Ever wondered how software introduces itself to servers? Enter the User-Agent header—a digital ID that reveals crucial details about the client making an HTTP request. As you’re about to learn, setting a user agent for scraping is a must!
In this article, we’ll break down what a user agent is, why it's vital for web scraping, and how rotating it can help you avoid detection. Ready to dive in? Let’s go!
What’s a User Agent?
The User-Agent is a popular HTTP header automatically set by applications and libraries when making HTTP requests. It contains a string that spills the beans about your application, operating system, vendor, and the version of the software making the request.
That string is also known as a user agent or UA. But why the name “User-Agent”? Simple! In IT lingo, a user agent is any program, library, or tool that makes web requests on your behalf.
A Closer Look at a User Agent String
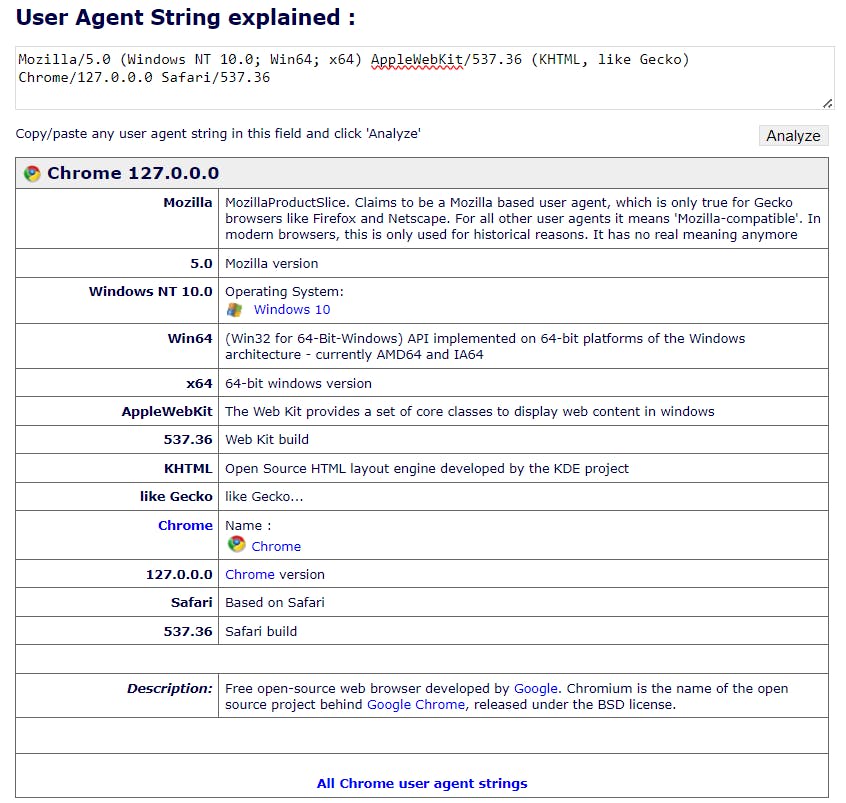
Here’s what the UA string set by Chrome looks like these days:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36
If you’re baffled by that string, you’re not alone. Why would a Chrome user agent contain words like “Mozilla” and “Safari”? 🤯
Well, there’s a bit of history behind that, but honestly, it's easier to just rely on an open-source project like UserAgentString.com. Just paste a user agent there, and you’ll get all the explanations you ever wondered about:

It all makes sense now, doesn’t it? ✅
Think of a user agent like a passport that you (the client) present at an airport (the server). Just as your passport tells the officer where you’re from and helps them decide whether to allow your entry, a user agent tells a site, “Hey, I'm Chrome on Windows, version X.Y.Z.” This little introduction helps the server determine how and if to handle the request.

While a passport holds personal information like your name, birth date, and place of birth, a user agent provides details about your requesting environment. Great, but what kind of information? 🤔
Well, it all depends on where the request is originating from:
- Browsers: The
User-Agentheader here is like a detailed dossier, packing in the browser name, operating system, architecture, and sometimes even specifics about the device.
- HTTP client libraries or desktop applications: The
User-Agentprovide just the basics, the library name, and occasionally the version.
Why Setting a User Agent Is Key in Web Scraping
Most sites have anti-bot and anti-scraping systems in place to safeguard their web pages and data. 🛡️
These protection technologies keep a sharp eye on incoming HTTP requests, sniffing out inconsistencies and bot-like patterns. When they catch one, they don’t hesitate to block the request and may even blacklist the IP address of the culprit for their malicious intentions.

