2024-10-13 03:0:26 Author: hackernoon.com(查看原文) 阅读量:7 收藏
Quantity and variety of data fuel the rise of complex and sophisticated ML algorithms to handle AI workloads. These algorithms require GPUs to operate efficiently and process planet-scale datasets to recognize patterns. GPUs are very effective at delivering value and performance by handling complex computations, making their demand skyrocket in the ML/AI domain.
Despite their usefulness, GPUs are very expensive. Advanced AI/ML workloads require robust observability and management strategies instead of direct implementations to boost performance and durability while optimizing costs. Aggregating GPU-level metrics can help yield exceptional results, improving the AI/ML lifecycle.
Three Aggregatable GPU Metrics
Software workflows consist of multiple stages such as data loading, initialization, transformation, and data writing. The same stages apply to machine learning workloads with complex computations. Different parts of the GPU are used to fulfill the demand at every stage. It's important for engineering teams to know the allocation and utilization metrics for continuous training and deployments. This helps make informed decisions and leverage 100% of resources for maximum value extraction.
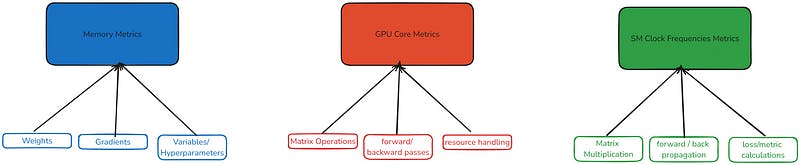
From a machine learning standpoint, the following GPU components are utilized for workflow stages when model training is initiated. We will understand the GPU components and metrics they expose. Finally, we will learn how to capture and leverage them from the Prometheus alertmanager to improve the overall ML lifecycle.

- GPU Memory: Data and ML pipelines heavily rely on memory. For big data processing, the data is computed in memory for faster results. The model weights, gradients, and other hyperparameters/variables are loaded in GPU memory. Keeping track of memory utilization can help scale and boost the model's training speed.
- GPU Cores: When models perform matrix-intensive operations and apply forward/backward passes, GPU cores will handle these operations. The tensor core activity metrics help determine how well the hardware units are utilized and have room for improvement.
- SM Clock Frequencies: The operations running on the GPU cores require streaming multiprocessors (SM) to perform desired mathematical computations. The clock frequencies can help determine the computational speed.
Capturing GPU Metrics
Running bash scripts directly on the GPU doesn't offer Python's flexibility. We can query and analyze GPU metrics throughout the training process to understand the behavior. By leveraging these metrics, we can set up alerts and remediations to handle critical scenarios.
Considering flexibility and extensibility, we will set up Prometheus to scrape and trigger alerts based on threshold and use Python to scrape and log GPU metrics.
1. Memory Metrics
Assuming the GPU is NVIDIA and the NVIDIA DCGM Exporter setup is complete on your GPU. We will define Prometheus config to monitor and scrape metrics based on the threshold and trigger slack notification if the threshold exceeds.
Targeting the GPU provisioned in a VPC under subnet 172.28.61.90 and exposed on port 9400 through Prometheus configs.
configs_scrapper:
- job_name: 'nvidia_gpu_metrics_scrapper'
static_configs:
- targets: ['172.28.61.90:9400']
With the target defined, we can derive the expression to check the memory usage every two minutes. When the threshold exceeds 80%, a critical alert is triggered.
groups:
-name: GPU_Memory_Alerts
rules:
- alert: HighGPUMemoryUsage
expr: (dcgm_gpu_mem_used / dcgm_gpu_mem_total) * 100 > 80
for: 2m
labels:
severity: critical
annotations:summary: "GPU Memory usage is high on {{ $labels.instance }}"
description: "GPU memory utilization is over 80% from more than 2 minutes on {{ $labels.instance }}."
The metrics can then be sent over as alerts. Slack has the easiest integration options for setting up alerts. So, using the below YAML config, we can enable alerting to groups or individual usernames in Slack.
global:
resolve_timeout: 2m
route:
receiver: 'slack_memory_notifications'
group_wait: 5s
group_interval: 2m
repeat_interval: 1h
receivers:
- name: 'slack_memory_notifications'
slack_configs:
- api_url: 'https://databracket.slack.com/services/shrad/webhook/url'
channel: 'databracket'
username: 'Prometheus_Alertmanager'
send_resolved: true
title: 'GPU Memory Utilization >80% Alert'
text: "A high memory utilization was observed triggering alert on GPU."
