2024-11-1 07:26:18 Author: hackernoon.com(查看原文) 阅读量:3 收藏
If you check popular benchmarks used for measuring LLM performance, then you probably feel like AI is oh sooo clever.
This is a fair surface-level impression; however, is AI truly better than an average human for cognitive tasks?
Frontier models like o1 from OpenAI and Claude 3.5 Sonnet from Anthropic do perform better than expert humans in a number of fields, including law, coding, and math. Why, then, can’t ChatGPT solve some simple spatial reasoning tasks or some silly trick questions? Well, we are still talking about “large language models"—they take in a ton of letters and try to predict what letters to spit out for a given query.
Notice, that nowhere in this equation the actual “thinking” is mentioned. The models are stochastic parrots of a sort, as they try to retrieve the right information from their training dataset instead of actually considering your question. At least, this was the case until OpenAI released o1-preview, but more on this later.
Among those who started questioning the existing LLM benchmarks for relevance is the author of “AI Explained” a popular YouTube channel of which I’m a big fan. Phillip (the YouTuber’s name) noticed that the industry standard benchmarks have a clear style of questions that are also mostly publicly available. This means that not only can those exact questions be part of the training dataset, but due to standardization, it is easier for models to spot & apply patterns from the overall training data.
Put simply, AI researchers who create groundbreaking complex tech can surely find a way to give their model the relevant questions and answers to “remember” before benchmarking.

Looking at the results of the top model out there, o1 from OpenAI, one can imply that it scores above average in a lot of professional domains. And this is true, but this result relies on the availability of relevant training data and past examples from those specific fields. Don’t get me wrong, the models are now amazing at giving textbook answers to textbook questions, and this in itself is insanely impressive.
The term “artificial intelligence," though, implies a bit more than just information retrieval; there should be some actual thinking involved. So a logical follow-up to all of the impressive numbers above is whether such “AI” can answer a tricky reasoning question. Does it have any spatial intelligence? Or can it navigate well in common social scenarios? The answer is - sometimes.
Unlike field-specific questions with predefined answers, problems that humans solve on a daily basis often require understanding the context beyond natural language (which is the only thing LLMs have).

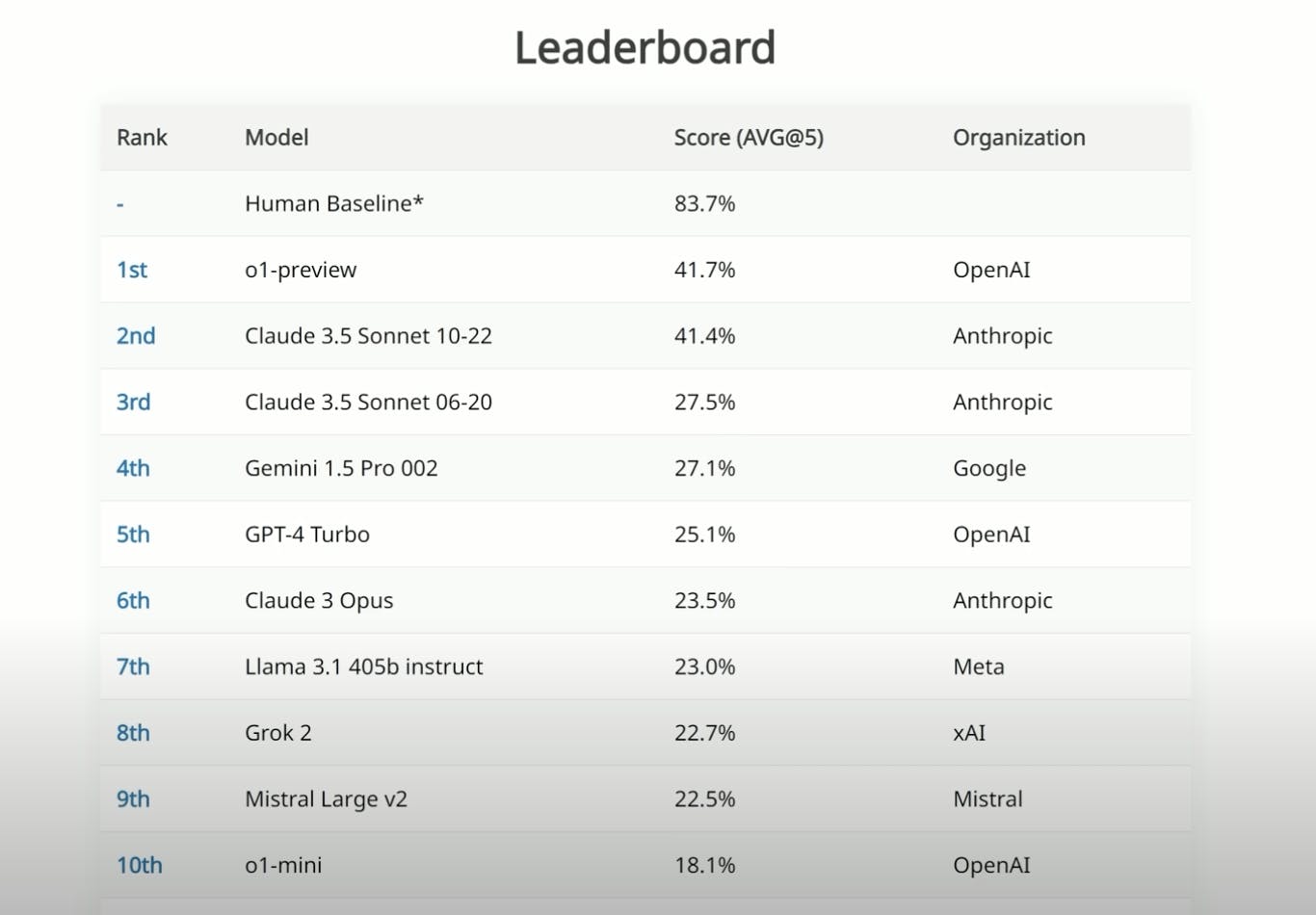
Above are the top scorers on the SIMPLE benchmark, which gives LLMs questions that an average person would deem trivial but the models can’t necessarily answer yet. We are used to seeing AI doing so much better than an average human in exams or specialized benchmarks, but here, the top model performance is actually just 41.7% (o1-preview) vs. 83.7% of an average human. This benchmark uses 200 multiple-choice text questions focused on spatio-temporal reasoning, social intelligence, and trick questions.
The most important feature of the benchmark is that those questions are not publicly available, so AI labs cannot just add them to their training data. You can learn more about this benchmark here.
This new approach to measuring LLM performance shows just how far all the models still are from an average human reasoning capability. The quicker this gap closes in the coming months, the more definitive the answer “yes” to our headline becomes. An interesting new metric to look out for if you are enthusiastic but cautious about AI.
如有侵权请联系:admin#unsafe.sh