bit to cover here: We’ll cover necessary code changes required to implement it, as well as the new components we needed to install and configure – and, of course, we’ll share some of our results.
Our goal: achieving system observability
Let’s give some more context to our case. As developers, we want to create software that’s easy to monitor, evaluate, and understand (and this is precisely the purpose of implementing OpenTelemetry — to maximize system
Traditional methods for gathering insights into application performance often involve manually logging events, metrics, and errors:

Of course, there are many frameworks that allow us to work with logs, and I’m sure that everyone reading this article has a configured system for collecting, storing and analyzing logs.
Logging was also fully configured for us, so we did not use the capabilities provided by OpenTelemetry for working with logs.
Another common way to monitor the system is by leveraging metrics:

We also had a fully configured system for collecting and visualizing metrics, so here too we ignored the capabilities of OpenTelemetry in terms of working with metrics.
But a less common tool for obtaining and analyzing this kind of system data are

A trace represents the path a request takes through our system during its lifetime, and it typically begins when the system receives a request and ends with the response. Traces consist of multiple
For this discussion, we'll concentrate on the tracing aspect of OpenTelemetry.
Some more background on OpenTelemetry
Let’s also shed some light on the OpenTelemetry project, which came about by merging the
OpenTelemetry now provides a comprehensive range of components based on a standard that defines a set of APIs, SDKs, and tools for various programming languages, and the project’s primary goal is to generate, collect, manage, and export data.
That said, OpenTelemetry does not offer a backend for data storage or visualization tools.
Since we were only interested in tracing, we explored the most popular open-source solutions for storing and visualizing traces:
- Jaeger
- Zipkin
- Grafana Tempo
Ultimately, we chose Grafana Tempo due to its impressive visualization capabilities, rapid development pace, and integration with our existing Grafana setup for metrics visualization. Having a single, unified tool was also a significant advantage.
OpenTelemetry components
Let’s also dissect the components of OpenTelemetry a bit.
The specification:
-
API — types of data, operations, enums
-
SDK — specification implementation, APIs on different programming languages. A different language means a different SDK state, from alpha to stable.
-
Data protocol (OTLP) and
semantic conventions
The Java API the SDK:
- Code instrumentation libraries
- Exporters — tools for exporting generated traces to the backend
- Cross Service Propagators — a tool for transferring execution context outside the process (JVM)
The OpenTelemetry Collector is an important component, a proxy that receives data, processes it, and passes it on – let's take a closer look.
OpenTelemetry Collector
For high-load systems handling thousands of requests per second, managing the data volume is crucial. Trace data often surpasses business data in volume, making it essential to prioritize what data to collect and store. This is where our data processing and filtering tool comes in and enables you to determine which data is worth storing. Typically, teams want to store traces that meet specific criteria, such as:
- Traces with response times exceeding a certain threshold.
- Traces that encountered errors during processing.
- Traces that contain specific attributes, such as those that passed through a certain microservice or were flagged as suspicious in the code.
- A random selection of regular traces that provide a statistical snapshot of the system's normal operations, helping you understand typical behavior and identify trends.

