2024-11-4 14:10:59 Author: isc.sans.edu(查看原文) 阅读量:4 收藏
Once in a while, I get a question about my pdf-parser.py tool, not able to decode strings and streams from a PDF document.
And often, I have the answer without looking at the PDF: it's encrypted.
PDF documents can be encrypted, and what's special about encrypted PDFs, is that the structure of the PDF document is not encrypted. You can still see the objects, dictionaries, ... . What gets encrypted, are the strings and streams.
So my tools pdfid and pdf-parser can provide information about the structure of an encrypted PDF document, but not the strings and streams.
My PDF tools do not support encryption, you need to use another open source tool: qpdf, developed by Jay Berkenbilt.
A PDF document can be encrypted for DRM and/or for confidentiality. PDFs encrypted solely for DRM, can be opened and viewed by the user without providing a password. PDFs encrypted for confidentiality can only be opened and viewed when the user provides the correct password.
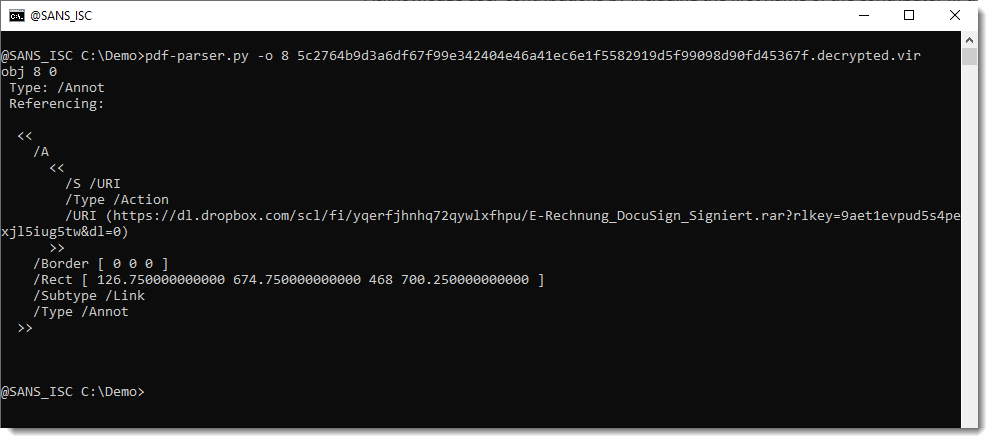
Let's take an example of a phishing PDF: 5c2764b9d3a6df67f99e342404e46a41ec6e1f5582919d5f99098d90fd45367f.
Analyzing this document with pdfid gives this:
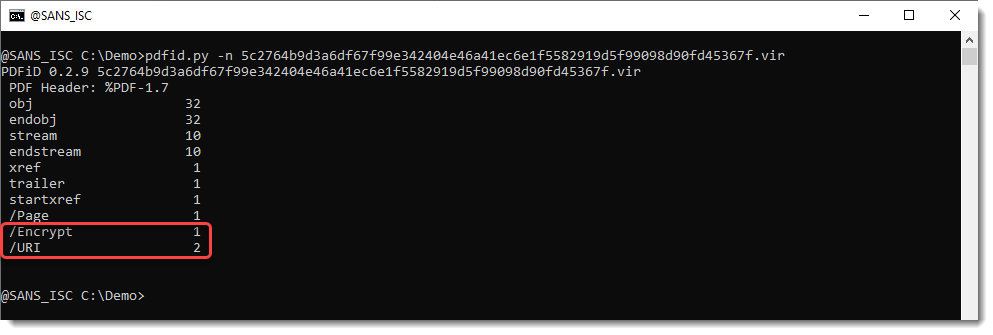
The document is encrypted (/Encrypt is greater than 0) and it contains URIs (/URI is greater than 0).
