导语:在过去的三年中,Firefox的模糊测试团队一直在开发一个新的模糊测试程序,以帮助识别在Firefox中实施WebAPI时的安全漏洞。我们将这种Fuzzer称为Domino,它利用WebAPI自己的WebIDL定义作为Fuzzing语法。
基础介绍
模糊测试是一种用于测试软件安全性和稳定性的自动化方法。通常通过提供特制的输入来识别危险的操作行为。如果你不熟悉Fuzzing的基础知识,可以在Firefox Fuzzing Docs和Fuzzing Book中先学习一下。
在过去的三年中,Firefox的模糊测试团队一直在开发一个新的模糊测试程序,以帮助识别在Firefox中实施WebAPI时的安全漏洞。我们将这种Fuzzer称为Domino,它利用WebAPI自己的WebIDL定义作为Fuzzing语法。我们的方法已识别出850多个漏洞,这些漏洞中的116个已获得安全评级。在本文中,我想讨论Domino的一些关键功能,以及它们与我们以前的WebAPI模糊测试工作有何不同。
Fuzzing基础
在开始讨论什么是Domino及其工作原理之前,我们首先需要讨论当今可用的模糊技术的类型。
Fuzzer的类型
Fuzzer通常分为黑盒,灰盒或白盒。这些类型基于Fuzzer与目标应用程序之间的通信级别,最常见的两种类型是黑盒和灰盒Fuzzer。
黑盒模糊测试
黑盒模糊测试将数据提交到目标应用程序时,基本上不知道该数据如何影响目标。由于这一限制,黑盒Fuzzer的有效性完全基于生成数据的适用性。
黑盒模糊测试通常用于大型,不确定的应用程序或处理高度结构化数据的应用程序。
白盒模糊测试
白盒模糊测试可在模糊测试器与目标应用程序之间建立直接关联,以便生成满足应用程序“要求”的数据。这通常涉及使用求解器评估分支条件并生成数据以有意行使所有分支。这样,Fuzzer可以测试难以到达的分支,而黑盒或灰盒Fuzzer可能永远不会对其进行测试。
这种模糊测试的弊端是计算量大。具有复杂分支的大型应用程序可能需要大量时间才能解决,这大大减少了测试输入的数量。在学术之外,白盒模糊测试对于实际应用通常是不可行的。
灰盒模糊测试
Greybox模糊测试已成为最流行和有效的模糊测试技术之一。这些Fuzzer通常通过Fuzzer实现反馈机制,以告知有关将来要生成哪些数据的决策。看起来可以覆盖更多代码的输入将被重用作为以后测试的基础,减少覆盖范围的输入将被丢弃。
由于该方法在达到模糊代码路径方面的速度和效率非常受欢迎。但是,并非所有目标都是灰盒模糊测试的理想选择。Greybox模糊测试通常最好与较小的确定性目标配合使用,这些目标可以快速(数百秒)处理大量输入。
我们经常使用这些类型的Fuzzer来测试Firefox中的各个组件,例如媒体解析器。如果你想学习如何利用这些Fuzzer来测试代码,请查看此处的Fuzzing Interface文档。
不幸的是,我们在Fuzzing WebAPI时可以使用的技术有些局限。浏览器本质上是不确定的,并且输入是高度结构化的。此外,启动浏览器,执行测试以及监视故障的过程很慢(每次测试需要几秒钟到几分钟)。由于这些限制,黑盒模糊测试是最合适的解决方案。
但是,由于这些API期望的输入是高度结构化的,因此我们需要确保我们的Fuzzer生成的数据有效。
基于语法的模糊测试
基于语法的模糊测试是一种模糊测试技术,它使用形式语言语法来定义要生成的数据的结构。这些语法通常以纯文本形式表示,并使用符号和常量的组合来表示数据。然后,Fuzzer可以解析语法并使用它生成模糊输出。

这里的示例演示了Domato和DharmaFuzzer的两个简化的语法摘录。这些语法描述了创建HTMLCanvasElement和操纵其属性和操作的过程。
传统语法的缺陷
不幸的是,开发语法所需的工作量与你要表示的数据的大小和复杂性成正比。这是基于语法的模糊测试的最大缺点。作为参考,Firefox中的WebAPI公开了具有大约6300个成员的730个接口。此数字并未说明其他必需的数据结构,例如回调,枚举或字典等。创建一个语法来准确描述这些API将会是一项艰巨的任务。