Monitoring and alerting are useful and offer limited benefits, like notifying us when something is wrong. We need to capture the metrics for analysis and make informed decisions.
For this scenario, we will consider DuckDB for data management and boto3 for AWS S3 manipulation. Using the Nvidia management library (pynvml), we can access and manage the GPU through code. We will write the metrics to S3 as parquet files. For persistence, we will write the logs to an in-memory database using DuckDB and write a snapshot of the data to S3 for ad hoc or real-time analysis.
import time
import pynvml
import duckdb
import boto3
import osfrom datetime import datetime
pynvml.nvmlInit()
s3 = boto3.client('s3')
con = duckdb.connect(database=':memory:')
con.execute('''
CREATE TABLE gpu_memory_usage (
Timestamp VARCHAR,
Overall_memory DOUBLE,
Memory_in_use DOUBLE,
Available_memory DOUBLE
)
''')
def get_gpu_memory_info(gpu_id=0):
handle = pynvml.nvmlDeviceGetHandleByIndex(gpu_id)
memory_info = pynvml.nvmlDeviceGetMemoryInfo(handle)
return {
"Overall_memory": memory_info.total / (1024 ** 2),
"Memory_in_use": memory_info.used / (1024 ** 2),
"Available_memory": memory_info.free / (1024 ** 2)
}
def upload_parquet_to_s3(bucket_name, object_name, file_path):
try:
s3.upload_file(file_path, bucket_name, object_name)
print(f"Parquet file uploaded to S3: {object_name}")
except Exception as e:
print(f"Failed to upload Parquet to S3: {e}")
def log_memory_utilization_to_parquet(bucket_name, filename, gpu_id=0, interval=1.0, local_file_path='gpu_memory_stats.parquet'):
try:
while True:
gpu_memory_info = get_gpu_memory_info(gpu_id)
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
con.execute('''
INSERT INTO gpu_memory_usage VALUES (?, ?, ?, ?)
''', (timestamp, gpu_memory_info['Overall_memory'], gpu_memory_info['Memory_in_use'], gpu_memory_info['Available_memory']))
print(f"Logged at {timestamp}: {gpu_memory_info}")
if int(datetime.now().strftime('%S')) %60 == 0: # Upload Every Minute
object_name = f"{filename}_{datetime.now().strftime('%Y%m%d_%H%M%S')}.parquet"
upload_parquet_to_s3(bucket_name, object_name, local_file_path)
time.sleep(interval)
except KeyboardInterrupt:
print("Logging stopped by user.")
bucket_name = 'prometheus-alerts-cof'
filename = 'gpu_memory_stats'
log_memory_utilization_to_parquet(bucket_name, filename, gpu_id=0, interval=2.0)
2. GPU Core Metrics
GPUs are famous for their tensor cores. These are hardware units that can process multi-dimensional data. It is crucial to understand how the cores are distributing or processing the loads and when they hit the threshold. We can implement auto-scaling rules through these alerts to handle workloads and avoid overheating or crashes.
Similar to memory monitoring, we will set up configurations to monitor and capture GPU core utilization metrics. For every minute, when the core utilization exceeds 80%, a critical alert will be sent, and for moderate utilization, a status update will be sent every five minutes.
groups:
- name: gpu_alerts
rules:
- alert: HighGPUCoreUtilization
expr: gpu_core_utilization > 80
for: 1m
labels:
severity: critical
annotations:
summary: "GPU Core Utilization >80% Alert"
description: "GPU core utilization is above 80% for over 1 minute."
- alert: MediumGPUCoreUtilization
expr: gpu_core_utilization > 50
for: 5m
labels:
severity: warning
annotations:
summary: "GPU Memory Utilization = Moderate"
description: "GPU core utilization is above 50% for over 5 minutes."
Here, we will get the device handle index and call a method that returns utilization rates. The response is then logged into the in-memory DuckDB database and put into the s3 bucket with the processed timestamp.
con.execute('''
CREATE TABLE gpu_core_usage (
Timestamp VARCHAR,
GPU_Utilization_Percentage DOUBLE
)
''')
def get_gpu_utilization(gpu_id=0):
"""Returns the GPU utilization percentage."""
handle = pynvml.nvmlDeviceGetHandleByIndex(gpu_id)
utilization = pynvml.nvmlDeviceGetUtilizationRates(handle)
return utilization.gpu
def log_gpu_utilization_to_parquet(bucket_name, filename, gpu_id=0, interval=1.0, local_file_path='gpu_core_stats.parquet'):
"""Logs GPU utilization to a Parquet file and uploads it to S3 periodically."""
try:
while True:
gpu_utilization = get_gpu_utilization(gpu_id)
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
con.execute('''
INSERT INTO gpu_core_usage VALUES (?, ?)