qpdf can help you determine if a password is needed to view the content, like this:
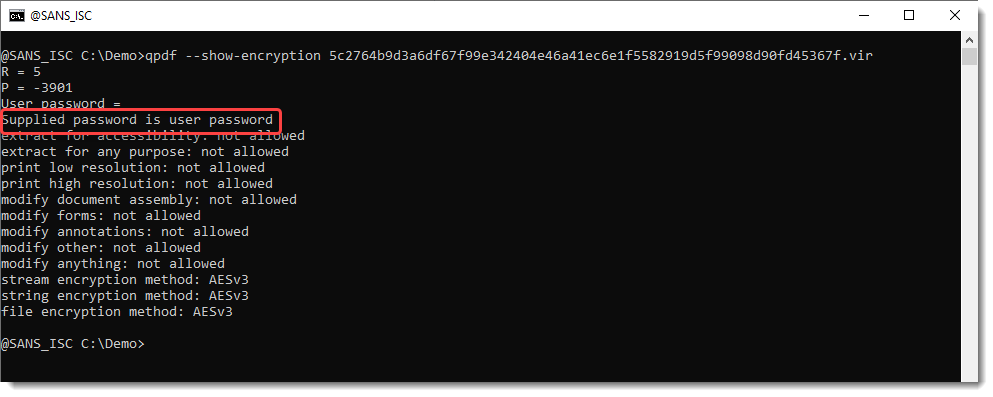
If you get this output without providing a password, it means that the user password is empty and that the document can be opened without providing a password.
You must then decrypt the PDF with qpdf for further analysis like this:

And then it can be analyzed with pdf-parser to extract the URI like this:
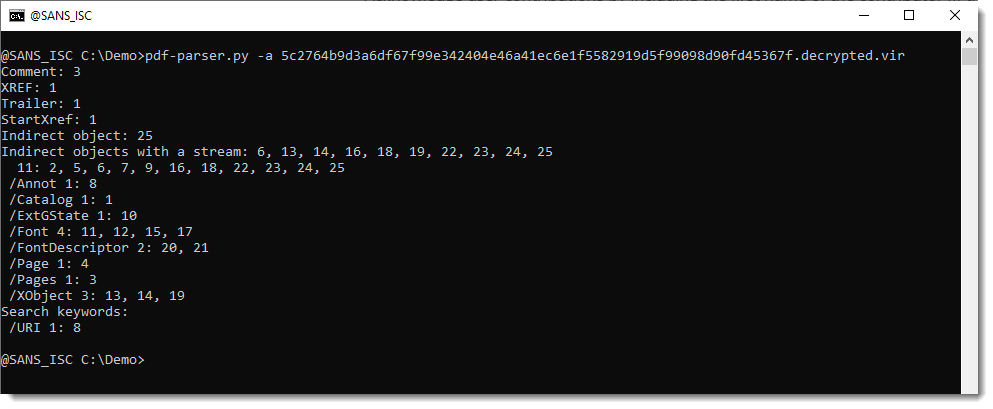
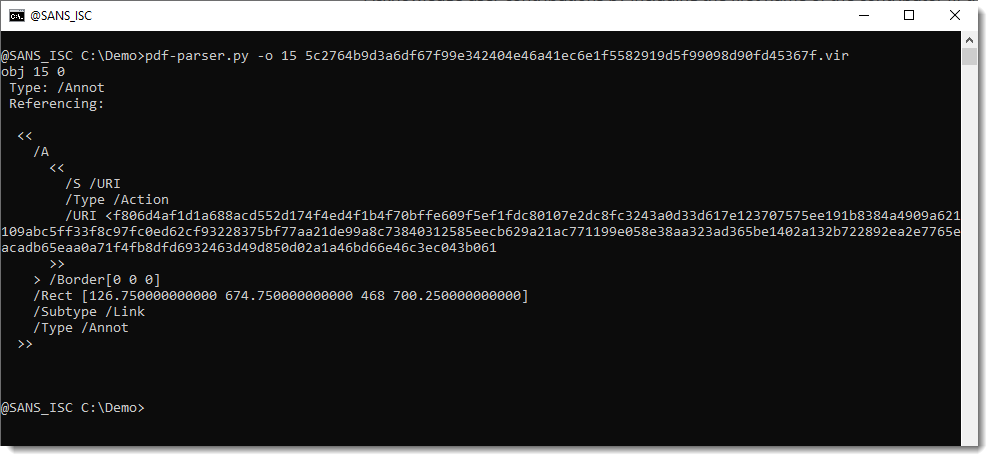
If you don't decrypt the PDF prior to analysis with pdf-parser, the string of the URI will be ciphertext:
Didier Stevens
Senior handler
blog.DidierStevens.com
如有侵权请联系:admin#unsafe.sh