Here are the two main sampling methods used to determine which traces to save and which to discard:
- Head sampling — decides at the start of a trace whether to keep it or not
- Tail sampling — decides only after the complete trace is available. This is necessary when the decision depends on data that appears later in the trace. For example, data including error spans. These cases cannot be handled by head sampling since they require analyzing the entire trace first
The OpenTelemetry Collector helps configure the data collection system so that it will save only the necessary data. We will discuss its configuration later, but for now, let's move on to the question of what needs to be changed in the code so that it starts generating traces.
Zero-code instrumentation
Getting trace generation really required minimal coding – it was just necessary to launch our applications with a java-agent, specifying the
-javaagent:/opentelemetry-javaagent-1.29.0.jar
-Dotel.javaagent.configuration-file=/otel-config.properties
OpenTelemetry supports a huge number of
In our agent configuration, we disabled the libraries we’re using whose spans we didn’t want to see in the traces, and to get data about how our code worked, we marked it with
@WithSpan("acquire locks")
public CompletableFuture<Lock> acquire(SortedSet<Object> source) {
var traceLocks = source.stream().map(Object::toString).collect(joining(", "));
Span.current().setAttribute("locks", traceLocks);
return CompletableFuture.supplyAsync(() -> /* async job */);
}
In this example, the @WithSpan annotation is used for the method, which signals the need to create a new span named "acquire locks", and the "locks" attribute is added to the created span in the method body.
When the method finishes working, the span is closed, and it is important to pay attention to this detail for asynchronous code. If you need to obtain data related to the work of asynchronous code in lambda functions called from an annotated method, you need to separate these lambdas into separate methods and mark them with an additional annotation.
Our trace collection setup
Now, let's talk about how to configure the entire trace collection system. All our JVM applications are launched with a Java agent that sends data to the OpenTelemetry collector.
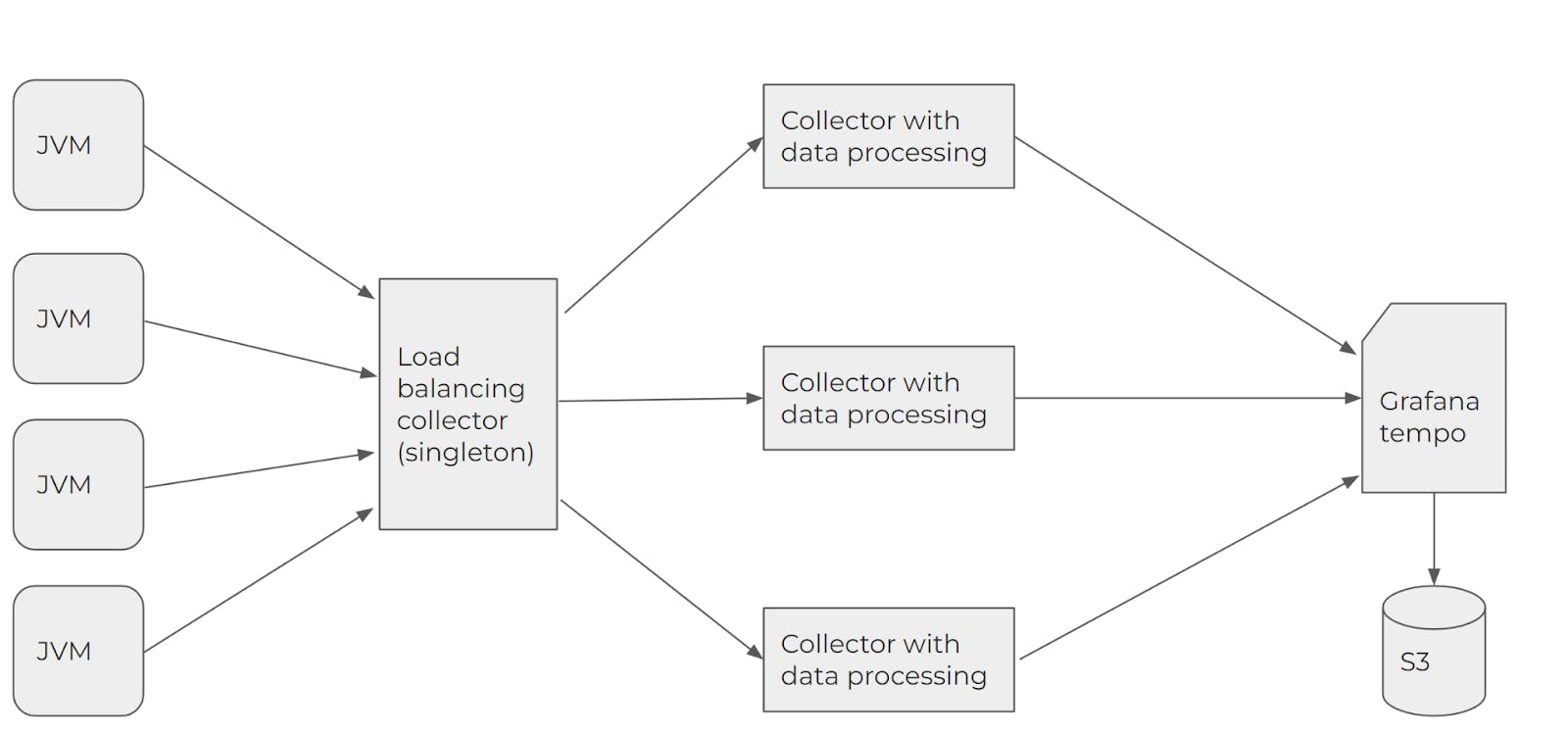
However, a single collector cannot handle a large data flow and this part of the system must be scaled. If you launch a separate collector for each JVM application, tail sampling will break, because trace analysis must occur on one collector, and if the request goes through several JVMs, the spans of one trace will end up on different collectors and their analysis will be impossible.
Here, a
As a result, we get the following system: Each JVM application sends data to the same balancer collector, whose only task is to distribute data received from different applications, but related to a given trace, to the same collector-processor. Then, the collector-processor sends data to Grafana Tempo.