''', (timestamp, gpu_utilization))
print(f"Logged at {timestamp}: GPU Utilization = {gpu_utilization}%")
if int(datetime.now().strftime('%S')) % 60 == 0:
con.execute(f"COPY gpu_core_usage TO '{local_file_path}' (FORMAT PARQUET)")
object_name = f"{filename}_{datetime.now().strftime('%Y%m%d_%H%M%S')}.parquet"
upload_parquet_to_s3(bucket_name, object_name, local_file_path)
con.execute("DELETE FROM gpu_core_usage")
time.sleep(interval)
except KeyboardInterrupt:
print("Logging stopped by user.")
# Example usage:
bucket_name = 'prometheus-alerts-cof'
filename = 'gpu_core_stats'
log_gpu_utilization_to_parquet(bucket_name, filename, gpu_id=0, interval=2.0)
3. SM Clock Frequency Metrics
The speed at which the computations happen is directly proportional to the streaming multiprocessor clock frequency. The SM clock frequency metric helps determine the speed at which the tensor or ML computations are triggering and completing.
We can enable Prometheus to trigger alerts when the SM clock frequency exceeds 2000MHz. We can set up warning alerts to get notified when the frequency is nearing the limit.
groups:
- name: gpu_sm_clock_alerts
rules:
- alert: LowSMClockFrequency
expr: gpu_sm_clock_frequency >= 1000
for: 1m
labels:
severity: warning
annotations:
summary: "Low SM Clock Frequency"
description: "The SM clock frequency is below 500 MHz for over 1 minute."
- alert: HighSMClockFrequency
expr: gpu_sm_clock_frequency > 2000
for: 1m
labels:
severity: critical
annotations:
summary: "High SM Clock Frequency"
description: "The SM clock frequency is above 2000 MHz for over 1 minute."
The accumulation of SM clock metrics can easily be scripted to log the metrics in in-memory data and S3.
con.execute('''
CREATE TABLE sm_clock_usage (
Timestamp VARCHAR,
SM_Clock_Frequency_MHz INT
)
''')
def get_sm_clock_frequency(gpu_id=0):
handle = pynvml.nvmlDeviceGetHandleByIndex(gpu_id)
sm_clock = pynvml.nvmlDeviceGetClockInfo(handle, pynvml.NVML_CLOCK_SM)
return sm_clock
def log_sm_clock_to_parquet(bucket_name, filename, gpu_id=0, interval=1.0, local_file_path='sm_clock_stats.parquet'):
try:
while True:
sm_clock_frequency = get_sm_clock_frequency(gpu_id)
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
con.execute('''
INSERT INTO sm_clock_usage VALUES (?, ?)
''', (timestamp, sm_clock_frequency))
print(f"Logged at {timestamp}: SM Clock Frequency = {sm_clock_frequency} MHz")
if int(datetime.now().strftime('%S')) % 10 == 0:
con.execute(f"COPY sm_clock_usage TO '{local_file_path}' (FORMAT PARQUET)")
object_name = f"{filename}_{datetime.now().strftime('%Y%m%d_%H%M%S')}.parquet"
upload_parquet_to_s3(bucket_name, object_name, local_file_path)
con.execute("DELETE FROM sm_clock_usage")
time.sleep(interval)
except KeyboardInterrupt:
print("Logging stopped by user.")
bucket_name = 'prometheus-alerts-cof'
filename = 'sm_clock_stats'
log_sm_clock_to_parquet(bucket_name, filename, gpu_id=0, interval=2.0)
By leveraging these metrics ML engineers can know what is happening under the hood. They can improve the training process by analyzing the metrics and setting up remediations for high criticality and priority alerts.
Final Thoughts
Machine learning model training is a complex and convoluted process. Just like without sound evidence and stats, it is difficult to conclude which model variants exhibit predictions with high inference. We need GPU metrics to understand how the compute instance responsible for handling and processing the ML workloads is operating. With enough metrics and real-time alerts, ML teams can set up and streamline robust and durable ML pipelines that improve the overall ML lifecycle.
如有侵权请联系:admin#unsafe.sh