0x01 简介
Tomcat是常见的Web中间件,实际上是利用NIO技术处理HTTP请求,在接收到请求时会对客户端提交的参数、URL、Header和Body数据进行解析,并生成Request对象,然后调用实际的JSP或Servlet。
当后台程序使用getRequestURI()或getRequestURL()函数来解析用户请求的URL时,若URL中包含了一些特殊符号,则可能会造成访问限制绕过的安全风险。
0x02 URL解析差异性
HttpServletRequest中几个解析URL的函数
在Servlet处理URL请求的路径时,HTTPServletRequest有如下几个常用的函数:
- request.getRequestURL():返回全路径;
- request.getRequestURI():返回除去Host(域名或IP)部分的路径;
- request.getContextPath():返回工程名部分,如果工程映射为
/,则返回为空; - request.getServletPath():返回除去Host和工程名部分的路径;
- request.getPathInfo():仅返回传递到Servlet的路径,如果没有传递额外的路径信息,则此返回Null;
网上的一个小结,Servlet的匹配路径为/test%3F/*,并且Web应用是部署在/app下,此时请求的URL为http://30thh.loc:8480/app/test%3F/a%3F+b;jsessionid=s%3F+ID?p+1=c+d&p+2=e+f#a,各个函数解析如下表:
| 函数 | URL解码 | 解析结构 |
|---|---|---|
| getRequestURL() | no | http://30thh.loc:8480/app/test%3F/a%3F+b;jsessionid=s%3F+ID |
| getRequestURI() | no | /app/test%3F/a%3F+b;jsessionid=s%3F+ID |
| getContextPath() | no | /app |
| getServletPath() | yes | /test? |
| getPathInfo() | yes | /a?+b |
特殊字符的URL解析
新建一个Java Web项目,index.jsp如下:
<% out.println("getRequestURL(): " + request.getRequestURL() + "<br>"); out.println("getRequestURI(): " + request.getRequestURI() + "<br>"); out.println("getContextPath(): " + request.getContextPath() + "<br>"); out.println("getServletPath(): " + request.getServletPath() + "<br>"); out.println("getPathInfo(): " + request.getPathInfo() + "<br>"); %>
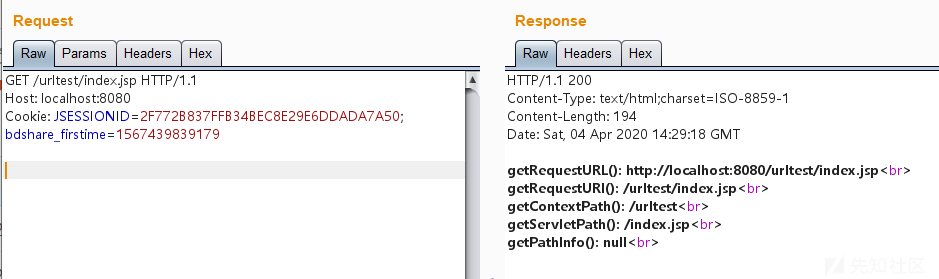
正常访问
Tomcat运行之后,正常访问http://localhost:8080/urltest/index.jsp,页面输出如下:

插入 ./ 访问
尝试插入多个./访问即http://localhost:8080/urltest/./././index.jsp,页面输出如下:
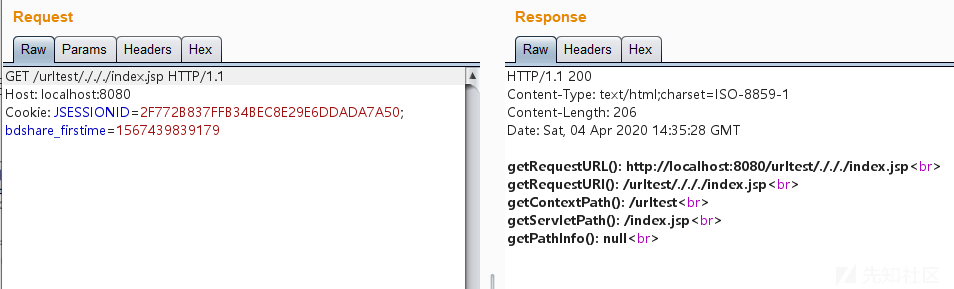
可以看到,插入多个./也能正常访问。
接着尝试这种形式http://localhost:8080/urltest/.a/.bb/.ccc/index.jsp,发现是返回404,未找到该资源访问:

插入 ../ 访问
尝试插入../访问即http://localhost:8080/urltest/../index.jsp,页面输出如下:
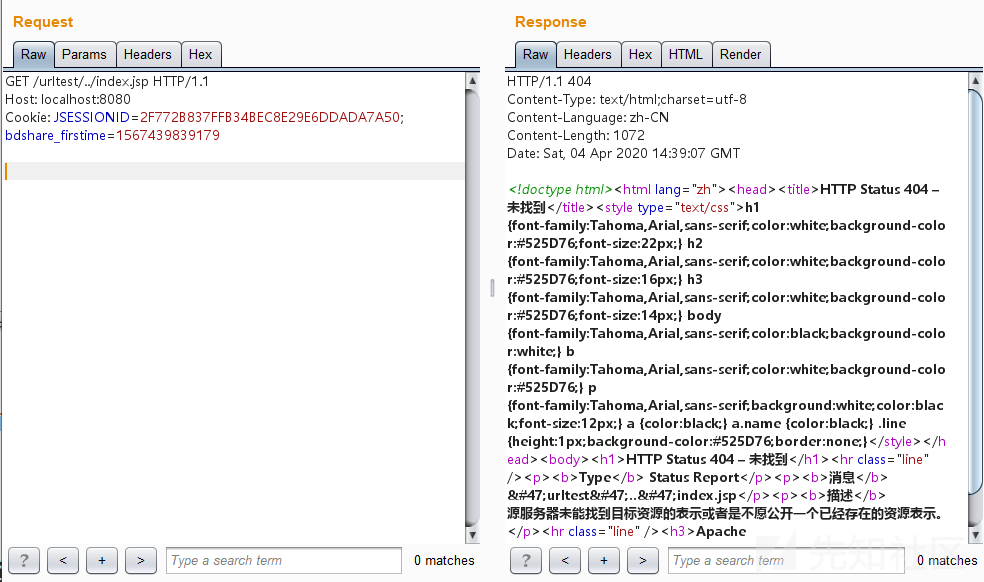
可以是返回的404,这是因为实际访问的是http://localhost:8080/index.jsp,这个目录文件当然不存在。
换种跨目录的形式就OK了http://localhost:8080/urltest/noexist/../index.jsp:

插入 ;/ 访问
尝试插入多个;/访问即http://localhost:8080/urltest/;/;/;/index.jsp,页面输出如下:
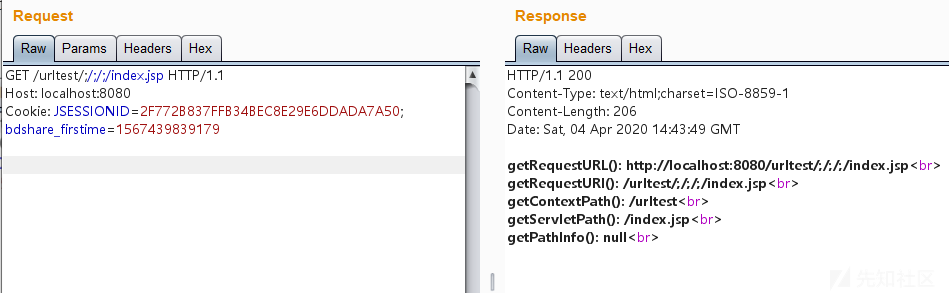
可以看到,插入多个;也能正常访问。
在;号后面加上字符串也是能正常访问的,如http://localhost:8080/urltest/;a/;bb/;ccc/index.jsp:
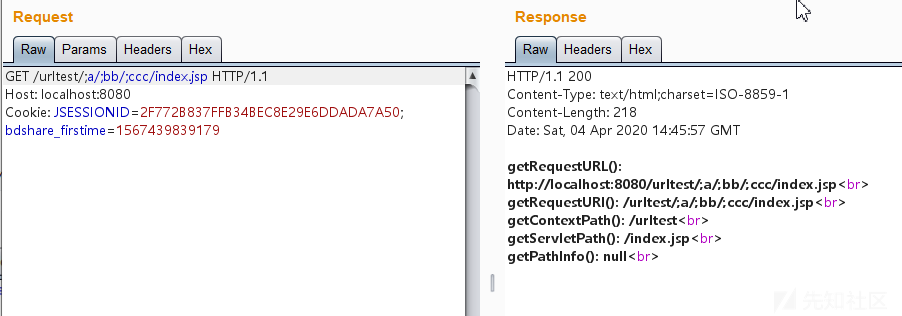
插入其他特殊字符访问
尝试插入如下这些特殊字符进行访问,页面均返回400或404,无法访问:
` ~ ! @ # $ % ^ & * ( ) - _ = + [ ] { } \ | : ' " < > ?小结
由前面的尝试知道,Tomcat中的URL解析是支持嵌入./、../、;xx/等特殊字符的。此外,getRequestURL()和getRequestURI()这两个函数解析提取的URL内容是包含我们嵌入的特殊字符的,当使用不当时会存在安全问题如绕过认证。
0x03 调试分析
Tomcat会先对请求的URL进行解析处理,提取到一些信息之后才会到调用getRequestURI()等函数的流程。
Tomcat对URL特殊字符的处理
这里我们先来调试分析下Tomcat是如何对请求URL中不同的特殊字符作不同的处理的。
经过调试分析,得知Tomcat是在CoyoteAdapter.service()函数上对请求URL进行解析处理的,直接在这里打上断点,此时的函数调用栈如下:
service:452, CoyoteAdapter (org.apache.catalina.connector)
process:1195, AbstractHttp11Processor (org.apache.coyote.http11)
process:654, AbstractProtocol$AbstractConnectionHandler (org.apache.coyote)
run:317, JIoEndpoint$SocketProcessor (org.apache.tomcat.util.net)
runWorker:1142, ThreadPoolExecutor (java.util.concurrent)
run:617, ThreadPoolExecutor$Worker (java.util.concurrent)
run:61, TaskThread$WrappingRunnable (org.apache.tomcat.util.threads)
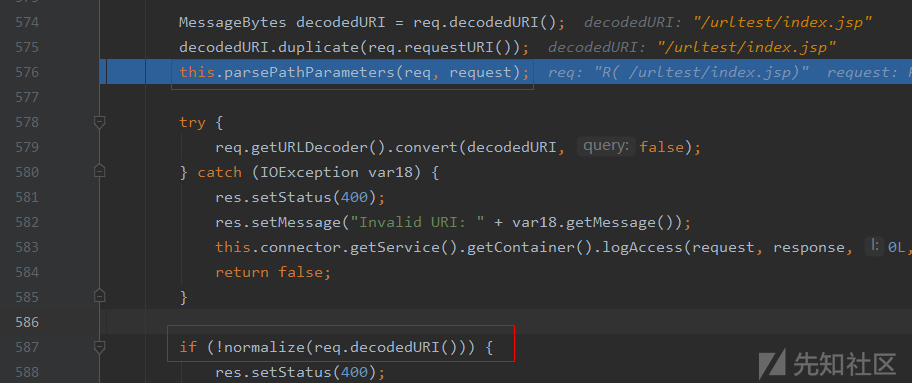
run:745, Thread (java.lang)在CoyoteAdapter.service()函数中,会调用postParseRequest()函数来解析URL请求内容:

跟进postParseRequest()函数中,其中先后调用parsePathParameters()和normalize()函数对请求内容进行解析处理:
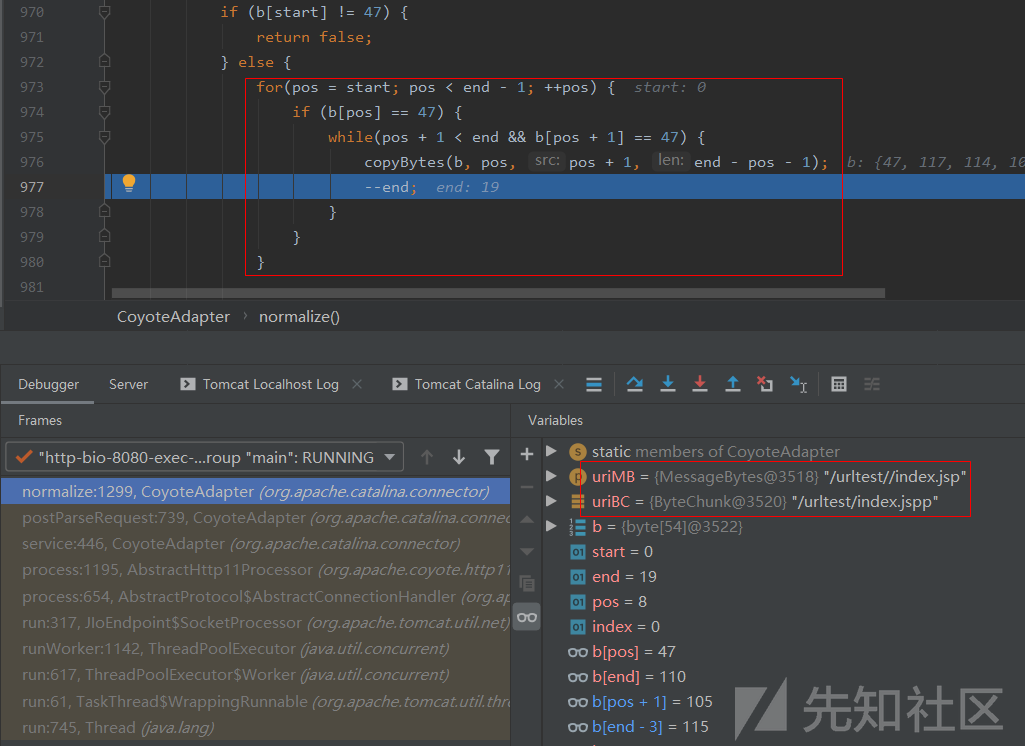
这里我们先跟进parsePathParameters()函数,先是寻找URL中是否存在;号,找到的话才会进入下面的if代码逻辑:

如果找到了;号,在if代码逻辑中后面的循环体会将;xxx/中的分号与斜杠之间的字符串以及分号本身都去掉,我们访问http://localhost:8080/urltest/;mi1k7ea/index.jsp再试下,就可以进入该代码逻辑调试看到(代码中ASCII码59是;,47是/):

由此可知,parsePathParameters()函数是对;xxx/这种形式进行处理的。
接着,跟进normalize()函数,该函数是对经过parsePathParameters()函数处理过后的请求URL进行标准化处理。
先看到这段代码,ASCII码92表示\,当匹配到时将其替换为ASCII码为47的/;当匹配到ASCII码0即空字符时,直接返回false无法成功解析:

往下是这段循环,判断是否有连续的/,存在的话则循环删除掉多余的/:
接着往下看,这段循环就是对./和../这些特殊字符进行处理,如果这两个字符串都找不到则直接返回true:
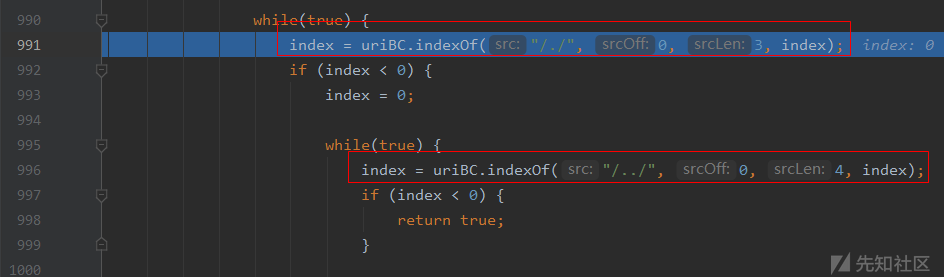
这里尝试下添加/./访问的处理,看到找到之后是直接将其去掉然后继续放行:

这里尝试下添加/../访问的处理,看到找到后是会进行往前目录层级的回溯处理再拼接到上面某一层目录形成新的URL:
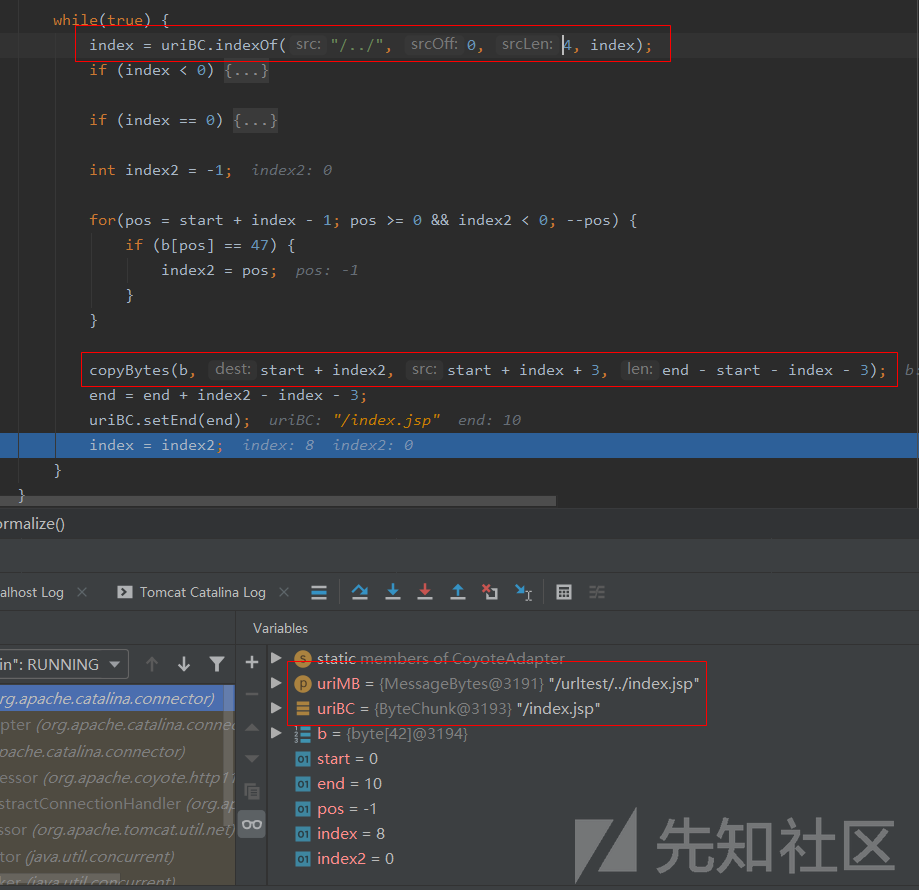
由此可知,normalize()函数对经过经过parsePathParameters()函数过滤过;xxx/的URL请求内容进标准化处理,具体为将连续的多个/给删除掉只保留一个、将/./删除掉、将/../进行跨目录拼接处理,最后返回处理后的URL路径。
结论
Tomcat对/;xxx/以及/./的处理是包容的、对/../会进行跨目录拼接处理。
getRequestURI()的处理
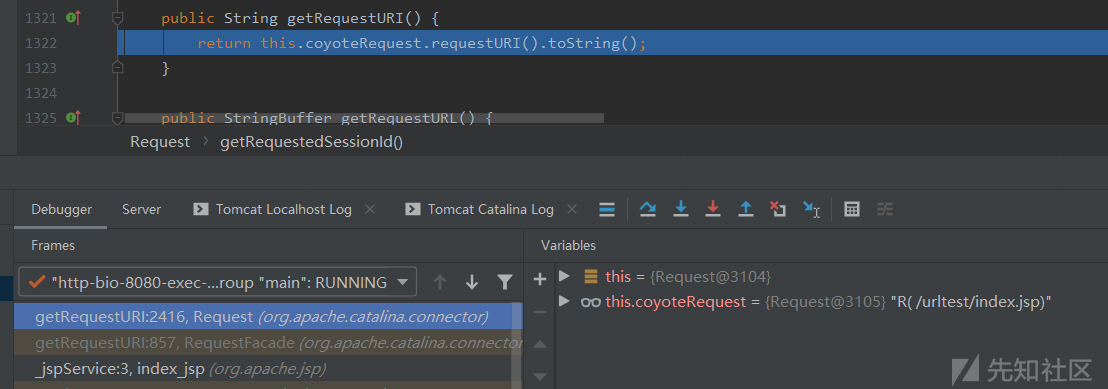
我们直接在index.jsp中调用getRequestURI()函数的地方打上断点调试即可。
这里是直接调用Request.requestURI()函数然后直接返回其字符串值:
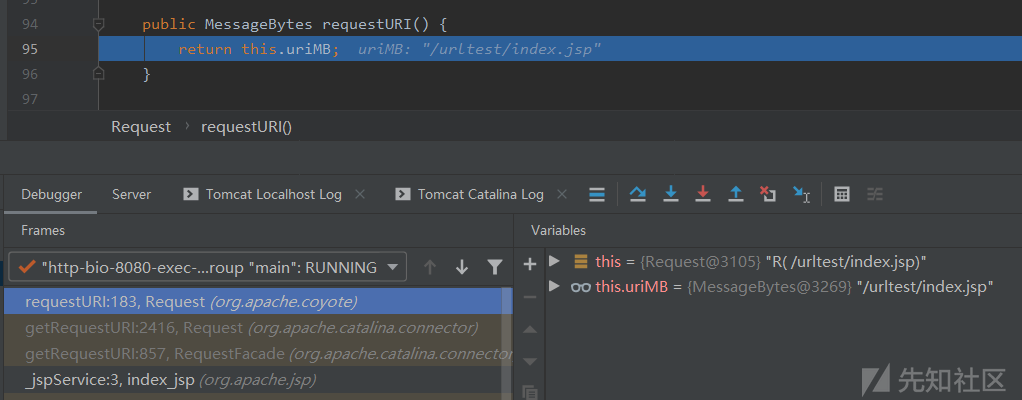
跟进Request.requestURI()函数,这里是直接返回请求的URL内容,没有做任何处理以及URL解码:
getRequestURL()的处理
在getRequestURL()函数中是调用了Request.getRequestURL()函数的:

跟进该函数,在提取了协议类型、host和port之后,调用了getRequestURI()函数获取URL请求的路径,然后直接拼接进URL直接返回而不做包括URL解码的任何处理:

getServletPath()的处理
在getServletPath()函数中是调用了Request.getServletPath()函数的:

跟进去,看到是直接返回前面Tomcat已经处理过后的提取处理的Servlet路径,注意这里是获取MappingData类对象中的wrapperPath属性值:
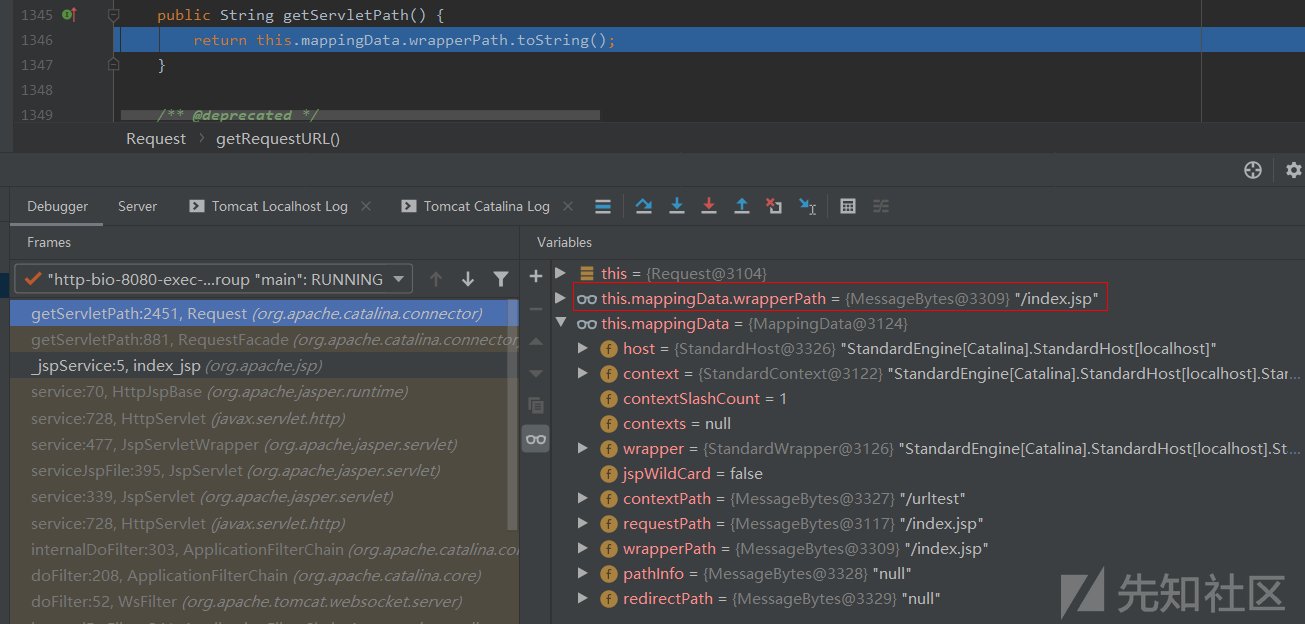
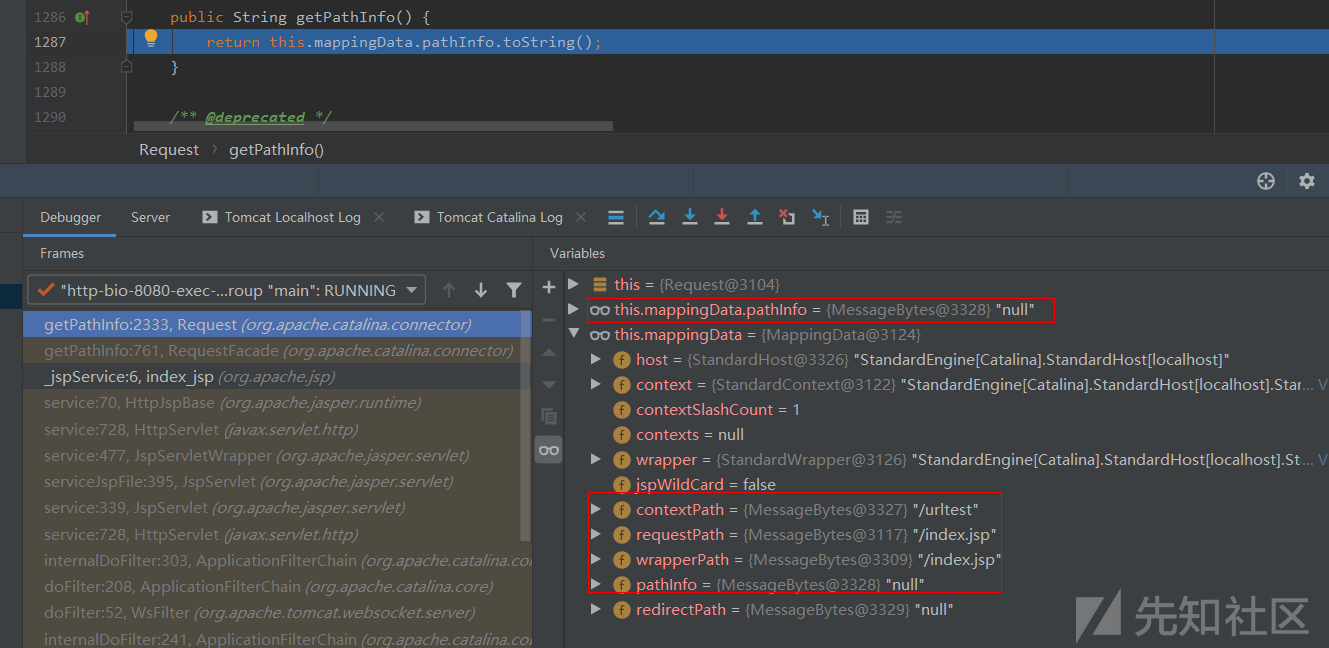
getPathInfo()的处理
和getServletPath()函数的处理是一样的,同样是返回前面经过Tomcat解析处理后的MappingData类对象中其中一个属性值,这里是获取的pathInfo属性值并直接返回:
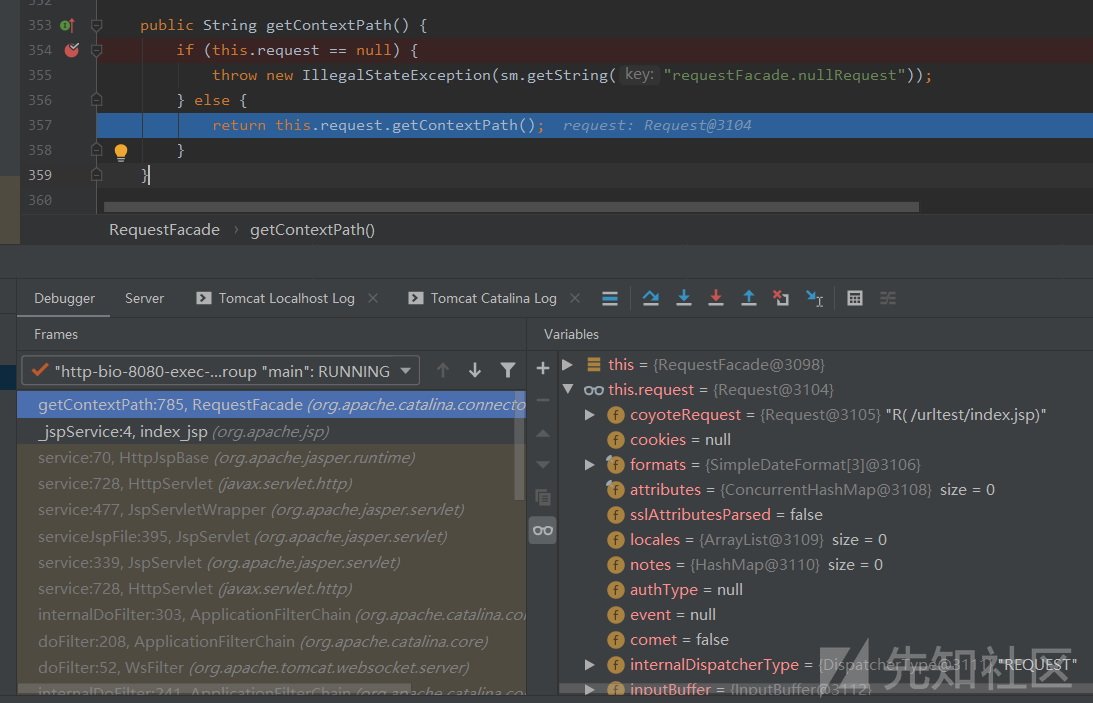
getContextPath()的处理
在getContextPath()函数中,调用了Request.getContextPath()函数:
跟进该函数,先是调用getServletContext().getContextPath()来获取当前Servlet上下文路径以及调用getRequestURI()函数获取当前请求的目录路径:

往下的这段循环是处理uri变量值中如果存在多个连续的/则删除掉:
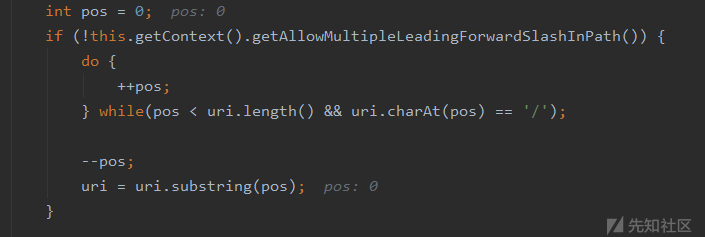
再往下,获取下一个/符号的位置,然后根据该位置索引对uri变量值进行工程名的切分提取:

接着,就是对刚刚切分得到的candidate变量进行和Tomcat一样的特殊字符处理过程,先调用removePathParameters()处理;和.,然后进行URL解码,再调用normalize()函数进行标准化处理,处理过后比较处理完的candidate变量值和之前获取的规范上下文路径是否一致,不一致的话就循环继续前面的操作直至一致为止:

最后,直接返回按pos索引切分的uri变量值:

0x04 攻击利用
看个访问限制绕过的场景。
假设Tomcat上启动的Web目录下存在一个info目录,其中有一个secret.jsp文件,其中包含敏感信息等:
<%@ page contentType="text/html;charset=UTF-8" language="java" %> <html> <head> <title>Secret</title> </head> <body> username: mi1k7ea<br> password: 123456<br> address: china<br> phone: 13666666666<br> </body> </html>
新建一个filter包,其中新建一个testFilter类,实现Filter接口类:
package filter; import javax.servlet.*; import javax.servlet.http.*; import java.io.IOException; public class testFilter implements Filter { @Override public void init(FilterConfig filterConfig) throws ServletException { } @Override public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException { HttpServletRequest httpServletRequest = (HttpServletRequest)servletRequest; HttpServletResponse httpServletResponse = (HttpServletResponse)servletResponse; String url = httpServletRequest.getRequestURI(); if (url.startsWith("/urltest/info")) { httpServletResponse.getWriter().write("No Permission."); return; } filterChain.doFilter(servletRequest, servletResponse); } @Override public void destroy() { } }
这个Filter作用是:只要访问/urltest/info目录下的资源,都需要进行权限判断,否则直接放行。可以看到,这里调用getRequestURI()函数来获取请求中的URL目录路径,然后调用startsWith()函数判断是否是访问的敏感目录,若是则返回无权限的响应。当然这里写得非常简单,只做演示用。
编辑web.xml,添加testFilter设置:
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" version="4.0"> <filter> <filter-name>testFilter</filter-name> <filter-class>filter.testFilter</filter-class> </filter> <filter-mapping> <filter-name>testFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> </web-app>
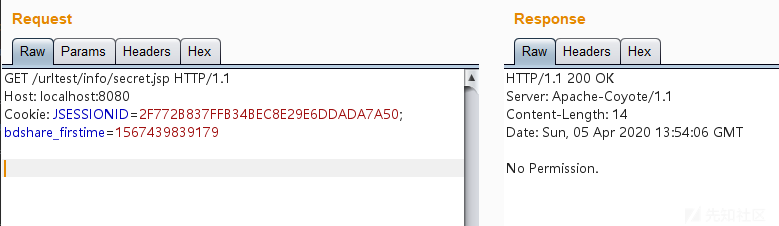
运行之后,访问http://localhost:8080/urltest/info/secret.jsp,会显示无权限:
根据前面的分析构造如下几个payload都能成功绕过认证限制来访问:
http://localhost:8080/urltest/./info/secret.jsp
http://localhost:8080/urltest/;mi1k7ea/info/secret.jsp
http://localhost:8080/urltest/mi1k7ea/../info/secret.jsp
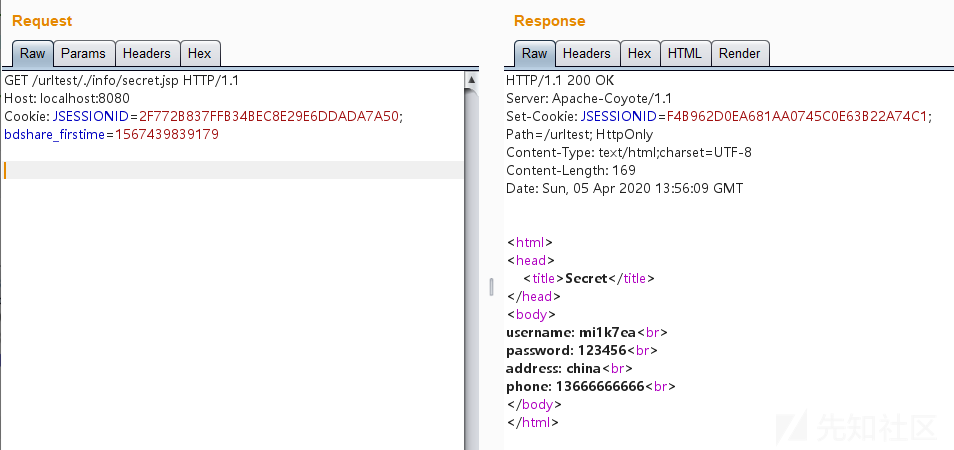
整个的过程大致如此,就是利用解析的差异性来绕过认证。
在前段时间爆出的Apache Shiro的CVE中,就是使用getRequestURI()函数导致的,这里可以看到人家的补丁是怎么打的,其实就是用getPathInfo()替换掉就OK了:https://github.com/apache/shiro/commit/3708d7907016bf2fa12691dff6ff0def1249b8ce
0x05 参考
如有侵权请联系:admin#unsafe.sh