为了更有效地Fuzzing这些API,我们希望尽可能避免手工语法开发。
WebIDL作为Fuzzing语法
typedef (BufferSource or Blob or USVString) BlobPart;
[Exposed=(Window,Worker)]
interface Blob {
[Throws]
constructor(optional sequence blobParts,
optional BlobPropertyBag options = {});
[GetterThrows]
readonly attribute unsigned long long size;
readonly attribute DOMString type;
[Throws]
Blob slice(optional [Clamp] long long start,
optional [Clamp] long long end,
optional DOMString contentType);
[NewObject, Throws] ReadableStream stream();
[NewObject] Promise text();
[NewObject] Promise arrayBuffer();
};
enum EndingType { "transparent", "native" };
dictionary BlobPropertyBag {
DOMString type = "";
EndingType endings = "transparent";
};Blob WebIDL定义的简化示例
WebIDL是一种接口描述语言(IDL),用于描述浏览器实现的API。它列出了这些API公开的接口,成员和值以及语法。
WebIDL定义在浏览器模糊测试社区中众所周知,因为其中包含大量信息。在这方面已经完成了许多的工作,从这些IDL中提取数据以用作Fuzzing语法,即Sensepost的WADI模糊器。但是,在我们研究的每个示例中,我们发现这些定义中的信息是使用Fuzzer的语法提取并重新实现的。这种方法仍然需要大量的人工操作,而且,Fuzzing语法的语法使描述某些特定于WebAPI的行为(即使在某些情况下不是不可能)变得困难。
基于这些问题,我们决定直接使用WebIDL定义,而不是将其转换为现有的Fuzzing语法。这种方法为我们提供了许多好处。
标准化语法
首先,WebIDL规范定义了这些定义必须遵守的标准化语法。这使我们能够利用现有工具(例如WebIDL2.js)来解析原始WebIDL定义并将其转换为抽象语法树(AST)。然后,Fuzzer可以解释此AST以生成测试用例。
简化语法
其次,WebIDL定义了我们打算针对的API的结构和行为。因此,大大减少了所需规则制定的数量;相反,如果要使用前面提到的一种语法描述这些API,则必须为API定义的每个接口,成员和值创建单独的规则。
ECMAScript扩展属性
与仅定义数据结构的传统语法不同,WebIDL规范通过ECMAScript扩展属性提供有关接口行为的其他信息,扩展属性可以描述各种行为,包括:
· 可以使用特定接口的上下文。
· 返回的对象是新实例还是重复实例。
· 如果成员实例可以替换。
这些类型的行为通常不通过传统语法来表示。
自动检测API更改
最后,由于WebIDL文件与浏览器实现的接口链接,我们可以确保对WebIDL的更新反映对接口的更新。
将IDL转换为JavaScript

为了利用WebIDL进行模糊测试,我们首先需要对其进行解析。对我们来说幸运的是,我们可以使用WebIDL2.js库将原始IDL文件转换为抽象语法树(AST)。WebIDL2.js生成的AST将数据描述为树上的一系列节点,这些节点中的每一个都定义WebIDL语法的某种构造。