Let's take a closer look at the configuration of the components in this system.
Load balancing collector
In the collector-balancer configuration, we’ve configured the following main parts:
receivers:
otlp:
protocols:
grpc:
exporters:
loadbalancing:
protocol:
otlp:
tls:
insecure: true
resolver:
static:
hostnames:
- collector-1.example.com:4317
- collector-2.example.com:4317
- collector-3.example.com:4317
service:
pipelines:
traces:
receivers: [otlp]
exporters: [loadbalancing]
- Receivers — where the methods (via which data can be received by the collector) are configured. We've configured data reception solely in the OTLP format. (It is possible to configure the reception of data via
many other protocols , for example Zipkin, Jaeger.) - Exporters — the part of the configuration where data balancing is configured. Among the collectors-processors specified in this section, the data is distributed depending on the hash calculated from the trace identifier.
- The Service section specifies the configuration of how the service will work: only with traces, using the OTLP receiver configured on top and transmitting data as a balancer, i.e. without processing.
The collector with data processing
The configuration of collectors-processors is more complicated, so let’s take a look there:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:14317
processors:
tail_sampling:
decision_wait: 10s
num_traces: 100
expected_new_traces_per_sec: 10
policies:
[
{
name: latency500-policy,
type: latency,
latency: {threshold_ms: 500}
},
{
name: error-policy,
type: string_attribute,
string_attribute: {key: error, values: [true, True]}
},
{
name: probabilistic10-policy,
type: probabilistic,
probabilistic: {sampling_percentage: 10}
}
]
resource/delete:
attributes:
- key: process.command_line
action: delete
- key: process.executable.path
action: delete
- key: process.pid
action: delete
- key: process.runtime.description
action: delete
- key: process.runtime.name
action: delete
- key: process.runtime.version
action: delete
exporters:
otlp:
endpoint: tempo:4317
tls:
insecure: true
service:
pipelines:
traces:
receivers: [otlp]
exporters: [otlp]
Similar to the collector-balancer configuration, the processing configuration consists of Receivers, Exporters, and Service sections. However, we'll focus on the Processors section, which explains how data is processed.
First, the tail_sampling section demonstrates a
-
latency500-policy: this rule selects traces with a latency exceeding 500 milliseconds.
-
error-policy: this rule selects traces that encountered errors during processing. It searches for a string attribute named "error" with values "true" or "True" in the trace spans.
-
probabilistic10-policy: this rule randomly selects 10% of all traces to provide insights into normal application operation, errors, and long request processing.
In addition to tail_sampling, this example shows the resource/delete section to delete unnecessary attributes not required for data analysis and storage.
Results
The resulting Grafana trace search window enables you to filter data by various criteria. In this example, we simply display a list of traces received from the lobby service, which processes game metadata. The configuration allows for future filtering by attributes like latency, errors, and random sampling.

The trace view window displays the execution timeline of the lobby service, including the various spans that make up the request.
As you can see from the picture, the sequence of events is as follows — locks are acquired, then objects are retrieved from the cache, followed by the execution of a transaction that processes the requests, after which the objects are stored in the cache again and the locks are released.
The spans related to database requests were automatically generated due to the instrumentation of standard libraries. In contrast, the spans related to lock management, cache operations, and transaction initiation were manually added to the business code using the aforementioned annotations.

When viewing a span, you can see attributes that allow you to better understand what happened during processing, for example, see a query in the database.

One of the interesting features of Grafana Tempo is the


Wrapping up
As we’ve seen, working with OpenTelemetry tracing has enhanced our observation abilities quite nicely. With minimal code changes and a well-structured collector setup, we got deep insights – plus, we saw how Grafana Tempo's visualization capabilities further complemented our setup. Thanks for reading!
如有侵权请联系:admin#unsafe.sh