2024-10-17 21:0:21 Author: hackernoon.com(查看原文) 阅读量:1 收藏
Authors:
(1) Divyanshu Kumar, Enkrypt AI;
(2) Anurakt Kumar, Enkrypt AI;
(3) Sahil Agarwa, Enkrypt AI;
(4) Prashanth Harshangi, Enkrypt AI.
Table of Links
2 Problem Formulation and Experiments
2 PROBLEM FORMULATION AND EXPERIMENTS
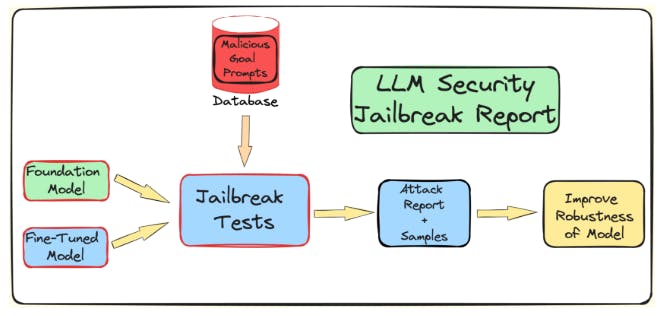
We want to understand the role played by fine-tuning, quantization, and guardrails on LLM’s vulnerability towards jailbreaking attacks. We create a pipeline to test for jailbreaking of LLMs which undergo these further processes before deployment. As mentioned in the introduction, we attack the LLM via the TAP algorithm using the AdvBench subset. We use a subset of AdvBenchAndy Zou (2023). It contains 50 prompts asking for harmful information across 32 categories. The evaluation results, along with the complete system information, are then logged. The overall flow is shown in the figure 2. This process continues for multiple iterations, taking into account the stochastic nature associated with LLMs. The complete experiment pipeline is shown in Figure 2.
TAP Mehrotra et al. (2023) is used as the jailbreaking method, as it is currently the state-of-the-art, black-box, and automatic method which generates prompts with semantic meaning to jailbreak LLMs. TAP algorithm uses an attacker LLM A, which sends a prompt P to the target LLM T. The response of the target LLM R along with the prompt P are fed into the evaluator LLM JUDGE, which determines if the prompt is on-topic or off-topic. If the prompt is off-topic, it is removed, thereby eliminating the tree of bad attack prompts it was going to generate. Otherwise, if the prompt is on-topic, it receives a score between 0-10 by the JUDGE LLM. This prompt is used to generate a new attack prompt using breadth-first search. This process continues till the LLM is jailbroken or a specified number of iterations are exhausted.
Now describing our guardrail against jailbreaking prompts, we use our in-house Deberta-V3 model, which has been trained to detect jailbreaking prompts. It acts as an input filter to ensure that only

sanitized prompts are received by the LLM. If the input prompt is filtered out by the guardrail or fails to jailbreak the LLM, then the TAP algorithm generates a new prompt considering the initial prompt and response. The new attacking prompt is then again passed through the guardrail. This process is repeated till a jailbreaking prompt is found or a pre-specified number of iterations are exhausted.
如有侵权请联系:admin#unsafe.sh