User-Agent is one of the HTTP headers that these anti-bot systems scrutinize closely. After all, the string in that header helps the server understand whether a request is coming from a genuine browser with a well-known user agent string. No wonder User-Agent is one of the most important HTTP headers for web scraping. 🕵️♂️
The workaround to avoid blocks? Discover user agent spoofing!
By setting a fake UA string, you can make your automated scraping requests appear as coming from a human user in a regular browser. This technique is like presenting a fake ID to get past security.
Don’t forget that User-Agent is nothing more than an HTTP header. So, you can give it whatever value you want. Changing user agent for web scraping is an old that trick helps you dodge detection and blend in as a standard browser. 🥷
Wondering how to set a user agent in popular HTTP clients and browser automation libraries? Follow our guides:
- cURL User Agent Guide: Setting and Changing
- Python Requests User Agent Guide: Setting and Changing
- Selenium User Agent Guide: Setting and Changing
- Node.js User Agent Guide: Setting and Changing
- Postman User Agent Guide: Setting and Changing
Best User Agent for Scraping the Internet
Who’s the king of user agents when it comes to web scraping? 👑
Well, it’s not exactly a monarchy but more of an oligarchy. There isn’t one single user agent that stands head and shoulders above the rest. Actually, any UA string from modern browsers and devices is good to go. So, there’s not really a "best" user agent for scraping.

The user agents from the latest versions of Chrome, Firefox, Safari, Opera, Edge, and other popular browsers on macOS and Windows systems are all solid choices. The same goes for the UA of the latest versions of Chrome and Safari mobile on Android and iOS devices.
Here’s a handpicked list of user agents for scraping:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36
Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:129.0) Gecko/20100101 Firefox/129.0
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36
Mozilla/5.0 (iPhone; CPU iPhone OS 17_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) CriOS/127.0.6533.107 Mobile/15E148 Safari/604.1
Mozilla/5.0 (Macintosh; Intel Mac OS X 14.6; rv:129.0) Gecko/20100101 Firefox/129.0
Mozilla/5.0 (Macintosh; Intel Mac OS X 14_6_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.5 Safari/605.1.15
Mozilla/5.0 (Macintosh; Intel Mac OS X 14_6_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 OPR/112.0.0.0
Mozilla/5.0 (iPhone; CPU iPhone OS 17_6_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.5 Mobile/15E148 Safari/604.1
Mozilla/5.0 (Linux; Android 10; K) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.6533.103 Mobile Safari/537.36
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.2651.98
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 OPR/112.0.0.0
Of course, this is just the tip of the iceberg, and the list could go on and on. For a comprehensive and up-to-date list of user agents for scraping, check out sites like WhatIsMyBrowser.com and Useragents.me.
Learn more in our guide on user agents for web scraping.
Avoid Bans With User Agent Rotation
So, you’re thinking that just swapping your HTTP client library's default User-Agent with one from a browser might do the trick to dodge anti-bot systems? Well, not quite…
If you’re flooding a server with requests with the same User-Agent and from the same IP, you’re basically waving a flag that says, “Look at me, I’m a bot!” 🤖
To up your game and make it harder for those anti-bot defenses to catch on, you need to mix things up. That’s where user agent rotation comes in. Instead of using a static, real-world User-Agent, switch it up with each request.

This technique helps your requests blend in better with regular traffic and avoids getting flagged as automated.
Here are high-level instructions on how to rotate user agents:
-
Collect a list of user agents: Gather a set of UA strings from various browsers and devices.
-
Extract a random user-agent: Write simple logic to randomly pick a user agent string from the list.
-
Configure your client: Set the randomly selected user agent string in the
User-Agentheader of your HTTP client.
Now, worried about keeping your list of user agents fresh, unsure how to implement rotation, or concerned that advanced anti-bot solutions might still block you? 😩
Those are valid worries, especially since user agent rotation is just scratching the surface of avoiding bot detection.
Put your worries to rest with Bright Data’s Web Unlocker!
This AI-powered website unlocking API handles everything for you—user agent rotation, browser fingerprinting, CAPTCHA solving, IP rotation, retries, and even JavaScript rendering.
Final Thoughts
The User-Agent header reveals details about the software and system making an HTTP request. You now know what the best user agent for web scraping is and why rotating it is crucial. But let’s face it—user agent rotation alone won’t be enough against sophisticated bot protection.
Want to avoid getting blocked ever again? Embrace Web Unlocker from Bright Data and be part of our mission to make the Internet a public space accessible to everyone, everywhere—even through automated scripts!
Until next time, keep exploring the web with freedom!
如有侵权请联系:admin#unsafe.sh