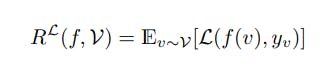
2024-10-21 09:21:30 Author: hackernoon.com(查看原文) 阅读量:0 收藏
Authors:
(1) Junwei Su, Department of Computer Science, the University of Hong Kong and [email protected];
(2) Chuan Wu, Department of Computer Science, the University of Hong Kong and [email protected].
Table of Links
5 A Case Study on Shortest-Path Distance
6 Conclusion and Discussion, and References
9 Procedure for Solving Eq. (6)
10 Additional Experiments Details and Results
11 Other Potential Applications
3 Framework
In this section, we introduce our proposed framework, which aims to investigate the intricate relationship between topology awareness and generalization performance in GNNs. The main idea of the framework is to use metric distortion to characterize the topology awareness of GNNs. With this characterization, we are able to show the relation between topology awareness of GNNs and their generalization performance.
3.1 GNN Preliminaries
Let G = (V, E, X) be an undirected graph where V = {1, 2, ..., n} is the set of n nodes and E ⊆ V × V is the set of edges. Let X = {x1, x2, ..., xn} denote the set of node attribute vectors corresponding to all the nodes in V. More specifically, xv ∈ X is an m-dimensional vector which captures the attribute values of node v ∈ V. In addition, each vertex v ∈ V is associated with a node label yv ∈ {1, ..., c}, where c is the total number of classes.
For our analysis, we focus on the transductive node classification setting [47], where the graph G are observed prior to learning and labels are only available for a small subset of nodes V0 ⊂ V. Without loss of generality, we treat G as fixed throughout our analysis and the randomness comes from the labels y. Given a small set of the labelled nodes, V0 ⊂ V, the task of node-level semi-supervised learning is to learn a classifier f, such that yˆv = f(v), from a hypothesis space F and perform it on the remaining unlabeled nodes. Let L(., .) 7→ R+ be a bounded continuous loss function. We denote by RL(f, V) the generalization risk of the classifier f with respect to L and V and it is defined as follows,

In our case, the hypothesis space is captured by a GNN and an additional read-out function. GNNs are commonly used as an embedding function and adopt a neighbourhood aggregation scheme, where the representation of a node is learnt iteratively by aggregating representations of its neighbours. After k iterations of aggregation, a node’s representation captures the information within its k-hop neighbourhood in the graph. Formally, the k-th layer of a GNN can be written as follows,


It should be noted that the distance function in Def. 2 is not symmetrical, and Eq. 4 captures the maximal structural difference of vertices in V1 to V2. To provide further insight into the concept of a structural subgroup, let’s consider a scenario where V0 ⊂ V represents the training set and ds(.) represents the shortest-path distance. In this context, we can partition the remaining vertices V\V0 into different structural subgroups based on their shortest-path distance to the nearest vertex in the training set. Specifically, we can define Vk = {v ∈ V\V0|Ds(v, V0) = k}. However, it is important to emphasize that our analysis does not assume a specific partition scheme, and the framework remains adaptable to various scenarios.
3.3 Topology Awareness
To characterize and formalize the topology awareness of GNNs, we introduce the concept of distortion, which measures the degree to which the graph structure is preserved in the embedding space. Mathematically, the distortion of a function between two general metric spaces is defined as,

The definition above captures the maximum expansion and minimum contraction between the two metric spaces. In the extreme case when α = 1, the mapping γ is the so-called isometric mapping that perfectly preserves the distance between any two points in the space. In other words, for any two points x and y in the domain of the function, their distance d(x, y) in the original metric space is equal to the distance d ′ (γ(x), γ(y)) in the target metric space (up to a constant scaling factor). If the distortion rate of the mapping is close to 1, then this mapping is said to have a low distortion rate.
In the context of GNNs, evaluating distortion involves a straightforward comparison of embeddings in the embedding domain with the structural measures on the graph, as demonstrated in the case study. If the distortion rate between the graph domain and the embedding domain is close to 1, the resulting embedding would largely preserve the corresponding structural information from the graph space, thereby indicating high topology awareness. Consequently, distortion can be employed to measure the topology awareness of GNNs concerning the corresponding structural properties (e.g., shortest-path distance) measured in the graph domain. Consequently, distortion can be employed to measure the topology awareness of GNNs concerning the corresponding structural properties (e.g., shortest-path distance) measured in the graph domain. This concept of distortion is agnostic to specific structural configurations, enabling the study of diverse graph structures using appropriate distance functions. Moreover, its estimation can be readily achieved by comparing the embedding with the original structural measure, as illustrated later in the case study
如有侵权请联系:admin#unsafe.sh