有关WebIDL2 AST结构的更多信息,请参见此处。
有了AST之后,我们只需要为每个结构定义做转换。在Domino中,我们实现了一系列用于遍历AST并将AST节点转换为JavaScript的工具。
这些节点中的大多数可以使用静态转换表示。这意味着AST中的构造在JavaScript中将始终具有相同的表示形式。例如,构造器关键字将始终被JavaScript“ new”运算符与接口名称结合使用。但是,在某些情况下,WebIDL构造可能具有多种含义,必须动态生成。
通用类型
WebIDL说明列出了用于表示一般值多种类型。对于每种类型,Domino实现一个函数,该函数将返回与请求的类型匹配的随机生成的值,或者返回先前记录的相同类型的对象。例如,当迭代AST时,出现octet,short和long的数字类型将返回这些数字范围内的值。
对象引用
在构造类型引用另一个IDL定义并用作参数的地方,这些值需要该IDL类型的对象实例。当识别出这些值之一时,Domino将尝试创建该对象的新实例(通过其构造函数)。或者,它将尝试通过标识并访问另一个返回该类型对象的成员来做到这一点。
回调处理程序
WebIDL规范还定义了许多表示函数的类型(即promises,callbacks和event listeners)。对于每种类型,Domino都会生成一个独特的函数,该函数对提供的参数(如果存在)执行随机操作。
当然,上述步骤仅占将IDL完全转换为JavaScript所需的一小部分。Domino的生成器实现了对整个WebIDL规范的支持,让我们看一下使用Blob WebIDL作为Fuzzing语法的输出结果。
Fuzzing配置
> const { Domino } = require('~/domino/dist/src/index.js')
> const { Random } = require('~/domino/dist/src/strategies/index.js')
> const domino = new Domino(blob, { strategy: Random, output: '~/test/' })
> domino.generateTestcase()
…
const o = []
o[2] = new ArrayBuffer(8484)
o[1] = new Float64Array(o[2])
o[0] = new Blob([o[1]])
o[0].text().then(function (arg0) {
o[0].text().then(function (arg1) {
o[3] = o[0].slice()
o[3].stream()
o[3].slice(65535, 1, ‘foobar’)
})
})
o[0].arrayBuffer().then(function (arg2) {
o[3].text().then(function (arg3) {
O[4] = arg3
o[0].slice()
})
})正如我们在这里看到的那样,IDL提供的信息足以生成有效的测试用例,这些案例使用了与Blob相关的代码中的一部分。反过来,这使我们可以在零人工干预的情况下快速为新的API开发Fuzzer。
不幸的是,并非所有事情都像我们希望的那样精确。以提供给切片操作的值为例,在查看了Blob规范之后,我们看到开始和结束参数应该是相对于Blob大小的字节顺序位置。因此,我们似乎不太可能能够返回Blob长度限制内的值。
此外,contentType切片操作的参数和BlobPropertyBag字典上的type属性都定义为DOMString。与数值类似,我们随机生成字符串。但是,对该规范的进一步审查表明,这些值用于表示Blob数据的媒体类型。现在,似乎该值对Blob对象没有直接影响。不过,我们无法确定这些值不会对使用这些Blob的API产生影响。
为了解决这些问题,我们需要开发一种区分这些通用类型的方法。
使用GrIDL更改

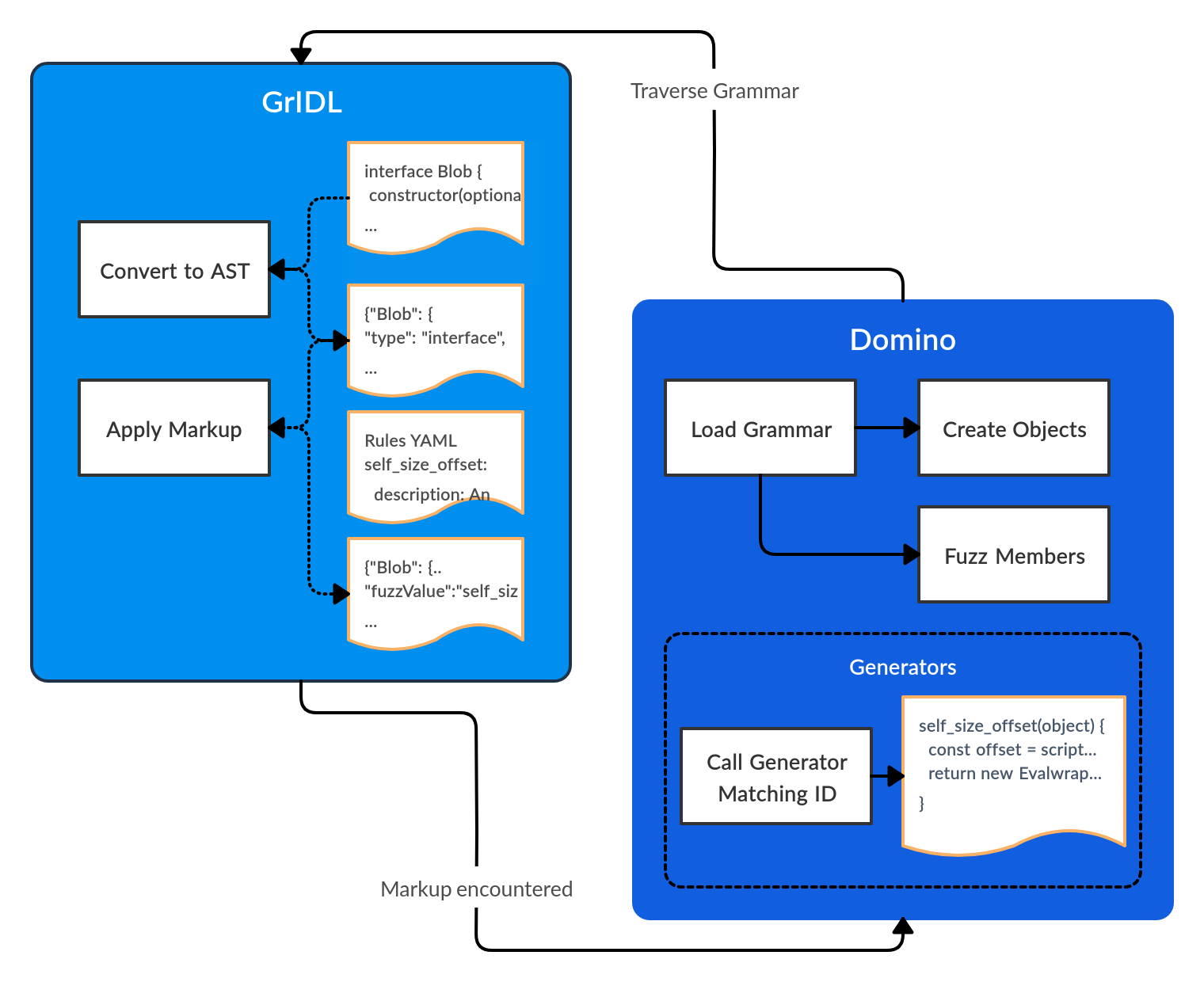
为此,我们开发了另一个名为GrIDL的工具。GrIDL利用WebIDL2.js库将IDL定义转换为AST。它还对AST进行了一些优化,以更好地支持AST作为Fuzzing语法的使用。
但是,GrIDL的最有趣的功能是:在需要更精确值的地方,我们可以动态修补IDL声明。使用基于规则的匹配系统,GrIDL可以识别目标值并插入唯一的标识符。这些标识符与Domino实现的匹配生成器相对应,在AST上进行迭代时,如果遇到这些标识符之一,则Domino将调用匹配的生成器并发出返回的值。

上图演示了GrIDL标识符和Domino生成器之间的相关性。在这里,我们定义了两个生成器:一个返回字节偏移量,另一个返回有效的MIME类型。
重要的是要注意,每个生成器还将获得对当前被模糊处理的对象的实时表示的访问权,这使我们能够生成由对象的当前状态告知的值。
在上面的示例中,我们利用此对象为slice函数生成相对于其长度的字节偏移。但是,请考虑与WebGLRenderingContextBase接口关联的任何属性或操作。该接口可以通过WebGL或WebGL2上下文实现。通过引用被模糊化的当前对象,我们可以确定上下文类型并相应地返回值。
> domino.generateTestcase()
…
const o = []
o[1] = new Uint8Array(14471)
o[0] = new Blob([null, null, o[1]], {
'type': 'image/*',
'endings': 'transparent'
})
o[2] = o[0].slice((1642420336 % o[0].size), (3884321603 % o[0].size), 'application/xhtml+xml')
o[0].arrayBuffer().then(function (arg0) {
setTimeout(function () { o[0].text().then(function (arg1) { o[0].stream() }) }, 180)
o[2].arrayBuffer().then(function (arg2) {
o[0].slice((3412050218 % o[0].size), (646665894 % o[0].size), 'text/plain')
o[0].stream()
})
o[2].text().then(function (arg3) {
o[2].slice((2025414481 % o[2].size), (2615146387 % o[2].size), 'text/html')
o[3] = o[0].slice((753872984 % o[0].size), (883984089 % o[0].size), 'text/xml')
o[3].stream()
})
})使用我们新创建的规则,我们现在能够生成与规范描述的值更相似的值。
实战例子
这篇文章中包含的示例已大大简化。通常很难看到如何将这种方法应用于更复杂的API,因此,我想举一个Domino挖掘的较复杂漏洞之一的示例。

在漏洞1558522中,我们确定了影响IndexedDB API的严重的UAF漏洞。从Fuzzing的角度来看,此漏洞非常有趣,因为触发该漏洞所需的复杂程度很高。Domino通过在全局上下文中创建文件,然后将文件对象传递到建立IndexedDB数据库连接的工作程序上下文中,可以触发此漏洞。
使用传统语法通常难以描述上下文之间的这种协调水平。但是,由于WebIDL提供的这些API的详细说明,Domino可以轻松识别此类漏洞。
本文翻译自:https://hacks.mozilla.org/2020/04/fuzzing-with-webidl/如若转载,请注明原文地址:
如有侵权请联系:admin#unsafe.sh